Configure streams
The Configure Streams UI lets you configure passive capture of network event data for a variety of protocols.
In Splunk Stream, a grouping of network event data is called a "stream." You can use the Configure Streams UI to create new streams for any supported protocol. You can also apply aggregation and filtering rules to any stream, which can help you capture only the data you require for analysis, while minimizing the amount of data sent to your indexers.
Use the Configure Streams UI to:
- Create new streams to capture protocol-specific data.
- Select protocol fields for any stream.
- Aggregate event data over user-defined intervals.
- Apply filters for granular event capture.
- Enable estimates of stream index volume.
- Monitor ephemeral (time-limited) streams.
- Create flow protocol streams.
For a list of supported protocols, see Supported protocols in the Splunk Stream Installation and Configuration Manual.
For details on how the streamfwd binary gets configuration data from the Configure Streams UI, see How streamfwd communicates with splunk_app_stream in the Splunk Stream Installation and Configuration Manual.
Create New Stream
The Configure Streams UI provides a wizard that walks you through the process of creating a new stream. In addition to selecting a protocol and fields, the wizard lets you enable aggregation and create filters for the stream.
To create a stream using the New Stream wizard:
- In the Splunk App for Stream (
splunk_app_stream)main menu, click Configure > Configure Streams. The Configure Streams UI opens. - Click New Stream. The Create New Stream wizard workflow appears.
- Under Basic Info, select a Protocol for your new stream. For example, http. Enter a Name and optionally enter a Description. Click Next.
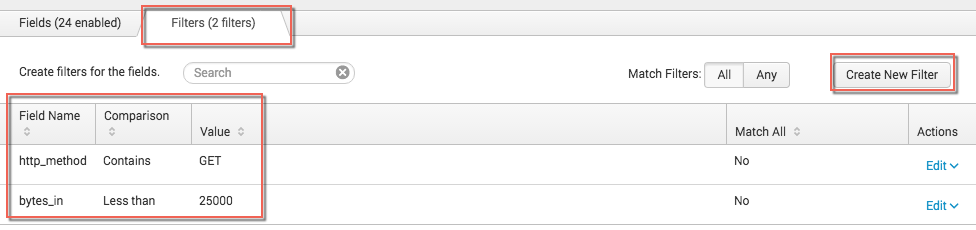
- (optional) Under Aggregation, click Yes, Every. Then enter a time in seconds, for example, 60 seconds. This is the interval over which data aggregation occurs. For more information, see Use Aggregation on this page.
- Click Next.
- Under Fields, select the specific protocol attributes (fields) that you want to capture. For example, dest_ip, src_ip, bytes_in, bytes_out, and so on. If you have enabled aggregation for the stream, you can also optionally change the selected Aggregation type (Key or Aggregated) for any field. Click Next.
- (optional) Under Filters, click Create New Filter. The Create New Filter modal appears. Select the Field for which you want to create the filter, for example, http_method. Next, select the Comparison type. Then, enter the Value. Click Create. Your new filter allows data to pass through based on the condition defined in the filter. For more information on filters, see Create new filter on this page.
- Click Next.
- Under Settings, select the Index to which you want to send captured data. Then choose the Status for the new stream: Enabled, Disabled, or Estimate. Click Next.
- Select the checkbox for the specific forwarder groups to which you want to add this stream. Click Create Stream. This creates the new stream.
- Click Done. This sends your new stream configuration to the
streamfwdbinary onSplunk_TA_streamwhere data capture occurs.
Your new stream appears in the Configure Streams UI.
After you create a new stream, you can apply additional stream capture rules from the Configure Streams UI, including the Top Fields filter, which lets you limit data capture to a specified number of top fields. See Use Aggregation on this page.
You can also define Content Extraction rules that let you define a subset of data to capture from a protocol string field. See Use Content Extraction on this page.
Where are stream configurations stored?
The streams that you configure using the Configure Streams UI are stored in the KV store. You cannot access them from the file system. You can, however, access individual stream configurations in the KV store using the Stream REST API. See /streams/{stream_id} in the Splunk Stream REST API reference.
Set stream mode
To enable data capture for a particular stream, you must set the stream to the Enabled mode. You can set the stream mode in the Configure Stream UI at any time. Choose from the following three modes:
- Enabled: The Enabled mode enables stream data capture and indexing, and generates index volume stats by default.
- Estimate: The Estimate mode generates data index volume stats for any stream, without sending data to indexers. For more information, see Use Estimate mode on this page.
- Disabled: The Disabled mode disables stream data capture and indexing, and disables collection of index volume stats.
On the Configure Streams UI main page, select a mode for any stream:

Select protocol fields
You can select the specific fields that you want to capture for any stream.
- On the Configure Streams main page, select the name of the network protocol that you want to capture.
The Protocol Events page for the selected protocol opens. - Select the Enable checkbox for the specific field(s) you want to add.
- Click Save.

