How data is collected
How engine.pm gathers data
When gathering data from your VMware environment, engine.pm connects to each VC machine and ESX/i host that you want to monitor and gathers different types of data from each. How data is collected for ESX/i hosts depends on whether the host is managed (under vCenter Server) or unmanaged (runs independently of vCenter).
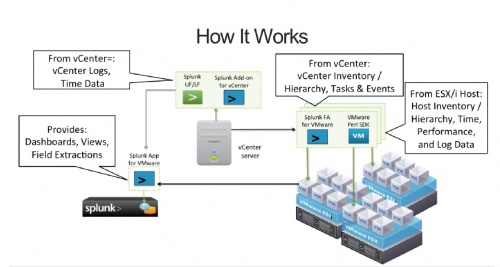

Splunk for VMware collects data from vCenter and the ESX/i hosts and maps the data to the dashboards and views in the the Splunk App for VMware. Using the Splunk App for VMware you can explore your data and deep dive into specific areas.
Data sets collected for managed resources
vCenter and managed ESX/i hosts
| Data Type | Dataset Description |
|---|---|
| Hierarchy | engine.pm gets the entire hierarchy dataset. |
| inventory | engine.pm gets the entire inventory dataset. |
| Performance | engine.pm gets performance data for VC-specific objects (objects not seen in each ESX/i host). This includes the managed entity ClusterComputeResource. |
| Tasks | engine.pm gets the entire task dataset. |
| Events | engine.pm gets the entire events dataset. |
Managed ESX/i hosts
| Data Type | Dataset Description |
|---|---|
| Hierarchy | In addition to getting data from VC, it is also important to get the entire hierarchy dataset from each ESX/i host. Getting data from both enables “moid mapping” to occur. |
| Performance | engine.pm gets the entire performance dataset. |
| Logs | engine.pm gets the entire log dataset. |
Data sets collected for unmanaged ESX/i hosts
| Data Type | Dataset Description |
|---|---|
| Hierarchy | Collect the entire hierarchy dataset from each ESX/i host. Getting data from vCenter and the ESX/i hosts enables “moid mapping” to occur. |
| Performance | engine.pm gets the entire performance dataset. |
| Logs | engine.pm gets the entire log dataset. |
| Inventory | engine.pm gets the entire inventory dataset. |
| Tasks | engine.pm gets the entire task dataset. |
engine.pm
engine.pm is the main data collection module inside the Forwarder Appliance Add-on. It is located in:
$SPLUNK_HOME/etc/apps/splunk_for_vmware_appliance/bin
It executes data discovery modules according to the specifications defined in engine.conf. engine.pm looks for a file named engine.conf by default in the splunk_for_vmware_appliance/local directory. Alternatively, you can specify a different configuration file name on the command line. Multiple engine.pm processes can run concurrently.
The engine.conf.spec file
The engine.conf.spec file documents the settings and values you can use in the engine.conf file. It is a reference document and is located in $SPLUNK_HOME/etc/apps/splunk_for_vmware_appliance/default in the Forwarder Appliance (FA VM):
Learn more
- To learn more about the settings used in
engine.conf, see "engine.conf settings" in this manual. - For a description of the actions used in
engine.conf, see "action definition" in this manual. - See "What data can I get" to learn more about how engine.pm collects data.
|
PREVIOUS What data can I get |
NEXT The data collection components |
This documentation applies to the following versions of Splunk® App for VMware (Legacy): 1.0, 1.0.1, 1.0.2, 1.0.3, 2.0
Feedback submitted, thanks!