Configure alerts in the Content Pack for ITSI Monitoring and Alerting
You can configure alerts for the Content Pack for ITSI Monitoring and Alerting to send a notification to the accountable group through email or an external ticketing system. After you enable one or more Episode Monitoring correlation searches, ITSI continuously monitors newly created episodes. When an episode meets the alert criteria for that correlation search, ITSI generates a notable event and the corresponding action executes in accordance with the action rule in the notable event aggregation policy.
The following methods are the most common ways to engage the correct people for a given episode:
- Send an incident event to Splunk On-Call (formerly VictorOps) or another incident management system.
- Send an email to a person, a distribution list, or a shared inbox.
- Create a ticket in ServiceNow, Remedy, Cherwell, or another external ticketing system.
The exception is the correlation search Episode Monitoring - Set Episode to Highest Alarm Severity, which performs a meta function across all episodes. It continually adjusts Episode severity to match the highest Event Type "swim lane" alarm severity, and closes the episode after all swim lanes/alarms have cleared. All "Episodes by" Aggregation Policies are pre-configured to work with Episode Monitoring - Set Episode to Highest Alarm Severity and no further modification is required.
Review the content pack default alert action
Each "Episodes by" aggregation policy in this content pack adds a comment to an episode when a notable event from an episode monitoring rule is added to the episode. This action primarily exists to demonstrate how to configure aggregation policies to take action automatically when an Episode Monitoring correlation search detects an alert condition. You can keep, remove, or configure this action as necessary depending on your environment.

By default, the comment is applied for any non-normal Episode Monitoring notable event, excluding notable events from the Episode Monitoring - Set Episode to Highest Alarm Severity correlation search. This configuration ensures that the action will execute when any enabled Episode Monitoring alert observes abnormal conditions for the episode. This default configuration is likely consistent with the conditions under which you would want to execute other proactive alerting actions.
Prerequisites
Before you configure alerting, you must first install and configure the Content Pack for ITSI Monitoring and Alerting and enable the appropriate correlation searches. For instructions, see Install and configure the Content Pack for ITSI Monitoring and Alerting.
Example: Route alerts to a tier 1 or operations center team
In some organizations, a single team receives and triages all alerts and manually engages the appropriate stakeholders. When routing alerts to a tier 1 team, it's a best practice to enable and configure alert actions for only one aggregation policy. If you configure alerts for multiple policies, ITSI generates multiple alerts for the same episode.
To route alerts to a single team with one aggregation policy, perform the following steps:
- Open the aggregation policy you want to use for alerting. For more information about the aggregation policies included in this content pack, see Manage the aggregation policies in the Content Pack for ITSI Monitoring and Alerting.
- Go to the Action Rules tab.
- Expand the content pack default alert action rule.
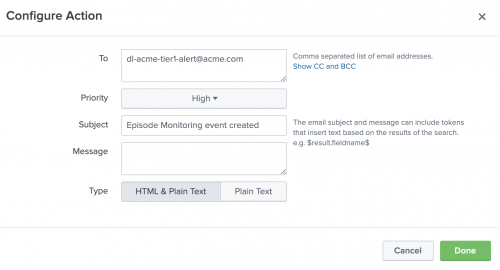
- Click + and and add a second action in the same panel to send an email to the tier 1 team. The following example sends an email to the distribution list for Acme's tier 1 operations team:

Example: Route alerts directly to accountable groups
Routing alerts directly to the accountable group requires additional configuration to determine the appropriate group based on attributes of the episode. While you can enhance the configuration to be as granular and dynamic as needed, the following example is a simple approach:
- When grouping notable events into episodes by service, use the
service_namefield from the event to determine who should receive the alert. - When grouping notable events into episodes by alert group, use the
alert_groupfield from the event to determine who should receive the alert.
To correctly route alerts, you must create and maintain a mapping that associates the correct group to either the service or the alert group. This section explains two possible options, one for small scale environments and one for larger scale environments.
Option 1: Maintain a contact map within the aggregation policy
If you need to route alerts to only a small number of teams, you can build separate action rules for each team directly in a notable event aggregation policy. To do so, perform the following steps:
- From the ITSI main menu, click Configuration > Notable Event Aggregation Policies and open the policy you want to alert from.
- Go to the Action Rules tab.
- For each service or alert group, build a new action rule to notify the appropriate contacts. For example, the following action rule sends an email to the
itsi-adminsteam when a notable event that's grouped by the policy is associated with the ITSI Monitoring Group alert group.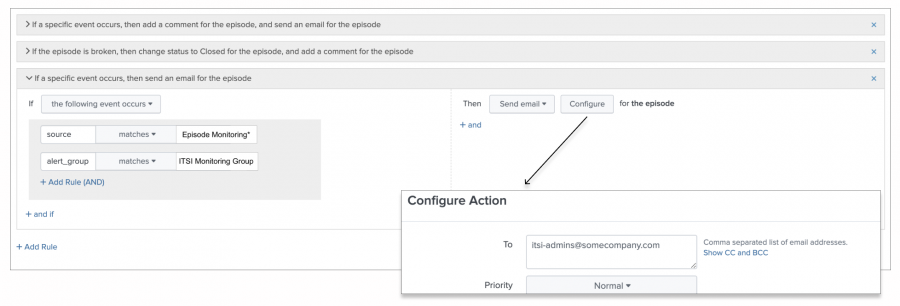
- Build out additional similar actions for other alert groups in your organization.

