Use proactive Splunk component monitoring
There are two ways to access feature health status information from the /server/health/splunkd endpoint:
- View the
splunkdhealth report in Splunk Web. - Query the
server/health/splunkdendpoint.
You can also monitor feature health status changes in $SPLUNK_HOME/var/log/health.log. For more information on health.log file entries, see Configure health status logs.
View the splunkd health report
The splunkd health report lets you view the current status of features in the splunkd health status tree. You can use the report to identify features whose status indicates a problem, and investigate the cause of those problems.
- On the instance you want to monitor, log in to Splunk Web.
- In the main menu, check the color of the H icon. The color of this icon indicates the overall status of
splunkd.
- Click the H icon to open the health report.
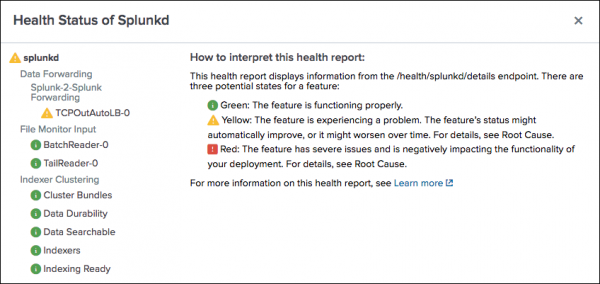
- In the health status tree, click on any feature to view information about the feature's status.
- For features in the red or yellow state, review Root Cause and Last 50 related messages for information that can help you identify the cause of a feature's status change.

Example
This example shows how you can use the splunkd health report to investigate feature health status changes on a cluster master instance.
- Review the splunkd health report.
- Investigate root cause and related messages.
- Confirm the cause of feature status change.
1. Review the splunkd health report
- On the cluster master instance, log in to Splunk Web.
- Check the color of the H icon.

The red color indicates that one or more features in thesplunkdstatus tree has a severe issue. - Click the H icon to open the health report.
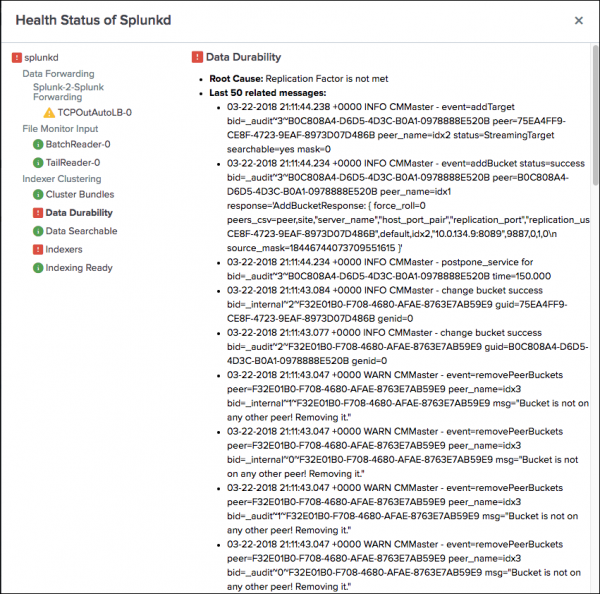
The health status tree shows thedata_durabilityandindexersfeatures have severe issues.

In the health status tree, click the data_durability feature. The following diagnostic information appears:
Root Cause: "Replication Factor is not met."
If the number of peers in the cluster is less than the replication factor, the replication factor cannot be met. Therefore a possible cause of the feature's red status is an offline peer.
Last 50 Related Messages: Searching the related messages, you see log entries that contain streaming errors. For example:
03-22-2018 21:10:41.841 +0000 INFO CMMaster - streaming error src=75EA4FF9-CE8F-4723-9EAF-8973D07D486B tgt=F32E01B0-F708-4680-AFAE-8763E7AB59E9 failing=target bid=_internal~2~75EA4FF9-CE8F-4723-9EAF-8973D07D486B bytes=724188
The streaming error suggests that bucket replication is failing because a source peer cannot communicate with a target peer. This type of error can be caused by a network interruption or an offline peer.
3. Confirm the cause of feature status change
After you use the splunkd health report to investigate the cause of the feature's status change, which suggests a peer is offline, you can use the Monitoring Console to check the status of cluster peers and confirm if the suspected cause is correct.
- In Splunk Web, click Settings > Monitoring Console.
- Click Indexing > Indexer Clustering > Indexer Clustering: Status.
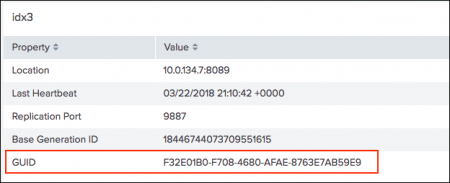
The dashboard shows that the peer nodeidx3is stopped.

- Click on the
idx3peer to see more information. Theidx3peer GUID matches the GUID of the target peer in the streaming error message. This confirms that the cause of thedata_durabilityfeature's red status is an offline peer.
You can now take steps to restart the peer and have it rejoin the cluster, which returns thedata_durabilityfeature to the green state.


Query the server/health/splunkd endpoint
You can integrate proactive Splunk component monitoring with existing third-party monitoring tools and other applications.
To see the overall health status of splunkd, query the server/health/splunkd endpoint. For example:
curl -k -u admin:pass https://<host>:8089/services/server/health/splunkd
For endpoint details, see server/health/splunkd in the REST API Reference Manual.
To see the overall health of splunkd, as well as the health of each feature reporting to the status tree, and information on feature health status changes, query server/health/splunkd/details. For example:
curl -k -u admin:pass https://<host>:8089/services/server/health/splunkd/details
For endpoint details, see server/health/splunkd/details in the REST API Reference Manual.
For more information on how to use Splunk REST API endpoints, see Connecting to splunkd in the REST API User Manual.
For information on Splunk SDKs that support the Splunk REST API, see Overview of Splunk SDKs.
| Configure proactive Splunk component monitoring |
This documentation applies to the following versions of Splunk® Enterprise: 7.1.0, 7.1.1, 7.1.2, 7.1.3, 7.1.4, 7.1.5, 7.1.6, 7.1.7, 7.1.8, 7.1.9, 7.1.10
Feedback submitted, thanks!