About subsearches
Using subsearches
A subsearch is a search within a primary, or outer, search. When a search contains a subsearch, the subsearch typically runs first.
Subsearches must be enclosed in square brackets in the primary search.
Consider the following search.
sourcetype=access_* status=200 action=purchase [search sourcetype=access_* status=200 action=purchase | top limit=1 clientip | table clientip] | stats count, dc(productId), values(productId) by clientip
The subsearch portion of the search is enclosed in square brackets.
[search sourcetype=access_* status=200 action=purchase | top limit=1 clientip | table clientip]
The first command in a subsearch must be a generating command, such as search, eventcount, inputlookup, and tstats. For a list of generating commands, see Command types in the Search Reference.
One exception is the foreach command, which accepts a subsearch that does not begin with a generating command, such as eval.
When a search contains a subsearch, the Splunk software processes the subsearch first as a distinct search job. Then it runs the search that contains it as another search job. Keep this in mind if you include subsearches in searches that are run frequently and you are concerned about search concurrency issues or excess load on your search scheduler.
How subsearches work
A subsearch looks for a single piece of information that is then added as a criteria, or argument, to the primary search. You use a subsearch because the single piece of information that you are looking for is dynamic. The single piece of information might change every time you run the subsearch.
For example, you want to return all of the events from the host that was the most active in the last hour. The host that was the most active might be different from hour to hour. You need to identify the most active host before you can return the events from that host.
Break this search down into two parts.
- The most active host in the last hour. This is the subsearch.
- The events from that host. This is the primary search.
You could run two searches to obtain the list of events. The following search identifies the most active host in the last hour.
sourcetype=syslog earliest=-1h | top limit=1 host | fields host
This search returns only one host value. Assume that the result is the host named crashy. To return all of the events from the host crashy, you need to run a second search.
sourcetype=syslog host=crashy
The drawback to running two searches is that you cannot set up reports and dashboard panels to run automatically. You must run the first search to identify the piece of information that you need, and then run the second search with that piece of information.
You can combine these two searches into one search that includes a subsearch.
sourcetype=syslog [search sourcetype=syslog earliest=-1h | top limit=1 host | fields + host]
The subsearch is in square brackets and is run first. The subsearch in this example identifies the most active host in the last hour. The result of the subsearch is then provided as a criteria for the main search. The main search returns the events for the host.
By default, subsearches return a maximum of 10,000 results and have a maximum runtime of 60 seconds. If a subsearch runs for more than 60 seconds, its search results are automatically finalized.
Time ranges and subsearches
Time ranges selected from the Time Range Picker apply to the base search and to subsearches.
However, time ranges specified directly in the base search do not apply to subsearches. Likewise, a time range specified directly in a subsearch applies only to that subsearch. The time range does not apply to the base search or any other subsearch.
For example, if the Time Range Picker is set to Last 7 days and a subsearch contains earliest=2d@d, then the earliest time modifier applies only to the subsearch and Last 7 days applies to the base search.
When to use subsearches
Subsearches are mainly used for two purposes:
- Parameterize one search, using the output of another search. The previous example of searching for the most active host in the last hour is an example of this use of a subsearch.
- Run a separate search and add the output to the first search using the
appendcommand.
A subsearch can be used only where the explicit action that you are trying to accomplish is with the search and not a transformation of the data. For example, you cannot use a subsearch with "sourcetype=top | multikv", because the multikv command does not expect a subsearch as an argument. Certain commands, such as append and join can accept a subsearch as an argument.
Multiple subsearches in a search string
You can use more than one subsearch in a search.
If a search has a set of nested subsearches, the inner most subsearch is run first, followed by the next inner subsearch, working out to the outermost subsearch and then the primary search.
For example, you have the following search.
index=* OR index=_*
[search index=* | stats count by component
| search [search index=* | stats count by user
| search [search index=* | stats by ipaddress]]]
You must have a command after the pipe and before the subsearch. In this example, the search command is used for the second and third subsearches. The first subsearch is used as a predicate to the main search.
