Restart the search head cluster
You can restart the entire cluster with the splunk rolling-restart command. The command performs a phased restart of all cluster members, so that the cluster as a whole can continue to perform its functions during the restart process.
The deployer also automatically initiates a rolling restart, when necessary, after distributing a configuration bundle to the members. For details on this process, see "Push the configuration bundle".
When changing configuration settings in the [shclustering] stanza of server.conf, you must restart all members at approximately the same time to maintain identical settings across all members. Do not use the splunk rolling-restart command to restart the members after such configuration changes, except when configuring the captain_is_adhoc_searchhead attribute. Instead, run the splunk restart command on each member.
For more information, see Configure the search head cluster.
How rolling restart works
When you initiate a rolling restart, the captain issues a restart message to approximately 10% (by default) of the members at a time. Once those members restart and contact the captain, the captain then issues a restart message to another 10% of the members, and so on, until all the members, including the captain, have restarted.
If there are fewer than 10 members in the cluster, the captain issues the restart to one member at a time.
The captain is the final member to restart. After the captain member restarts, it continues to function as the captain.
After all members have restarted, it requires approximately 60 seconds for the cluster to stabilize. During this interval, error messages might appear. You can safely ignore these messages. Error messages will stop within 60 seconds.
During a rolling restart, there is no guarantee that all knowledge objects will be available to all members.
Initiate a rolling restart
You can initiate a rolling restart from Splunk Web or from the command line.
Initiate a rolling restart from Splunk Web
- Log in to any search head cluster member.
- Click Setting > Search head clustering.
The Search head clustering dashboard opens. - Click Begin Rolling Restart.
- Click Restart. This initiates the rolling restart across all cluster members.
Initiate a rolling restart from the command line
Invoke the splunk rolling-restart command from any member:
splunk rolling-restart shcluster-members
Specify the percentage of members to restart at a time
By default, the captain issues the restart command to 10% of the members at a time. The restart percentage is configurable through the percent_peers_to_restart attribute in the [shclustering] stanza of server.conf. For convenience, you can configure this attribute with the CLI splunk edit shcluster-config command. For example, to change the restart behavior so that the captain restarts 20% of the peers at a time, use this command:
splunk edit shcluster-config -percent_peers_to_restart 20
Do not set the value to greater than 20%. This can cause issues during the captain election process.
After changing the percent_peers_to_restart attribute, you still need to run the splunk rolling-restart command to initiate the actual restart.
Restart fails if cluster cannot maintain a majority
A cluster with a dynamic captain requires that a majority of members be running at all times. See "Captain election." This requirement extends to the rolling restart process.
If restarting the next set of members (governed by the percent_peers_to_restart attribute) would cause the number of active members to fall below 51% (for example, because some other members have failed), the restart process halts, in order to maintain an active majority of members. The captain then makes repeated attempts to restart the process, in case another member has rejoined the cluster in the interim. These attempts continue until the restart_timeout period elapses (by default, 10 minutes). At that point, the captain makes no more attempts, and the remaining members do not go through the rolling-restart process.
The restart_timeout attribute is settable in server.conf.
Use searchable rolling restart
Splunk Enterprise 7.1 and later provides a searchable option for rolling restarts. The searchable option lets you perform a rolling restart of search head cluster members with minimal interruption of ongoing searches. You can use searchable rolling restart to minimize search disruption, when a rolling restart is required due to regular maintenance or a configuration bundle push.
How searchable rolling restart works
When you initiate a searchable rolling restart, health checks automatically run to confirm that the cluster is in a healthy state. If the health checks succeed, the captain selects a cluster member and puts that member into manual detention. While in detention, the member stops accepting new search jobs, and waits for in-progress searches to complete. New searches continue to run on remaining members in the search head cluster. For more information, see Put a search head in detention mode.
After a configurable wait time or completion of all in-progress searches (whichever happens first), the captain restarts the member, and the member rejoins the cluster. The process repeats until all cluster members have been restarted. Finally, the captain puts itself into detention mode, and transfers the captaincy to one of the restarted members. The old captain is then restarted, at which point it regains the captaincy, and the rolling restart is complete.
Things to note about the behavior of searchable rolling restarts:
- The captain restarts cluster members one at a time.
- Health checks automatically run to confirm that the cluster is in a healthy state before the rolling restart begins.
- While in manual detention, a member:
- cannot receive new searches (new scheduled searches are executed on other members).
- cannot execute ad hoc searches.
- cannot receive new search artifacts from other members.
