Perform a rolling restart of an indexer cluster
A rolling restart performs a phased restart of all peer nodes, so that the indexer cluster as a whole can continue to perform its function during the restart process. A rolling restart also helps ensure that load-balanced forwarders sending data to the cluster always have a peer available to receive the data.
A rolling restart occurs under these circumstances:
- You initiate a rolling restart in Splunk Web.
- You run the
splunk rolling-restartCLI command. - The manager node automatically initiates a rolling restart, when necessary, after distributing a configuration bundle to the peer nodes. For details on this process, see Distribute the configuration bundle.
Rolling restart modes
There are two rolling restart modes for indexer clusters:
- Rolling restart: Restarts peer nodes in successive groups (based on a pre-defined percentage) with no guarantee that the cluster is searchable. See How a rolling restart works.
- Searchable rolling restart: Restarts peer nodes one at a time with minimal interruption of ongoing searches. See Perform a searchable rolling restart.
To set the default rolling restart mode for the splunk rolling-restart cluster-peers command, see Set rolling restart behavior in server.conf.
How a rolling restart works
During a rolling restart, approximately 10% (by default) of the peer nodes simultaneously undergo restart, until all peers in the cluster complete restart. If there are less than 10 peers in the cluster, one peer at a time undergoes restart. The manager node orchestrates the restart process, sending a message to each peer when it is its turn to restart.
The restart percentage tells the manager how many restart slots to keep open during the rolling-restart process. For example, if the cluster has 30 peers and the restart percentage is set to the default of 10%, the manager keeps three slots open for peers to restart. When the rolling-restart process begins, the manager issues a restart message to three peers. As soon as each peer completes its restart and contacts the manager, the manager issues a restart message to another peer, and so on, until all peers have restarted. Under normal circumstances, in this example, there will always be three peers undergoing restart, until the end of the process.
If the peers are restarting slowly due to inadequately provisioned machines or other reasons, the number of peers simultaneously undergoing restart can exceed the restart percentage. See Handle slow restarts.
At the end of the rolling restart period, the manager rebalances the cluster primary buckets. See Rebalance the indexer cluster primary buckets to learn more about this process.
Here are a few things to note about the behavior of a rolling restart:
- The manager restarts the peers in random order.
- The cluster enters maintenance mode for the duration of the rolling restart period. This prevents unnecessary bucket fixup while a peer undergoes restart.
- During a rolling restart, there is no guarantee that the cluster will be fully searchable.
Initiate a rolling restart
You can initiate a rolling restart from Splunk Web or from the command line.
Initiate a rolling restart from Splunk Web
- Log in to the manager node instance.
- Click Settings > Indexer clustering.
- Click Edit > Rolling restart.
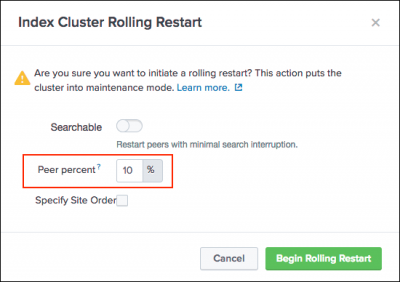
- (Optional) In the "Percent peers to restart" field, enter a number to change the percentage of peers you want the manager to restart simultaneously. The default percentage is 10.
If you make changes to the percentage, the manager overrides the default value for
percent_peers_to_restartinserver.confand the new value becomes the default. - (Optional) If the cluster is a multisite cluster, you can change the order in which sites in the cluster restart. Click the Specify site order checkbox, then click the drop-down boxes to arrange the available sites in the order that you want them to restart.
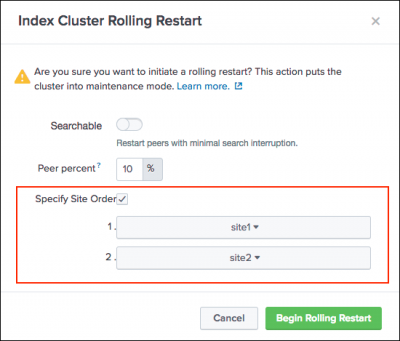
The site order drop down boxes only appear if the cluster is a multisite cluster.
- Click Begin rolling restart.


Initiate a rolling restart from the command line
You can invoke the splunk rolling-restart command from the manager:
splunk rolling-restart cluster-peers
Specify the percentage of peers to restart at a time
By default, 10% of the peers restart at a time. The restart percentage is configurable through the percent_peers_to_restart attribute in the [clustering] stanza of server.conf. For convenience, you can configure this setting with the CLI splunk edit cluster-config command.
For example, to cause 20% of the peers to restart simultaneously, run this command:
splunk edit cluster-config -percent_peers_to_restart 20
To cause all peers to restart immediately, run the command with a value of 100:
splunk edit cluster-config -percent_peers_to_restart 100
An immediate restart of all peers can be useful under certain circumstances, such as when no users are actively searching and no forwarders are actively sending data to the cluster. It minimizes the time required to complete the restart.