Create new filters
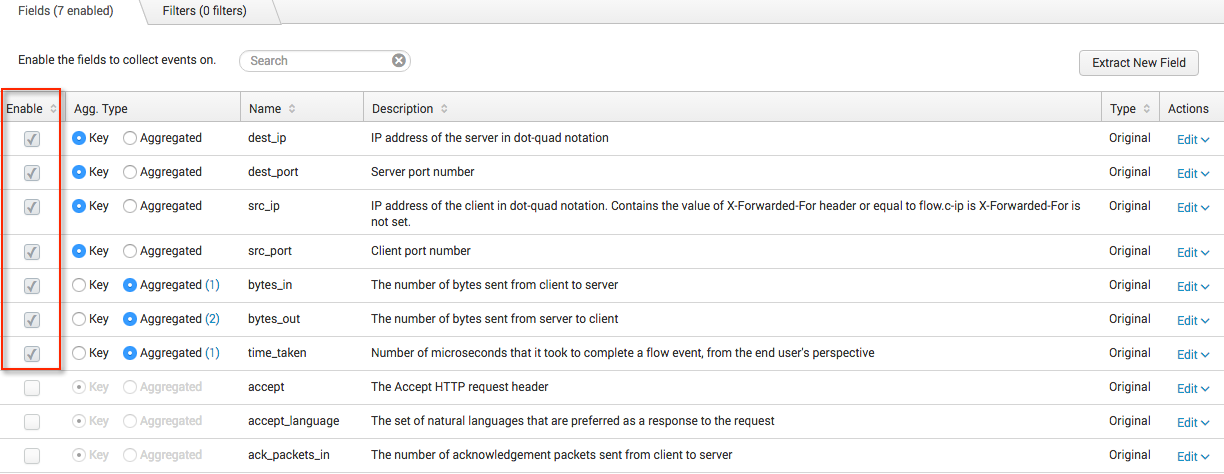
You can add filters to specific fields in a stream that allow data to pass through based on conditions that you define. You define conditions by setting up a comparison, such as "Less than," "Equals," Contains," and so on, between a field name and a specific value. Filter values can be either strings or numeric values.
For example, a filter might specify the condition that the "http_method" field contains the value "GET." If all (or any) http_method events match this condition, the stream event data passes through.
- In the Configure Streams UI, click on the name of the stream.
- Click the Filters tab.
- Click Create New Filter. The Create New Filter modal opens
- In the Field drop-down menu, select the name of the field to which you want to apply the filter. For example, "bytes_in."
- In the Comparison drop-down menu, select the type of comparison you want to use for your filter. For example, "Less than."
- Enter the Value that defines the condition of the comparison. For example, "25000."
- Click Save.
- For Match Filters, select All or Any. This applies to events that return multiple values for a field. If match is set to "All", then all values of the field must satisfy the condition for the filter to engage. If the match is set to "Any", then any value of the field that satisfies the condition causes the filter to engage.
- Click OK.
The app adds the filter to thestreamfwd.confconfiguration file, and the filter now appears in the list of filters for that stream.

Use Aggregation
The Configure Streams UI lets you apply aggregation to stream events over specific time intervals. The app groups events into aggregation buckets, with one bucket allocated for each unique collection of "Key" fields. At the end of the time interval, the app emits an object that represents each bucket.
For example, you might enable aggregation over a 60 second time interval. If you assign Key to the src_ip field and apply the sum aggregate function to the bytes_in field, then for each 60 second interval, the app creates a bucket for each distinct src_ip value it sees, and sums the number of bytes_in over that interval for each bucket.
Aggregation types
You must set each field that you enable for aggregation to one of the following two aggregation types:
- Key: Fields that have aggregation type "Key" are used for grouping data into buckets.
- Aggregated: Fields that have aggregation type "Aggregated" can have one or more aggregate functions applied to them. For a complete list of aggregate functions, see Stream aggregation methods in this manual.
Set up aggregation
- In the Configure Streams UI, click on the name of your stream.
The configuration page for that particular stream opens. - Under Aggregation, click Yes, every, then enter a time in secs.
This enables Aggregation for the particular stream and determines the time interval over which data aggregation occurs. - (optional) Under Top Fields, click Yes, only index top, then enter a number. From the dropdown, you can select
countor any aggregated field which is configured, e.g.sum(bytes_in), as the basis for sorting. - Select the Enable checkbox for each field you want to aggregate.
- Select an Aggregation Type for each enabled field.
- Select Key to use the field for specifying aggregation buckets.
A separate bucket will be generated for each distinct value of the Key field over the selected time interval. - Select Aggregated to enable aggregation for that particular field.
The number of currently selected aggregate functions appears in parentheses. For example, (1). Thesumaggregate function is selected by default.
- Select Key to use the field for specifying aggregation buckets.
- Click on the number in parentheses (x) to select aggregate functions for a particular field.
A modal showing a list of available aggregate functions for that field appears. - Select one or more aggregate functions. Click Save.
- Click Save.