- continues to participate in cluster operations.
- The member waits for any ongoing searches to complete, up to a maximum time, as determined by the
decommission_search_jobs_wait_secsattribute inserver.conf. The default setting of 180secs covers the majority of searches in most cases. You can adjust this setting based on the average search runtime. - Searchable rolling restart applies to both historical and real-time searches.
Initiate a searchable rolling restart
You can initiate a searchable rolling restart from Splunk or from the command line.
Initiate a searchable rolling restart from Splunk Web
- Log in to any cluster member.
- Click Settings > Search head clustering.
The Search head clustering dashboard opens. - Click Begin Rolling Restart.
- In the Rolling Restart modal, select the Searchable option.
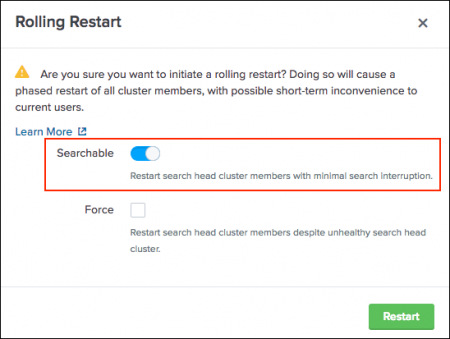
- (Optional) The searchable option automatically runs cluster health checks. To override health check failures and proceed with the searchable rolling restart, select the Force option.
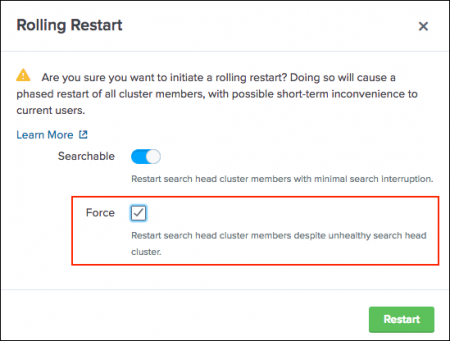
Use the Force option with caution. This option can impact searches.
- Click Restart.
This initiates the searchable rolling restart.


Initiate a searchable rolling restart from the command line
To perform a searchable rolling restart from the command line:
- (Optional) Run preliminary health checks to determine if the search head cluster is in an appropriately healthy state for a searchable rolling restart.
- Use the CLI command to initiate the searchable rolling restart (includes health checks). Optionally, use the force option to override health checks.
1. (Optional) Run preliminary health check
You can use the splunk show shcluster-status command with the verbose option to view information about the health of the search head cluster. This can help you determine if the cluster is in an appropriately healthy state to initiate a searchable rolling restart.
It is not mandatory to run a health check before you initiate a searchable rolling restart. Searchable rolling restart automatically runs a health check when initiated.
To view information about the health of the cluster, run the following command on any cluster member:
splunk show shcluster-status --verbose
Here is an example of the output from the above command:
Captain: decommission_search_jobs_wait_secs : 180 dynamic_captain : 1 elected_captain : Tue Mar 6 23:35:52 2018 id : FEC6F789-8C30-4174-BF28-674CE4E4FAE2 initialized_flag : 1 label : sh3 max_failures_to_keep_majority : 1 mgmt_uri : https://sroback180306192122accme_sh3_1:8089 min_peers_joined_flag : 1 rolling_restart : restart rolling_restart_flag : 0 rolling_upgrade_flag : 0 service_ready_flag : 1 stable_captain : 1 Cluster Master(s): https://sroback180306192122accme_master1_1:8089 splunk_version: 7.1.0 Members: sh3 label : sh3 manual_detention : off mgmt_uri : https://sroback180306192122accme_sh3_1:8089 mgmt_uri_alias : https://10.0.181.9:8089 out_of_sync_node : 0 preferred_captain : 1 restart_required : 0 splunk_version : 7.1.0 status : Up sh2 label : sh2 last_conf_replication : Wed Mar 7 05:30:09 2018 manual_detention : off mgmt_uri : https://sroback180306192122accme_sh2_1:8089 mgmt_uri_alias : https://10.0.181.4:8089 out_of_sync_node : 0 preferred_captain : 1 restart_required : 0 splunk_version : 7.1.0 status : Up sh1 label : sh1 last_conf_replication : Wed Mar 7 05:30:09 2018 manual_detention : off mgmt_uri : https://sroback180306192122accme_sh1_1:8089 mgmt_uri_alias : https://10.0.181.2:8089 out_of_sync_node : 0 preferred_captain : 1 restart_required : 0 splunk_version : 7.1.0 status : Up
The output shows a stable, dynamically elected captain, enough members to support the replication factor, no out-of-sync nodes, and all members running a compatible Splunk Enterprise version (7.1.0 or later). This indicates the cluster is in a healthy state to perform a searchable rolling restart.