After you change the percent_peers_to_restart value, you must run the splunk rolling-restart command to initiate the actual restart.
Perform a searchable rolling restart
Splunk Enterprise 7.1.0 and later provides a searchable option for rolling restarts. The searchable option lets you perform a rolling restart of peer nodes with minimal interruption of ongoing searches. You can use searchable rolling restart to minimize search disruption, when a rolling restart is required due to regular maintenance or a configuration bundle push.
How searchable rolling restart works
When you initiate a searchable rolling restart, the manager performs a restart of all peer nodes one at a time. During the restart process for each peer, the manager reassigns bucket primaries to other peers to retain the searchable state, and all in-progress searches complete within a configurable timeout period. The manager then restarts the peer and the peer rejoins the cluster. This process repeats for each peer until the rolling restart is complete.
Things to note about the behavior of searchable rolling restart:
- The manager restarts peers one at a time.
- The manager runs health checks to confirm that the cluster is in a searchable state before it initiates the searchable rolling restart.
- The peer waits for in-progress searches to complete, up to a maximum time period, as determined by the
decommission_search_jobs_wait_secsattribute inserver.conf. The default for this attribute is 180 seconds. This covers the majority of searches in most cases. - Searchable rolling restart applies to both historical searches and real-time searches.
- During a searchable rolling restart of the indexer cluster all continuous scheduled searches and realtime scheduled searches by default will be paused until the completion of the restart.
Best practices for searchable rolling restart
Before you initiate a searchable rolling restart, to help ensure a successful outcome, consider these best practices:
- To ensure that indexers do not get stuck in the reassigning primaries state and are able to restart during a searchable rolling restart, set the following attributes in the
[clustering]stanza inserver.confon the manager node:[clustering] restart_timeout = 600 rolling_restart = searchable_force decommission_force_timeout = 180
For more information on the above attributes, see server.conf in the Admin Manual.
If you specify the
searchableorsearchable_forceoption when you initiate a rolling restart from the CLI or Splunk Web, the option you specify takes precedence over the existingrolling_restartsetting inserver.conf. - In-progress searches that take longer than the
decommission_search_jobs_wait_secs(default=180s), might generate incomplete results and a corresponding error message. If you have a scheduled search that must complete, either increase the the value of thedecommission_search_jobs_wait_secsattribute inserver.conf, or do not run a searchable rolling restart within the search's timeframe. - Make sure the
search_retryattribute in the[search]stanza oflimits.confis set tofalse(the default). Setting this totruemight cause searches that take longer than thedecommission_search_jobs_wait_secsto generate duplicate or partial results with no error message.
Initiate a searchable rolling restart
You can initiate a searchable rolling restart from Splunk Web or from the command line.
Inititate a searchable rolling restart from Splunk Web
- On the manager, click Settings > Indexer Cluster.
- Click Edit > Rolling Restart.
- In the Index Cluster Rolling Restart modal, select Searchable.
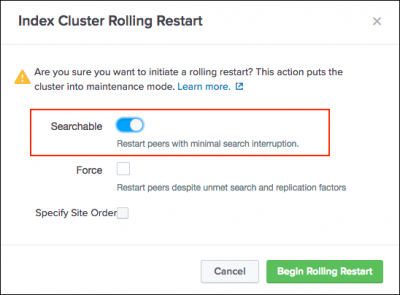
- Click Begin Rolling Restart.
This initiates the searchable rolling restart. - (Optional) To proceed with the searchable rolling restart despite health check failures, select the Force option. This option overrides health checks and allows the searchable rolling restart to proceed.
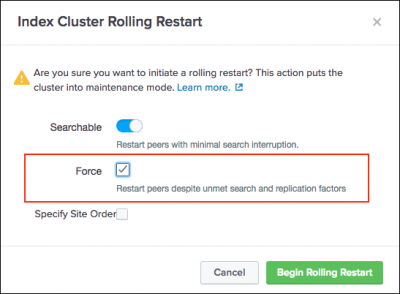
Use the Force option with caution. This option can impact searches.
- Click Begin Rolling Restart.
This initiates the searchable rolling restart. You can monitor the progress of the searchable rolling restart with the manager node dashboard.


Initiate a searchable rolling restart from the command line
To perform a searchable rolling restart from the command line:
- (Optional) Run preliminary health checks to determine if the cluster is in a searchable state (search factor is met and all data is searchable).
- Initiate a searchable rolling restart (includes health checks).
Optionally, initiate a searchable rolling restart using the force option (overrides health checks).