Option 2: Maintain a contact map within a lookup file
As the number of teams in your organization grows, you need a more scalable approach to maintaining your content map. This content pack ships with the following items to help maintain a contact map:
- A lookup called
itsi_episode_contact_mapthat stores the appropriate contact details for each team. - Pre-built SPL within each correlation search in the content pack, which performs a lookup against the
itsi_episode_contact_maplookup file to enrich each notable event with the contact details. For more information about automatic lookups, see Automatic lookups in the Splunk Enterprise Knowledge Manager Manual. - A saved search called
ITSI Episode Contact Map Generatorthat creates and updates theitsi_episode_contact_maplookup.
To run the search and generate the lookup, perform the following steps:
- From the ITSI main menu, click Dashboards > Reports (or Search > Reports on versions prior to 4.5.0).
- Locate the report called ITSI Episode Contact Map Generator.
- Click Open in Search to generate the lookup.
- Once the lookup is generated, update the contact details using the Lookup File Editor.
In the following example, episodes for
ITSI Monitoring Groupsend an email to the corresponding email address when an alert is triggered. Update the contact method to fit your organization's processes.

- After the lookup is complete and accurate, return to the notable event aggregation policy and update the action rules to handle each contact method you specified. The following example shows a new action that supports the email contact method:
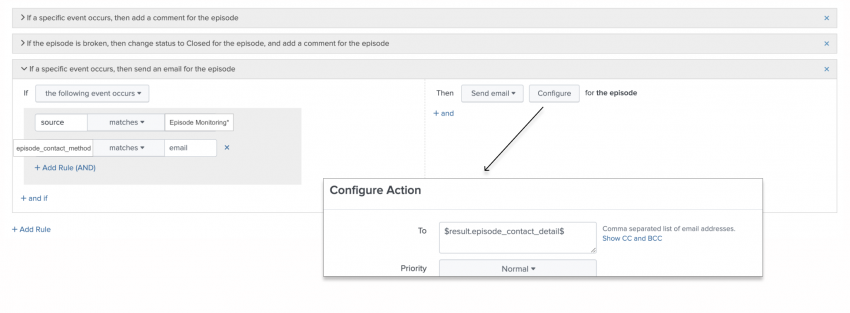


The dynamic token substitution handles changes immediately so you don't have to manually modify to the aggregation policy action rules.
Alert action throttling and configuration
Each organization has different needs or requirements for how often the actions configured in the Aggregation Policy actions tab are executed per episode. This section describes the default throttling configurations and the configuration options you have to meet your organization's specific requirements.
Default throttling behavior
Actions within the aggregation policies are configured to occur each time an episode monitoring notable event is added to the episode. The action throttling is achieved by limiting the overall number of Episode Monitoring notable events that are added to the episode.
- Execute action once for each Episode Monitoring Alert. Each enabled Episode Monitoring alert creates a notable event exactly one time when it detects the condition it was designed to detect. If you enable multiple alerts for the episode (one for each enabled condition detected in the episode), your aggregation policy action might trigger multiple times.
- Execute action again after 24 hours. Each enabled Episode Monitoring alert creates another notable event after 24 hours, assuming the episode is still open and the episode monitoring condition is detected again. When an episode is open for an extended period of time, and the condition of one or more enabled episode monitoring alerts is continuously detected for that episode, you receive multiple episode monitoring alerts for the episode. As a result, your aggregation policy actions might trigger multiple times.
Modifying default throttling behavior
If the default throttling behavior doesn't meet your organization's requirements, you can change the configuration to modify the default behavior.
- Execute action only once upon the first Episode Monitoring Alert detection. To enable multiple episode monitoring alerts, but only execute the action once when the first episode monitoring condition is met, modify the macro named
filter_to_episodes_with_no_episode_monitoring_alerts. Follow the instructions within the spl_comment in that macro to change the configuration. - Execute action either more often or less often than once every 24 hours. To execute the aggregation policy action more or less frequently than once every 24 hours, modify the macro filter_to_episodes_with_no_episode_monitoring_alerts. Modify the
earliest=-24@hsearch timeframe qualifier to match the frequency you want to use. For example,earliest=-8@htriggers aggregation policy actions again after 8 hours. Greatly extending the search timeframe (for example, -30d@d) might create performance issues in the search.
Consider pushing your throttling logic and responsibility to the external system associated with your action. For example, if your action is to create a Splunk On-Call incident, Splunk On-Call natively supports alert throttling and is managed there.
Alert field preprocessing
Aggregation policy actions support the use of tokens, which allows you to pass the necessary information from the episode to the external system associated with your action. Before a field can be used as a token in the action, the field must exist on the episode monitoring alert that triggered the aggregation policy action to execute. Action scripts and external systems might have requirements around the format of the token values, such as escaping quotes in strings or adhering to certain field naming conventions. The content pack ships with the macro preprocess_notable_event_fields_for_external_action which you can implement/customize to add, remove, or modify field values as necessary to prep a notable event for an external action.
| Enable or disable service monitoring for certain services and KPIs | View and manage episodes with the Content Pack for ITSI Monitoring and Alerting |
This documentation applies to the following versions of Content Pack for ITSI Monitoring and Alerting: 2.1.0, 2.2.0, 2.3.0
Feedback submitted, thanks!