Health check output details
The table shows output values for the criteria used to determine the health of the search head cluster.
| Health Check | Output Value | Description |
|---|---|---|
| dynamic_captain | 1 | The cluster has a dynamically elected captain. |
| stable_captain | 1 | The current captain maintains captaincy for at least 10 heartbeats, based on the elected_captain timestamp. (≈ 50 secs, but can vary depending on hearbeat_period)
|
| service_ready_flag | 1 | The cluster has enough members to support the replication factor. |
| out_of_sync | 0 | No cluster member nodes are out-of-sync. |
| splunk_version | 7.1.0 or later. | All cluster members and the indexer cluster master are running a compatible Splunk Enterprise version. |
Health checks are not all inclusive. Checks apply only to the criteria listed.
2. Initiate a searchable rolling restart
To initiate a searchable rolling restart:
On any cluster member, invoke the splunk rolling-restart shcluster-members command using the searchableoption.
splunk rolling-restart shcluster-members -searchable true
The searchable option automatically runs cluster health checks. If you want to proceed with a searchable rolling restart, despite health check failures, you can override health checks and initiate the searchable rolling restart, using the force option. For example:
splunk rolling-restart shcluster-members -searchable true \ -force true \ -decommission_search_jobs_wait_secs <positive integer>
decommission_search_jobs_wait_secs specifies the amount of time, in seconds, that a search head cluster member waits for existing searches to complete before restart. If you do not specify a value for this option, the command uses the default value of 180 secs in server.conf. If you specify a value of zero, rolling restart runs in non-searchable mode.
Use CLI or REST to set rolling restart behavior in server.conf
You can use the CLI or REST API to set the rolling_restart attribute in the shclustering stanza of local/server.conf.
The rolling_restart attribute supports these modes:
restart: Initiates a rolling restart in classic mode (no guarantee of search continuity).searchable: Initiates a rolling restart with minimum search interruption.
When you set rolling_restart = searchable, you can optionally set a custom value for the decommission_search_jobs_wait_secs attribute. This attribute determines the amount of time, in seconds, that a member waits for existing searches to complete before restart. The default is 180 secs.
When using the CLI or REST API to set rolling restart attributes, a cluster restart is not required.
Use the CLI to set rolling restart
To set rolling_restart, invoke the splunk edit shcluster-config -rolling_restart command on any cluster member. For example:
splunk edit shcluster-config -rolling_restart searchable -decommission_search_jobs_wait_secs 300
Use REST to set rolling restart
To set rolling_restart, send a POST request to the shcluster/config/config endpoint. For example:
curl -k -u admin:pass https://<host>:<mPort>/services/shcluster/config - d rolling_restart=searchable \ -d decommission_search_jobs_wait_secs=300
For endpoint details, see shcluster/config/config in the REST API Reference Manual.
For more information on search head clustering configuration, see server.conf.spec.
Monitor the restart process
To check the progress of the rolling restart, run this variant of the splunk rolling-restart on any cluster member:
splunk rolling-restart shcluster-members -status 1
The command returns the status of any members that have started or completed the restart process. For example:
Peer | Status | Start Time | End Time | GUID 1. server-centos65x64-4 | RESTARTING | Mon Apr 20 11:52:21 2015 | N/A | 7F10190D-F00A-47AF-8688-8DD26F1A8A4D 2. server-centos65x64-3 | RESTART-COMPLETE | Mon Apr 20 11:51:54 2015 | Mon Apr 20 11:52:16 2015 | E78F5ECF-1EC0-4E51-9EF7-5939B793763C
Although you can run this command from any member, if you run it from a member that is currently restarting, the command cannot execute and must be retried from another member. For that reason, it is recommended that you run it from the captain. The captain is always the last member to restart, so the command will not fail until the end of the process, if you run it from the captain.
| Put a search head cluster member into detention | Use the search head clustering dashboard |
This documentation applies to the following versions of Splunk® Enterprise: 7.1.0, 7.1.1, 7.1.2, 7.1.3, 7.1.4, 7.1.5, 7.1.6, 7.1.7, 7.1.8, 7.1.9, 7.1.10
Feedback submitted, thanks!