Splunk Success Framework
Get ready to implement Splunk like a pro with the Splunk Success Framework (SSF)! Using the SSF helps you and your team unlock the full potential of your data, increase the value you get from Splunk, and help you to scale your deployment flexibly as you grow.
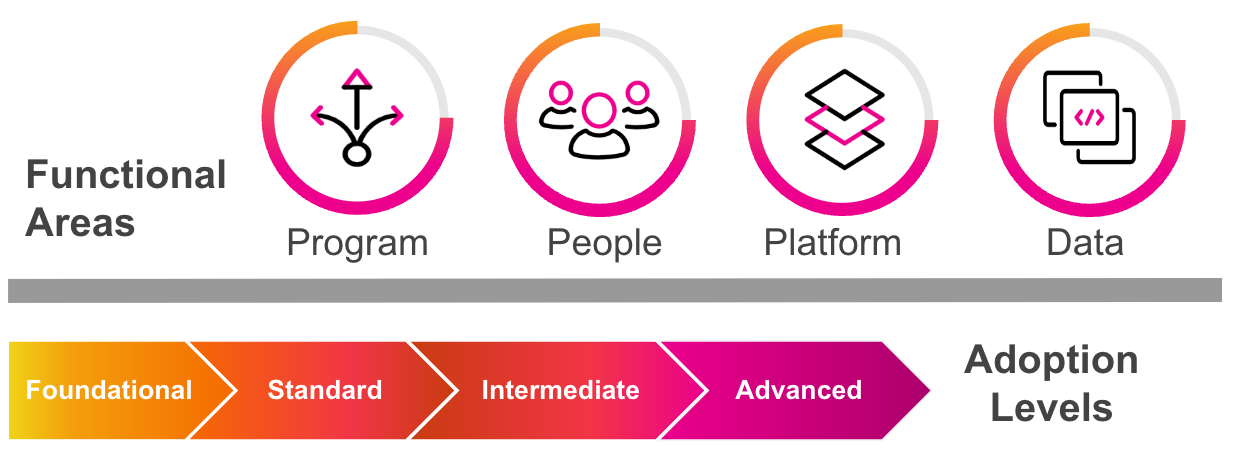
The SSF contains guidance from Splunk experts on the best ways to implement Splunk. Whether you have Splunk Cloud Platform or an on-premises Splunk Enterprise deployment, the SSF contains best practices that you can use to create and maintain a smoothly-running Splunk implementation.
If you're new to the SSF, we recommend you begin by exploring the Fundamentals to understand the basic elements we recommend that you have in place to ensure success from the start.
Or, you can jump through to the guidance within each of the functional areas below by clicking through each tab.
.png?revision=1)