The order in which this search is processed is:
|search [search index=* | stats by ipaddress]|search [search index=* | stats count by user][search index=* | stats count by component]- (An implied search command)
index=* OR index=_*(and the results of the nested subsearches)
Here is another example.
index=foo error [ search index=bar baz [search index=* | stats count by user | search count>100] | stats count by host ]
Be certain to analyze your search syntax when you find yourself using subsearches frequently. It is often possible to rewrite the search and omit the subsearch.
If the subsearches are sequential instead of nested, the subsearch farthest to the left, or beginning of the search, is run first. Then working towards the right, or end of the search, the next subsearch is run. When all of the subsearches are run, then the primary search is run.
For example, you have the following search.
index=* OR index=_* | [search index=* | stats count by customerID] | [search index=* | stats by productName]
The order in which the search is processes is:
search index=* | stats by customerIDsearch index=* | stats count by productName- (An implied search command)
index=* OR index=_*(the results of the subsearches)
Initiating subsearches with search commands
A subsearch can be initiated through a search command such as the map command. For example, consider the following search:
|makeresults
|map search="search index=* OR index=_* earliest=0 latest=now"
The map command runs a subsearch for the option search="search index=* OR index=_* earliest=0 latest=now". Other commands that can run a subsearch include search, join and union. These commands can start one or more subsearches. What's more, each subsearch, not the command itself, is limited by the maxtime setting in the limits.conf file, which specifies the maximum number of seconds that a subsearch can run before finalizing. In our example, the maxtime setting limits the runtime of the subsearch and is applied to the subsearch, not the map command. However, the subsearch may stop at the map command.
Subsearch examples
These examples show you the difference between searching your data with and without a subsearch.
| These examples use the sample data from the Search Tutorial but should work with any format of Apache web access log. To try this example on your own Splunk instance, you must download the sample data and follow the instructions to get the tutorial data into Splunk. Use the time range All time when you run the search. |
Example 1: Without a subsearch, find what the most frequent shopper purchased
You want to find the single most frequent shopper on the Buttercup Games online store and what that shopper has purchased. Use the top command to return the most frequent shopper.
- To find the shopper who accessed the online shop the most, use this search.
sourcetype=access_* status=200 action=purchase | top limit=1 clientipThe
limit=1argument specifies to return 1 value. Theclientipargument specifies the field to return.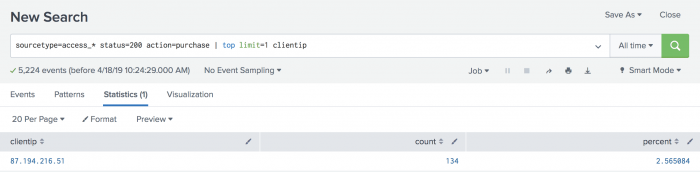
This search returns oneclientipvalue, 87.194.216.51, which you will use to identify the VIP shopper. - You now need to run another search to determine how many different products the VIP shopper has purchased. Use the
statscommand to count the purchases by this VIP customer.sourcetype=access_* status=200 action=purchase clientip=87.194.216.51 | stats count, dc(productId), values(productId) by clientip
This search uses the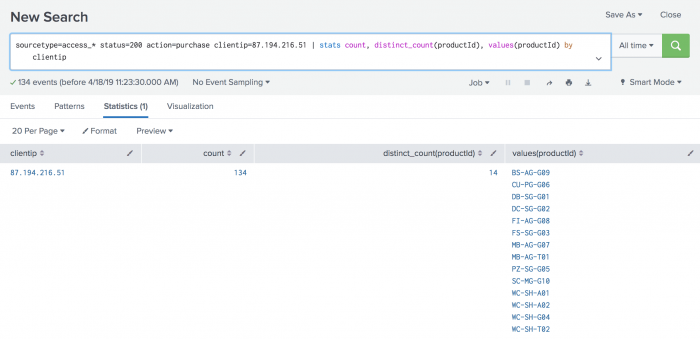
count()function to return the total count of the purchases for the VIP shopper. Thedc()function is the distinct_count function. Use this function to count the number of different, or unique, products that the shopper bought. Thevaluesfunction is used to display the distinct product IDs as a multivalue field.


