Scenario: Kai identifies network problems affecting services 🔗
The following scenario features examples from Buttercup Games, a fictitious e-commerce company.
Kai, a site reliability engineer (SRE) at Buttercup Games, receives an alert about a drop in transaction volume in the checkoutservice service on the company’s site.
They execute the brief runbook they have, verifying that nothing new has been deployed recently, service instances are healthy and running, and nodes seem to have enough memory and CPU. They turn to check the logs and notice lots of error messages, but none of them points to any obvious source.
It’s currently 2 AM in the service owner’s time zone, so Kai also wants rule out network issues before contacting them.
Kai starts their investigation by opening Network Explorer and looking at the Network edges navigator.
Kai immediately sees that the traffic volume to checkoutservice has indeed declined.
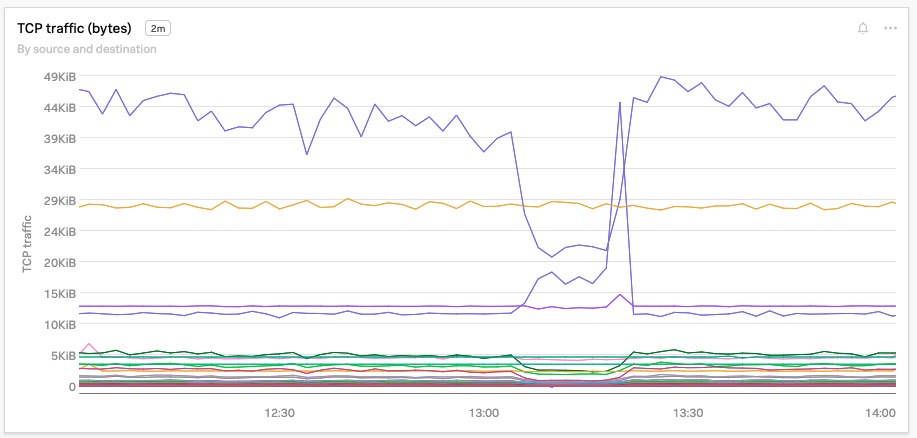
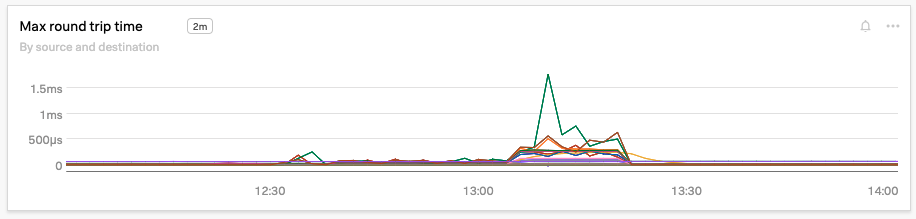
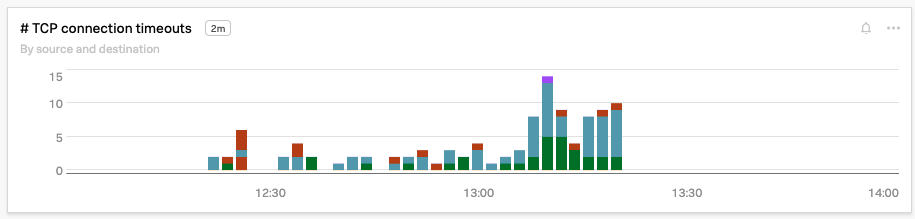
To be sure, Kai also examines the Max round trip time, TCP connection timeouts, and Retransmissions charts and sees that each metric has spiked significantly in the past 5 minutes.

Understanding that checkoutservice is affected by a network problem in the cloud provider, Kai resolves the issue by adding some new Kubernetes nodes to the cluster and does a rolling restart of the checkoutservice pods to remove them from the problematic cloud instances. Within 10 minutes, transaction volume returns to normal.
About half an hour after Kai has finished writing up an incident report, the cloud provider posts on their status page that a network issue has hit this clusters availability, confirming what Kai detected earlier.
With the help of Network Explorer, Kai can troubleshoot network issues by themself. They didn’t need to wait for an announcement from the cloud provider, or wake up the overworked team responsible for checkoutservice.