Scaling your Splunk UBA deployment
Install Splunk User Behavior Analytics (UBA) in a single-server or distributed deployment architecture. A distributed deployment helps you scale your Splunk UBA installation horizontally with streaming and batch servers.
The nodes in a distributed Splunk UBA deployment perform a high number of computations among them and require fast network connections. For this reason, do not deploy Splunk UBA across different geographical locations. If you have multiple sites, configure a duplicate Splunk UBA cluster as a warm standby system. See Configure warm standby in Splunk UBA in the Administer Splunk User Behavior Analytics manual.
What size cluster do I need?
Use the parameters below to guide you in properly sizing your Splunk UBA deployment. Exceeding the limits will have a negative impact on performance and can result in events being dropped and not processed.
- The Max events per second capacity represents the peak events rate processed by Splunk UBA when ingesting data from Splunk Enterprise.
- The Max Number of accounts represents the total number of accounts monitored by Splunk UBA, such as user, admin, system, or service accounts.
- The Max Number of devices represents the total number of devices monitored by Splunk UBA.
- The Max number of data sources represents the total number of data source connectors configured on Splunk UBA to ingest data from Splunk Enterprise.
| Size of cluster | Max events per second capacity | Max Number of accounts | Max Number of devices | Max number of data sources |
|---|---|---|---|---|
| 1 node | 4K | up to 50K | up to 100K | 6 |
| 3 nodes | 12K | up to 50K | up to 200K | 10 |
| 5 nodes | 20K | up to 200K | up to 300K | 12 |
| 7 nodes | 28K | up to 350K | up to 500K | 24 |
| 10 nodes | 40K-45K | up to 350K | up to 500K | 32 |
| 20 nodes | 75K-80K | up to 750K | up to 1 Million | 64 |
Engage Splunk engineering if the requirements for your environment exceed the limits listed in the table above. You can use the backup and restore scripts to migrate from your current deployment to the next larger deployment. See Migrate Splunk UBA using the backup and restore scripts in the Administer Splunk User Behavior Analytics manual.
After Splunk UBA is operational, you must perform regular maintenance of your Splunk UBA deployment by managing the number of threats and anomalies in your system. See Manage the number of threats and anomalies in your environment for information about the maximum number of threats and anomalies that should be in your system based on your deployment size.
Example: Sizing a Splunk UBA deployment
The following example shows how to determine the proper deployment for a particular environment:
When performing this action in your own instance, consider identifying your key indexes first, and only running the tstats query on those indexes.
- Use the following
tstatsquery on Splunk Enterprise. This query obtains the EPS statistics for the last 30 days.| tstats count as eps where index=* earliest=-30d@d groupby index, sourcetype _time span=1s | stats count as NumSeconds max(eps) perc99(eps) perc90(eps) avg(eps) as avg_eps by index, sourcetype | addinfo | eval PercentageOfTimeWithData = NumSeconds / (info_max_time - info_min_time) | fields - NumSeconds info* | eval EffectiveAverage = avg_eps * PercentageOfTimeWithData | fieldformat PercentageOfTimeWithData = round(PercentageOfTimeWithData*100,2) . "%" - Export the results to a CSV file. See Export search results in the Splunk Enterprise Search Manual for options and instructions.
- Using a spreadsheet program such as Microsoft Excel, open the CSV file and remove all rows that have data sources that will not be ingested into Splunk UBA. See Which data sources do I need? in the Get Data into Splunk User Behavior Analytics manual to determine the data sources you need to configure. The data sources you need will vary depending on your environment and the content you want to see in Splunk UBA.
- Get a total of the EPS in the 99% and 90% columns. Base your sizing requirements on the 99% column to get the added benefit of providing a cushion of extra nodes.
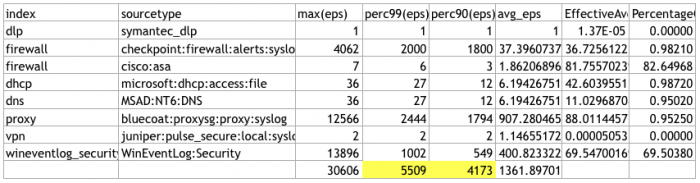

This example has a total EPS in the 99% column over 5,000 and fewer than 10 data sources, meaning that a 3-node deployment is sufficient.
Best practices for optimizing Splunk UBA performance
Splunk UBA performance can vary depending on the number and size of your data sources, indexer and CPU usage, and network throughput. Perform the following to help Splunk UBA run in a more efficient manner:
- Split heavy data sources into smaller data sources
- Calculate potential bandwidth requirements at the TCP level
- Check the load on your Splunk platform indexers
Split heavy data sources into smaller data sources
Each data source in Splunk UBA requires its own TCP connection with the Splunk platform. Splunk UBA performs and scales more efficiently with multiple parallel TCP connections, as opposed to a single large connection. Smaller data sources can help you avoid having any lag during data ingestion. Work with your professional services team to determine the best way to split your data sources.
Calculate potential bandwidth requirements at the TCP level
Use the following formula to determine the minimum bandwidth required for each TCP connection. For example, to calculate the bandwith required to achieve 40K events per second:
Average event size (bytes) * 40K / Number of data sources * 8 / 1024 / 1024
For example, using 410 bytes as the average event size, with 27 data sources, we need 4.6 Mbits per second for each TCP connection:
410 * 40,000 / 27 * 8 / 1024 / 1024 = 4.6 Mbits
Check the load on your Splunk platform indexers
Overloaded indexers on your Splunk platform can cause delays in your data ingestion, or even cause events to be dropped.
See Identify and triage indexing performance problems in the Splunk Enterprise Troubleshooting Manual to begin to troubleshoot indexing performance problems in Splunk software.
| Splunk UBA deployment architecture | Splunk UBA product compatibility matrix |
This documentation applies to the following versions of Splunk® User Behavior Analytics: 5.0.5, 5.0.5.1, 5.1.0, 5.1.0.1, 5.2.0, 5.2.1
Feedback submitted, thanks!