The drawback to this approach is that you have to run two searches each time you want to build this table. The top purchaser is not likely to be the same person at any given time range.
Example 2: Using a subsearch, find what the most frequent shopper purchased
Let's start with our first requirement, to identify the single most frequent shopper on the Buttercup Games online store.
- Copy and paste the following search into the Search bar and run the search. Make sure the time range is All time.
sourcetype=access_* status=200 action=purchase | top limit=1 clientip | table clientipThis search returns the clientip for the most frequent shopper,
clientip=87.194.216.51. This search is almost identical to the search in Example 1 Step 1. The difference is the last piped command,| table clientip, which displays the clientip information in a table.
To find what this shopper has purchased, you run a search on the same data. You provide the result of the most frequent shopper search as one of the criteria for the purchases search.
The most frequent shopper search becomes the subsearch for the purchases search. The purchases search is referred to as the outer or primary search. Because you are searching the same data, the beginning of the outer search is identical to the beginning of the subsearch.
A subsearch is enclosed in square brackets [ ] and processed first when the search is parsed. - Copy and paste the following search into the Search bar and run the search.
sourcetype=access_* status=200 action=purchase [search sourcetype=access_* status=200 action=purchase | top limit=1 clientip | table clientip] | stats count, distinct_count(productId), values(productId) by clientipBecause the
topcommand returns the count and percent fields, thetablecommand is used to keep only theclientipvalue.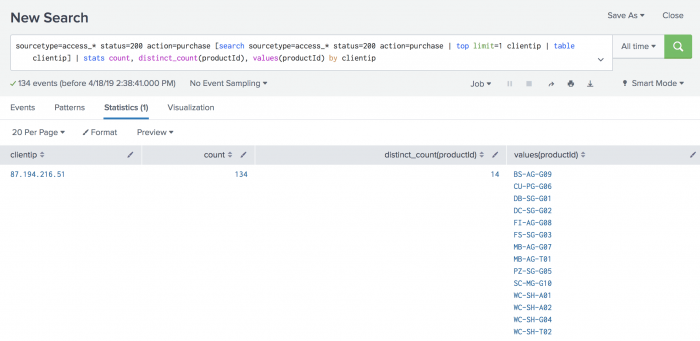
These results should match the result of the two searches in Example 1, if you run it on the same time range. If you change the time range, you might see different results because the top purchasing customer will be different.
The performance of this subsearch depends on how many distinct IP addresses match
status=200 action=purchase. If there are thousands of distinct IP addresses, thetopcommand has to keep track of all of those addresses before the top 1 is returned, impacting performance. By default, subsearches return a maximum of 10,000 results and have a maximum runtime of 60 seconds. In large production environments, it is possible that the subsearch in this example will timeout before it completes. The best option is to rewrite the query to limit the number of events that the subsearch must process. Alternatively, you can increase the maximum results and maximum runtime parameters. For more information about these options, see About performance considerations.
Make the search syntax easier to read
Subsearches and long complex searches can be difficult to read. You can apply auto-formatting to the search syntax to make the the search syntax easier to read in the Search bar. Use the following keyboard shortcut to apply auto-formatting to a search.
- On Linux or Windows use Ctrl + \.
- On Mac OSX use Command + \. You can also use Command + Shift + F, which works well with many non-English keyboards.
Make the search results easier to understand
You can make the information more understandable by renaming the columns.