1. (Optional) Run preliminary health checks
To check the current health of the cluster, run the following command on the manager:
splunk show cluster-status --verbose
This command shows information about the cluster state. Review the command output to confirm that the cluster is in a searchable state (search factor is met, all data is searchable) before you initiate the searchable rolling restart.
The cluster must have two searchable copies of each bucket to be in a searchable state for a searchable rolling restart.
Here is an example of the output from the splunk show cluster-status --verbose command:
splunk@manager1:~/bin$ ./splunk show cluster-status --verbose
Pre-flight check successful .................. YES
├────── Replication factor met ............... YES
├────── Search factor met .................... YES
├────── All data is searchable ............... YES
├────── All peers are up ..................... YES
├────── CM version is compatible ............. YES
├────── No fixup tasks in progress ........... YES
└────── Splunk version peer count { 7.1.0: 3 }
Indexing Ready YES
idx1 0026D1C6-4DDB-429E-8EC6-772C5B4F1DB5 default
Searchable YES
Status Up
Bucket Count=14
Splunk Version=7.1.0
idx3 31E6BE71-20E1-4F1C-8693-BEF482375A3F default
Searchable YES
Status Up
Bucket Count=14
Splunk Version=7.1.0
idx2 81E52D67-6AC6-4C5B-A528-4CD5FEF08009 default
Searchable YES
Status Up
Bucket Count=14
Splunk Version=7.1.0
The output shows that the health check is successful, which indicates the cluster is in a searchable state for a searchable rolling restart.
Health check output details
The table shows output values for the criteria used to determine the health of the indexer cluster.
| Health Check | Output Value | Description |
|---|---|---|
| Replication factor met | YES | The cluster has the specified number of copies of raw data. |
| Search factor met | YES | The cluster has the specified number of searchable copies of data. |
| All data is searchable | YES | The cluster has a searchable copy of all data. |
| CM version is compatible | YES | The manager is running a compatible version of Splunk Enterprise. |
| No fixup tasks in progress | YES | No cluster remedial activities (such as bucket replication or indexing non-searchable bucket copies) is underway. |
| All peers are up | YES | All indexer cluster peers are running. |
| Splunk version peer count | 7.1 or later : # of peers | Number of peers running the Splunk Enterprise version. |
Health checks are not all inclusive. Checks apply only to the criteria listed.
2. Initiate a searchable rolling restart
To initiate a searchable rolling restart:
On the manager, invoke the splunk rolling-restart cluster-peers command using the searchable option.
splunk rolling-restart cluster-peers -searchable true
This command automatically runs health checks against the cluster. If these health checks fail, the command returns the following message that indicates the cluster is not in a searchable state.
"Request rejected. Wait until search factor is met and all data is searchable."
If you want to proceed with the searchable rolling restart despite the health check failure, use the force option to override the health check and initiate the searchable rolling restart, as follows:
On the manager, invoke the splunk rolling-restart cluster-peers command using the force option.
splunk rolling-restart cluster-peers -searchable true \ -force true \ -restart_inactivity_timeout <secs> \ -decommission_force_timeout <secs>
When using the force option you can specify custom values for the following additional parameters. If you do not specify these parameters their default values are used.
decommission_force_timeout: The amount of time, in seconds, after which the manager forces the peer to restart. Default: 180.restart_inactivity_timeout: The amount of time, in seconds, after which the manager considers the peer restart a failure and proceeds to restart other peers. Default: 600.
Set rolling restart default behavior in server.conf
You can set the default behavior for rolling restart using the rolling_restart attribute in the [clustering] stanza of server.conf. This attribute lets you define the type of rolling restart the manager performs on the peers. It also provides a convenient way to automatically load options for the splunk rolling-restart cluster-peers command as an alternative to passing them from the command line.
The rolling_restart attribute supports these settings:
restart: Initiates a rolling restart.shutdown: Initiates a staged rolling restart. Shuts down a single peer, then waits for a manual restart. The process repeats until all peers are restarted.searchable: Initiates a rolling restart with minimum search interruption.searchable_force: Overrides cluster health checks and initiates a searchable rolling restart.
Specifying the searchable option in the CLI or UI overrides the rolling_restart = shutdown setting in server.conf.
To set the rolling_restart attribute:
- On the manager, edit
$SPLUNK_HOME/etc/system/local/server.conf. - In the
[clustering]stanza, specify therolling_restartattribute value. For example:
[clustering] mode = manager replication_factor = 3 search_factor = 2 pass4SymmKey = whatever rolling_restart = searchable
- Restart the manager.
When you set rolling_restart = searchable_force, you can specify custom values for the following additional attributes in the [clustering] stanza. If you do not specify these attributes their default values are used.
decommission_force_timeout: The amount of time, in seconds, after which the manager forces the peer to restart. Default: 180.restart_inactivity_timeout: The amount of time, in seconds, after which the manager considers the peer restart a failure and proceeds to restart other peers. Default: 600.
