Predict Numeric Fields
The Predict Numeric Fields assistant uses regression algorithms to predict numeric values. Such models are useful for determining to what extent certain peripheral factors contribute to a particular metric result. After the regression model is computed, you can use these peripheral values to make a prediction on the metric result.

The visualization above illustrates a scatter plot of the actual versus predicted results. This visualization is from the showcase example for Predict Numeric Fields with the Server Power Consumption data in the Splunk Machine Learning Toolkit.
Algorithms
The Predict Numeric Fields assistant uses the following algorithms:
Fit a model to predict a numeric field
Prerequisites
- For information about Preprocessing, see Preprocessing.
- If you are not sure which algorithm to choose, start with the default algorithm, Linear Regression, or see Algorithms.
Steps
- Run a search.
- (Optional) To add preprocessing steps, click + Add a step.
- Select an algorithm from the Algorithm drop down menu.
- Select a field from the drop down menu Field to Predict.
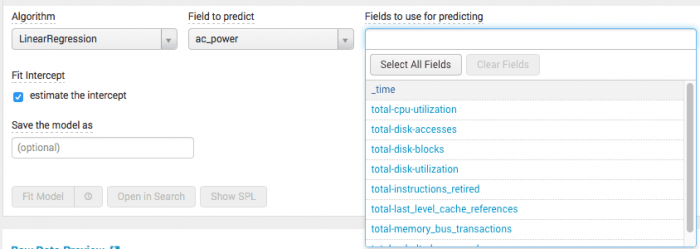
- Select a combination of fields from the drop down menu Fields to use for predicting.
As seen below in the server power showcase example, the drop down menu contains a list of all the possible fields that could be used to predict ac_power using the linear regression algorithm.
- Split your data into training and testing data.
- (Optional) Depending on the algorithm you selected, the toolkit may show additional fields to include in your model.
- Type the name the model in Save the model as.
- Click Fit Model.
When you select the Field to predict, the other drop down Fields to use for predicting populates a list of fields that you can include in your model.

Fit the model with the training data, and then compare your results against the testing data to validate the fit. The default split is 50/50, and the data is divided randomly into two groups.
To get information about a field, hover over it to see a tooltip. The example below shows the optional field N estimators from the Random Forrest Regressor algorithm.

You must specify a name for the model in order to fit a model on a schedule or schedule an alert. This name and the settings you select are saved in the history in the Load Existing Settings tab.
Interpret and validate
After you fit the model, review the prediction results and visualizations to see how well the model predicted the numeric field. You can use the following methods to evaluate your predictions.
| Charts & Results | Applications |
|---|---|
| Actual vs. Predicted Scatter Plot | This visualization plots the predicted value (yellow line), against the raw actual values (blue dots), for the predicted field.The yellow line showing the perfect result generally isn't attainable, but the closer the points are to the line, the better the model. Hover over the blue dots to see actual values. |
| Residuals Histogram | A histogram that shows the difference between the actual values (yellow line), and the predicted values (blue bars). Hover over the blue bars to see the residual error, different between the actual and predicted result, and sample count, the number of results with this error. In a perfect world all the residuals would be zero. In reality, the residuals probably end on a bell curve that is ideally clustered tightly around zero. |
| R2 Statistic | This statistic explains how well the model explains the variability of the result. 100% (a value of 1) means the model fits perfectly. The closer the value is to 1 (100%), the better the result. |
| Root Mean Squared Error | The root mean squared error explains the variability of the result, which is essentially the standard deviation of the residual. The formula takes the difference between actual and predicted values, squares this value, takes an average, and then takes a square root. This value can be arbitrarily large and just gives you an idea of how close or far the model is. These values only make sense within one dataset and shouldn’t be compared across datasets. |
| Fit Model Parameters Summary | This summary displays the coefficients associated with each variable in the regression model. A relatively high coefficient value shows a high association of that variable with the result. A negative value shows a negative correlation. |
| Actual vs. Predicted Overlay | This shows the actual values against the predicted values, in sequence. |
| Residuals | The residuals show the difference between predicted and actual values, in sequence. |
Refine the model
After you validate the model, refine the model by adjusting the fields used to predict the numeric field and fit the model:
- Remove fields that might generate a distraction.
- Add more fields.
In the Load Existing Settings tab, which displays a history of models you have fitted, sort by the R2 statistic to see which combination of fields yielded the best results.
Deploy the model
After you validate and refine the model, deploy it.
- Click the icon to the right of Fit Model to schedule model training.
- (Optional) To access the model, click Scheduled Jobs > Scheduled Training in the menu.
- Click Open in Search to open a new Search tab.
- Click Show SPL to see the search query that was used to fit the model.
- Click the Schedule Alert to set up an alert that is triggered when the predicted value meets a threshold you specify.
- After you save the alert, you can access it from the Scheduled Jobs > Alerts menu.

You can set up a regular interval to fit the model, for example, once a week.
This shows you the search query that uses all data, not just the training set.
For example, you could use this same query on a different data set.
For more information about alerts, see Getting started with alerts in the Splunk Enterprise Alerting Manual.
| Custom visualizations | Predict Categorical Fields |
This documentation applies to the following versions of Splunk® Machine Learning Toolkit: 2.4.0, 3.0.0, 3.1.0
Feedback submitted, thanks!