Column Rename count Total Purchased dc(productId) Total Products values(productId) Product IDs clientip VIP Customer You rename columns by using the AS operator on the fields in your search. If the rename that you want to use contains a space, you must enclose the rename in quotation marks.
- To rename the fields, copy and paste the following search into the Search bar and run the search.
sourcetype=access_* status=200 action=purchase [search sourcetype=access_* status=200 action=purchase | top limit=1 clientip | table clientip] | stats count AS "Total Purchased", distinct_count(productId) AS "Total Products", values(productId) AS "Product IDs" by clientip | rename clientip AS "VIP Customer"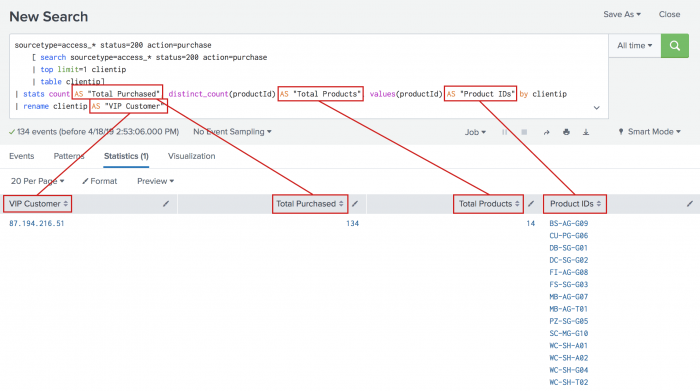



Subsearch performance considerations
A subsearch can be a performance drain if the search returns a large number of results.
Consider this search.
sourcetype=access_* status=200 action=purchase [search sourcetype=access_* status=200 action=purchase | top limit=1 clientip | table clientip] | stats count, dc(productId), values(productId) by clientip
The performance of this subsearch depends on how many distinct IP addresses match status=200 action=purchase. If there are thousands of distinct IP addresses, the top command has to keep track of all of them before the top 1 is returned, impacting performance.
Additionally, by default subsearches return a maximum of 10,000 results and have a maximum runtime of 60 seconds. In large production environments it is quite possible that the subsearch in this example will timeout before it completes.
There are several alternatives you can use to control the results:
- Try to rewrite the query to limit the number of events the subsearch must process.
- You can change the number of results that the format command operates over inline with your search by appending the
formatcommand to the end of your subsearch.
For more information, see the...| format maxresults = <integer>formatcommand in the Search Reference. - If you are using Splunk Enterprise, you can also control the subsearch by editing settings in the [subsearch] stanza in the limits.conf file. For example, you can edit the
maxoutsetting to adjust the size of results that are returned from your subsearches. See How to edit a configuration file.
After running a search, you can click the Job menu and select Inspect Job to open the Search Job Inspector. Scroll down to the remoteSearch component to see the actual query that resulted from your subsearch. For more information, see View search job properties in this manual.
Output settings for subsearch commands
By default, subsearches return a maximum of 10,000 results. You will see variations in the actual number of output results because every command can change what the default maxout is when the command invokes a subsearch. Additionally, the default applies to subsearches that are intended to be expanded into a search expression, which is not the case for some commands such as join, append, and appendcols.
- For example, the
appendcommand can override the default maximum if themaxresultrowsargument is specified, unless you specifymaxoutas an argument to theappendcommand. - The output limit of the
joincommand is controlled bysubsearch_maxoutin thelimits.conffile. This defaults to 50,000 events.
| How time zones are processed by the Splunk platform | Use subsearch to correlate events |
This documentation applies to the following versions of Splunk Cloud Platform™: 9.3.2411 (latest FedRAMP release), 9.0.2208, 9.0.2209, 8.2.2112, 8.2.2201, 8.2.2202, 8.2.2203, 9.0.2205, 9.0.2303, 9.0.2305, 9.1.2308, 9.1.2312, 9.2.2403, 9.2.2406, 9.3.2408
Feedback submitted, thanks!