Use rolling restart
The splunk rolling-restart command performs a phased restart of all the peer nodes, so that the cluster as a whole can continue to perform its functions during the restart process.
The rolling restart helps to ensure that load-balanced forwarders sending data to the cluster always have a peer available to receive the data.
A rolling restart occurs under these circumstances:
- You initiate a rolling restart by selecting the "Rolling restart" option in Splunk Web.
- You run the
splunk rolling-restartCLI command. - The cluster master begins a rolling restart. The master automatically initiates a rolling restart, when necessary, after distributing a configuration bundle to the peer nodes. For details on this process, see Distribute the configuration bundle.
How rolling restart works
During a rolling restart, approximately 10% (by default) of the peer nodes simultaneously undergo restart, until all peers in the cluster complete restart. If there are less than 10 peers in the cluster, one peer at a time undergoes restart. The master node orchestrates the restart process, sending a message to each peer when it is its turn to restart.
The restart percentage tells the master how many restart slots to keep open during the rolling-restart process. For example, if the cluster has 30 peers and the restart percentage is set to the default of 10%, the master keeps three slots open for peers to restart. When the rolling-restart process begins, the master issues a restart message to three peers. As soon as each peer completes its restart and contacts the master, the master issues a restart message to another peer, and so on, until all peers have restarted. Under normal circumstances, in this example, there will always be three peers undergoing restart, until the end of the process.
If the peers are restarting slowly due to inadequately provisioned machines or other reasons, the number of peers simultaneously undergoing restart can exceed the restart percentage. See Handle slow restarts.
At the end of the rolling restart period, the master rebalances the cluster primary buckets. See Rebalance the indexer cluster primary buckets to learn more about this process.
Here are a few things to note about the behavior of a rolling restart:
- The master restarts the peers in random order.
- The cluster enters maintenance mode for the duration of the rolling restart period. This prevents unnecessary bucket fixup while a peer undergoes restart.
- During a rolling restart, there is no guarantee that the cluster will be fully searchable.
Specify a rolling restart
There are two ways you can initiate a rolling restart of an indexer cluster:
Initiate the rolling restart from Splunk Web
- Log into the cluster master instance.
- Click Settings > Indexer clustering.
- Click Edit > Rolling restart.
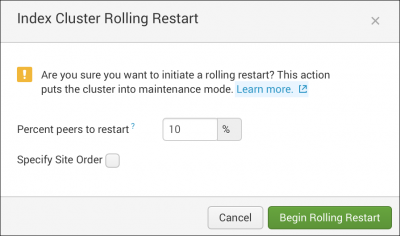
- (Optional) In the Indexer Cluster Rolling Restart dialog box, change the percentage of peers you want the cluster master to restart at a time by entering a number in the Percent peers to restart field. The default percentage is 10.
If you make changes to the percentage, the master overrides the default value for
percent_peers_to_restartinserver.confand the new value becomes the default. - (Optional) If the cluster is a multisite cluster, you can change the order in which sites in the cluster restart. To do this, click the Specify site order checkbox, then click the drop-down boxes to arrange the available sites in the order that you want them to restart.
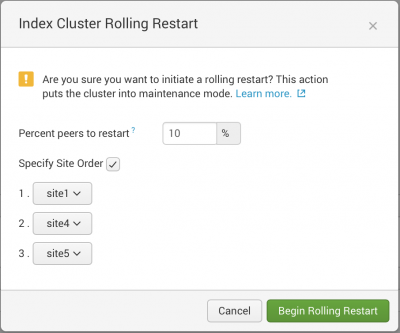
The site order drop down boxes only appear if the cluster is a multisite cluster.
- Click Begin rolling restart.


Initiate the rolling restart from the command line
You can invoke the splunk rolling-restart command from the master:
splunk rolling-restart cluster-peers
Specify the percentage of peers to restart at a time
By default, 10% of the peers restart at a time. The restart percentage is configurable through the percent_peers_to_restart attribute in the [clustering] stanza of server.conf. For convenience, you can configure this setting with the CLI splunk edit cluster-config command.
For example, to cause 20% of the peers to restart simultaneously, run this command:
splunk edit cluster-config -percent_peers_to_restart 20
To cause all peers to restart immediately, run the command with a value of 100:
splunk edit cluster-config -percent_peers_to_restart 100
An immediate restart of all peers can be useful under certain circumstances, such as when no users are actively searching and no forwarders are actively sending data to the cluster. It minimizes the time required to complete the restart.
After you change the percent_peers_to_restart value, you must run the splunk rolling-restart command to initiate the actual restart.
Rolling restart on a multisite cluster
With a multisite cluster, by default, the rolling restart proceeds with site awareness. That is, the master restarts all peers on one site before proceeding to restart the peers on the next site, and so on. This ensures that the cluster is always fully searchable, assuming that each site has a full set of primaries.
Invoke rolling restart on a multisite cluster
When you invoke the splunk rolling-restart command on a multisite cluster, the master completes a rolling restart of all peers on one site before proceeding to the peers on the next site.
You can specify the site restart order, through the -site-order parameter.
Here is the multisite version of the command:
splunk rolling-restart cluster-peers [-site-order site<n>,site<n>, ...]
Note the following points regarding the -site-order parameter:
- This parameter specifies the site restart order.
- You must list all available sites when using this option.
- The default, if this parameter is not specified, is to select sites at random.
For example, if you have a three-site cluster, you can specify rolling restart with this command:
splunk rolling-restart cluster-peers -site-order site1,site3,site2
The master initiates the restarts in this order: site1, site3, site2. So, the master first initiates a rolling restart for the peers on site1 and waits until the site1 peers complete their restarts. Then the master initiates a rolling restart on site3 and waits until it completes. Finally, it initiates a rolling restart on site2.
If you do not want the peer nodes to restart on a site-by-site basis, but instead prefer the master to select the next restart peer randomly, from across all sites, you can use the parameter -site-by-site=false.
How the master determines the number of multisite peers to restart in each round
You can specify the percentage of peers that restart simultaneously by editing the percent_peers_to_restart attribute in server.conf, in the same way that you do for a single-site cluster. This percentage is always calculated globally, even for site-aware rolling restarts.
Assuming the default of 10%, in a two-site cluster with 10 peers on site1 and 20 peers on site2, for a total of 30 peers, the master restarts three peers at a time.
The restart proceeds like this:
- The master selects a site to restart first, for example, site2. (The site order is configurable.)
- The master restarts three peers from site2.
- The master continues to restart peers from site2 as slots become available, until it restarts all 20 peers on site2. It waits until all peers on site2 restart before proceeding to site1. The master does not split restart slots across multiple sites.
- The master restarts three peers on site1.
- The master continues to restart peers from site1 until it restarts all 10 peers on site1.
Handle slow restarts
If the peer instances restart slowly, the peers in one group might still be undergoing restart when the master tells the next group to initiate restart. This can occur, for example, due to inadequate machine resources. To remedy this issue, you can increase the value of restart_timeout in the master's server.conf file. Its default value is 60 seconds.
| Restart the entire indexer cluster or a single peer node | Rebalance the indexer cluster |
This documentation applies to the following versions of Splunk® Enterprise: 7.0.0, 7.0.1, 7.0.2, 7.0.3, 7.0.4, 7.0.5, 7.0.6, 7.0.7, 7.0.8, 7.0.9, 7.0.10, 7.0.11, 7.0.13
Feedback submitted, thanks!