For more information, see server.conf.spec in the Admin Manual.
Set searchable rolling restart as default mode for bundle push
Configuration bundle pushes that require a restart use the rolling_restart value in server.conf. You can set the rolling_restart value to searchable to make searchable rolling restart the default mode for all rolling restarts triggered by a bundle push.
To set searchable rolling restart as the default mode for configuration bundle push, use one of the following attributes in the [clustering] stanza of server.conf:
rolling_restart = searchable or rolling_restart = searchable_force
For more information on configuration bundle push for indexer clusters, see Apply the bundle to the peers.
Disable deferred scheduled searches
By default, during a searchable rolling restart, continuous scheduled searches are deferred until after the restart is completed, based on the defer_scheduled_searchable_idxc attribute in savedsearches.conf. Real-time scheduled searches are deferred regardless of this setting. You can disable this default behavior so that continuous scheduled searches are not deferred, as follows:
-
On the search head, edit
$SPLUNK_HOME/etc/system/local/savedsearches.conf. -
Set
defer_scheduled_searchable_idxcto false.[default] defer_scheduled_searchable_idxc = false
- Restart Splunk.
When defer_scheduled_searchable_idxc is disabled, scheduled saved searches might return partial results.
To reenable deferred scheduled searches, set defer_scheduled_searchable_idxc = true.
For more information on defer_scheduled_searchable_idxc, see savedsearches.conf in the Admin Manual.
Rolling restart on a multisite cluster
With a multisite cluster, by default, the rolling restart proceeds with site awareness. That is, the manager restarts all peers on one site before proceeding to restart the peers on the next site, and so on. This ensures that the cluster is always fully searchable, assuming that each site has a full set of primaries.
Invoke rolling restart on a multisite cluster
When you invoke the splunk rolling-restart command on a multisite cluster, the manager completes a rolling restart of all peers on one site before proceeding to the peers on the next site.
You can specify the site restart order, through the -site-order parameter.
Here is the multisite version of the command:
splunk rolling-restart cluster-peers [-site-order site<n>,site<n>, ...]
Note the following points regarding the -site-order parameter:
- This parameter specifies the site restart order.
- You can specify a subset of sites. Only the specified sites are restarted, in the order given.
- The default, if this parameter is not specified, is to select sites at random.
For example, if you have a three-site cluster, you can specify rolling restart with this command:
splunk rolling-restart cluster-peers -site-order site1,site3,site2
The manager initiates the restarts in this order: site1, site3, site2. So, the manager first initiates a rolling restart for the peers on site1 and waits until the site1 peers complete their restarts. Then the manager initiates a rolling restart on site3 and waits until it completes. Finally, it initiates a rolling restart on site2.
If you do not want the peer nodes to restart on a site-by-site basis, but instead prefer the manager to select the next restart peer randomly, from across all sites, you can use the parameter -site-by-site=false.
How the manager determines the number of multisite peers to restart in each round
You can specify the percentage of peers that restart simultaneously by editing the percent_peers_to_restart attribute in server.conf, in the same way that you do for a single-site cluster. This percentage is always calculated globally, even for site-aware rolling restarts.
Assuming the default of 10%, in a two-site cluster with 10 peers on site1 and 20 peers on site2, for a total of 30 peers, the manager restarts three peers at a time.
The restart proceeds like this:
- The manager selects a site to restart first, for example, site2. (The site order is configurable.)
- The manager restarts three peers from site2.
- The manager continues to restart peers from site2 as slots become available, until it restarts all 20 peers on site2. It waits until all peers on site2 restart before proceeding to site1. The manager does not split restart slots across multiple sites.
- The manager restarts three peers on site1.
- The manager continues to restart peers from site1 until it restarts all 10 peers on site1.
Handle slow restarts
If the peer instances restart slowly, the peers in one group might still be undergoing restart when the manager tells the next group to initiate restart. This can occur, for example, due to inadequate machine resources. To remedy this issue, you can increase the value of restart_timeout in the manager's server.conf file. Its default value is 60 seconds.
Conflicting operations
You cannot run certain operations simultaneously:
- Data rebalance
- Excess bucket removal
- Rolling restart
- Rolling upgrade
If you trigger one of these operations while another one is already running, splunkd.log, the CLI, and Splunk Web all surface an error to the effect that a conflicting operation is in progress.
| Restart the entire indexer cluster or a single peer node | Rebalance the indexer cluster |
This documentation applies to the following versions of Splunk® Enterprise: 8.1.0, 8.1.1, 8.1.2, 8.1.3, 8.1.4, 8.1.5, 8.1.6, 8.1.7, 8.1.8, 8.1.9, 8.1.10, 8.1.11, 8.1.12, 8.1.13, 8.1.14
Feedback submitted, thanks!