About multiple Key fields
If an aggregate event includes multiple Key fields, Stream looks for unique combinations of values of those fields and creates a separate bucket for each combination.
For example, if you assign Key to the field src_ip and you apply the sum aggregate function to the field bytes_in, then for each time interval, the app creates a bucket for each unique src_ip value that occurs, and sums the number of bytes_in over that interval for each bucket. If you also assign Key to the dest_ip field, the app creates a bucket for each unique pair of src_ip and dest_ip.
For more information, see Stream aggregation methods in this manual.
Use Content Extraction
The Configure Streams UI lets you create content extraction rules to capture and index a specific subset of data from a protocol string field. You can also use content extraction to generate MD 5 hashes or hexadecimal numbers of non-numeric fields.
Content extraction types
Stream supports the following content extraction types:
- Regex
- MD5 hash
- Hexadecimal
Create content extraction rules
You can create content extraction rules that use a regular expression to extract sections of data from a parent field. This lets you capture the specific pieces of data that you require, without indexing extraneous data.
For example, some string fields, such as src_content dest_content, and cookies, contain long strings of data. In many cases, the entire string of data is not useful. Using content extraction rules, you can limit data capture to specific pieces of data, such as a name, ID, account number and so on.
You can also specify a capturing group match, which outputs either the first value that matches the regular expression, or the "list" of all values that match the regular expression. Each content extraction rule creates a new field that captures only that data specified by the rule. The original field is not modified.
To create a content extraction rule:
- In the Configure Streams UI, click on the stream that contains the field from which you want to extract content.
The events page opens for the particular stream. - Click the Actions menu for the particular field, then select Extract New Field.

The Content Extraction dialog appears.
Note: It is not necessary for the original field to be enabled. If you also want to index the original field, consider using a field transformation instead. For more information, see field transformations in the Knowledge Manager Manual. - Enter a name for the content extraction rule. For example, "readable_cookie."
- Enter a description for the content extraction rule. For example, "Separate the cookies into name/value pairs in a readable format."
- In the Extraction Rule field, enter the regular expression for the content that you want to extract. For example, we can use following regular expression to extract a name and value pair from the
cookiefield:(.*?)\=(.*?;)</code>
Note: Stream uses Boost Perl Regular Expression syntax. - Under Match:
- Select First to return only the first value that matches the regex.
- Select All to return the "list" of all values that match the regex.
- In the Extraction Format plain text box, enter the format for the extraction. For example, enter
$1, $2to return the first and second values that match the regex.
This image shows the complete content extraction rule for our "readable_cookie" example: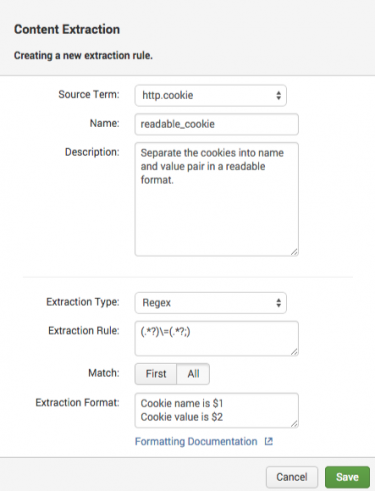
- Click Save.
The new field appears in the list of Fields on the events page for the particular stream.
Splunk search results for the "readable_cookie" field in our example should appear similar to this:



Note: The <MaxEventQueueSize> option in streamfwd.conf determines the maximum number of events that Splunk_TA_stream can queue for delivery to Splunk indexers. By default <MaxEventQueueSize> supports 10k events. To increase or decrease the maximum event queue size, modify the value of <MaxEventQueueSize> in streamfwd.conf. See Configure streamfwd.conf in the Splunk Stream Installation and Configuration Manual.
Extract fields as MD5 hash or hexadecimal
You can use content extraction to generate an MD5 hash or hexadecimal encoding of any non-numeric field for any protocol. MD5 hashes are useful for masking sensitive data in search results, such as user names, passwords, and other important account information. Hexadecimal encoding is useful for representing arbitrary binary data that can interfere with the Splunk search UI.
You can also use file hashing to detect if a specific file is being transmitted over your network, without having to store the entire contents of the file, which might be quite large. For example, you might store the hash of a file (such as a sensitive document or piece of malware), then compare that hash to the hash of email attachments you capture to see if it matches.
Each field that you extract as an MD5 hash or hexadecimal generates a new field. The original field does not need to be enabled. This lets you view a secure fingerprint of the field value in search results, without exposing the original field value.
An MD5 hash is 32 characters long by default. For additional security, you can truncate MD5 hash values to any number of characters, and specify an offset from the 1st character at left.
To extract a field as an MD5 hash:
- Click the Actions menu for the particular field that you want to hash, then select Extract New Field.
- Enter a name for the MD5 hash field that you want generate. For example, "src_content_MD5_hash."
- Enter a description for the new MD5 hash field. For example, "MD5 hash of src_content_field."
- In the Extraction Type menu, select MD5 hash.
- In the Hash Length field, specify the number of characters to use for the hash. Leave blank for default 32 characters.
- in the Hash Offset field, specify the number of characters to offset from 1st character at left. Leave blank for default of 0.
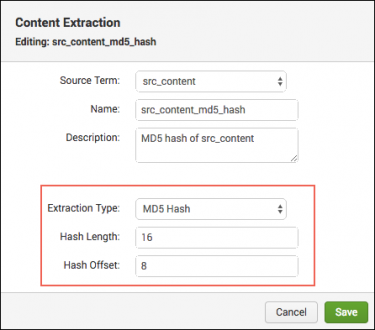
- Click Save.
The new field appears in the list of Fields on the events page for the particular stream.
Splunk search results for the "src_content_MD5_hash" field in our example should appear similar to this: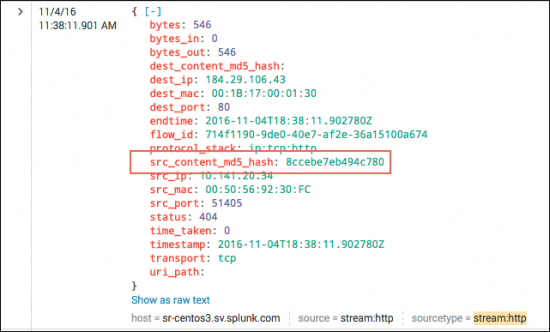


Note: MD5 hash content extraction is pre-configured for specific fields in HTTP and SMTP protocol streams.
Use Estimate mode
When you set a stream to Estimate mode, the app generates index volume stats for the stream, without sending the actual data to your indexers. These index volume stats populate the Stream Estimate dashboard.
Use the Estimate mode and Stream Estimate dashboard to determine the amount of data that a particular stream will ingest. This can help you calculate your indexer requirements, fine-tune your stream capture configurations, and conserve indexer space.
Splunk App for Stream collects index volume stats for all streams in the Enabled mode. All pre-built streams are in Estimate mode by default.
To use Estimate mode:
In the Configure Stream UI, select Mode > Estimate for any stream.
The stream is now in Estimate mode and begins to populate the Stream Estimate dashboard with index volume stats for the specific stream. For more information, see Stream Estimate in this manual.
Create custom (cloned) streams
The Configure Streams UI lets you clone existing streams to create new custom streams. You can use the clone stream feature to create new streams that have additional granularity.
When you clone a stream, the app produces an exact duplicate of the original stream, including all enabled fields and existing filters. You can then add additional filters and capture rules to the stream.
To create a custom (cloned) stream:
- In the Configure Streams UI, click on the name of the stream you want to clone.
The events page for the particular stream opens. - Click Clone.
The Clone Stream dialog appears. - Enter a Name and Description for the new stream. Click OK.
The new stream appears in the list of streams in the Configure Streams UI. - Click Enabled to enable capture for the cloned stream.
- Click Save.
About built-in streams
Splunk App for Stream includes several built-in streams as examples that you can use as a starting point for creating new streams.
The data that built-in streams capture populates the apps Informational dashboards. For more information, see "Informational Dashboards" in this manual.
All built-in streams begin with "Splunk_" in their name. You can view and clone built-in streams in the Configure Streams UI.

Support for ephemeral streams
Ephemeral streams give users of external Splunk apps the ability to schedule stream capture for a user-defined period of time. This is useful if you want to capture and analyze a limited number of network events pertaining to specific network activity or transactions over a specific time interval.
While you must configure and schedule ephemeral stream capture from within the context of the external Splunk app, you can view and perform certain actions on existing ephemeral streams (such as enable/disable) inside the Configure Stream UI.
How ephemeral streams work
Splunk apps that support ephemeral streams take advantage of the Stream REST API. Ephemeral streams are similar to normal streams, but ephemeral streams require two additional parameters, createDate and expirationDate, which specify the stream start and stop times, respectively, in epoch time. For example:
createDate: 1404259338 expirationDate: 1414259338
Splunk app for Stream automatically and permanently deletes the ephemeral stream when the server system time is greater than or equal to expirationDate.
To view ephemeral streams:
In the Configure Streams UI, click Ephemeral Streams. This opens the Stream Buckets page, which displays a list of your existing ephemeral streams.
| Stream field details |
This documentation applies to the following versions of Splunk Stream™: 7.0.0, 7.0.1
Feedback submitted, thanks!