Use Document-based LLM-RAG
Use Document-based large language model retrieval-augmented generation (LLM-RAG) through a set of dashboards.
The following processes are covered:
All the dashboards are powered by the fit command. The dashboards showcase Document-based LLM-RAG functionalities. You are not limited to the options provided on the dashboards. You can tune the parameters on each dashboard, or embed a scheduled search that runs automatically.
Download LLM models
Complete the following steps:
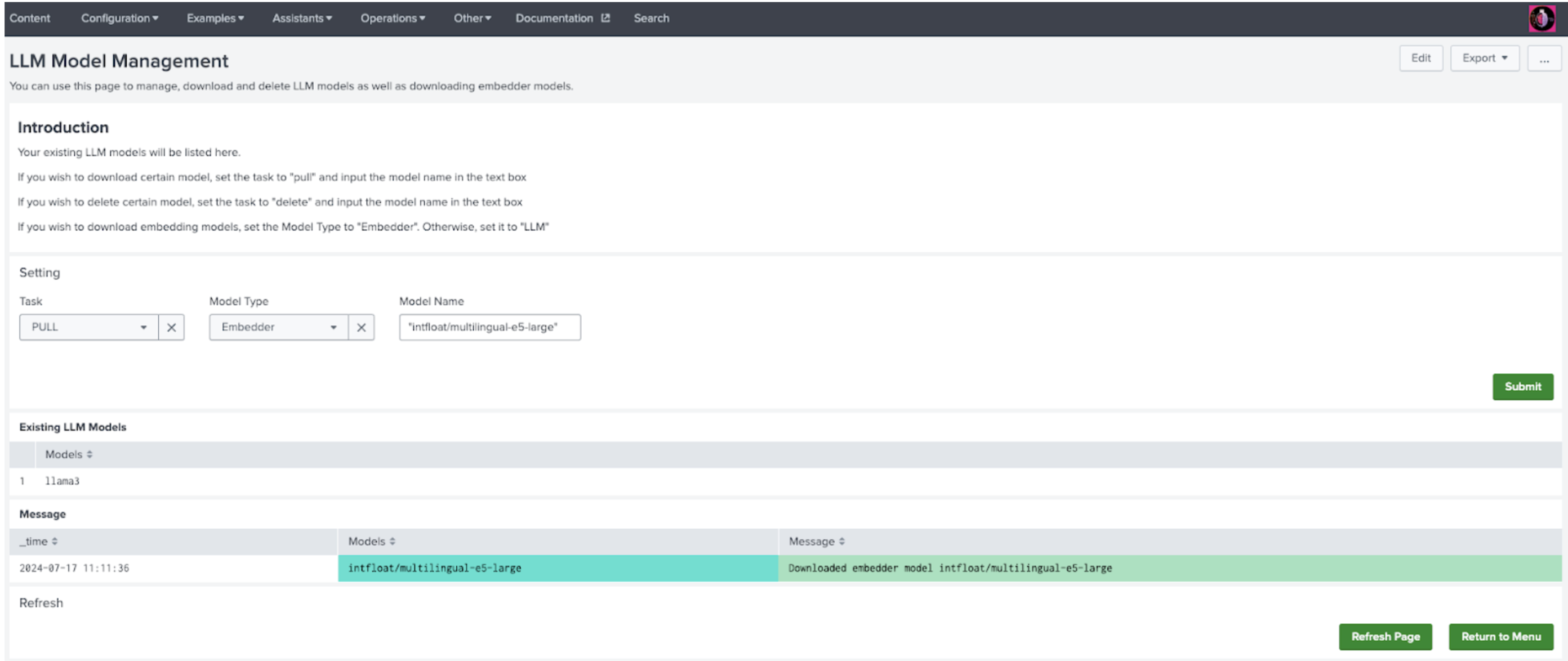
- In the Splunk App for Data Science and Deep Learning (DSDL), navigate to Assistants, then LLM-RAG, then Querying LLM with Vector Data, and then select Manage your LLMs.
- On the settings panel, select PULL from the Task drop-down menu, and select LLM from Model Type, as shown in the following image:

- In the Model Name field, enter the name of the LLM you want to download. For model name references, see the Ollama library page at: https://ollama.com/library
- Select Submit to start downloading. You see an on-screen confirmation after the download completes.
- Confirm your download by selecting Refresh Page. Make sure that the LLM model name is shown on the Existing LLM models panel.

Download embedder models
Complete the following steps:
- In DSDL, navigate to Assistants, then LLM-RAG, then Querying LLM with Vector Data, and then select Manage your LLMs.
- On the settings panel, select PULL from the Task drop-down menu, and Embedder from Model Type.
- In Model Name field, input the namespace of the Huggingface embedder you want to use:
- For English, enter
all-MiniLM-L6-v2 - For Japanese, enter
intfloat/multilingual-e5-large
- For English, enter
- Select Submit to start the download. You see an on-screen confirmation after the download is complete.
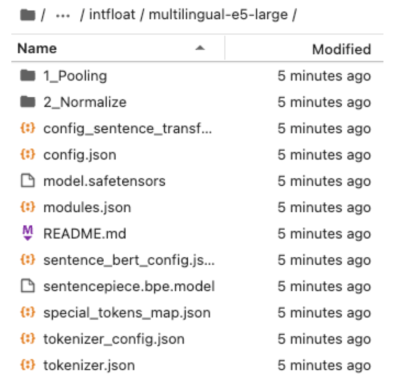
- Confirm the downloads by going to JupyterLab:
- Select the JupyterLab link listed on the container management page.
- Navigate to app, then model, and then data.
- Make sure that a folder with the embedder namespace is created and contains all the model files as shown in the following image:


Encode documents into VectorDB
Complete the following steps:
- Gather the documents you want to encode into a single collection. The supported document extensions are TXT, PDF, DOCX, CSV, XML, and IPYNB.
- Upload the documents through JupyterLab or add the documents to the Docker volume:
Upload option Description JupyterLab Create a folder at any location in JupyterLab, for example notebooks/data/MyData, and upload all the files into the folder. Add the documents to the Docker volume Your files must exist on your Docker host. The Docker volume must be at /var/lib/docker/volumes/mltk-container-data/_data. Create a folder under this example path: /var/lib/docker/volumes/mltk-container-data/_data/notebooks/data/MyData
Copy the documents into this path.
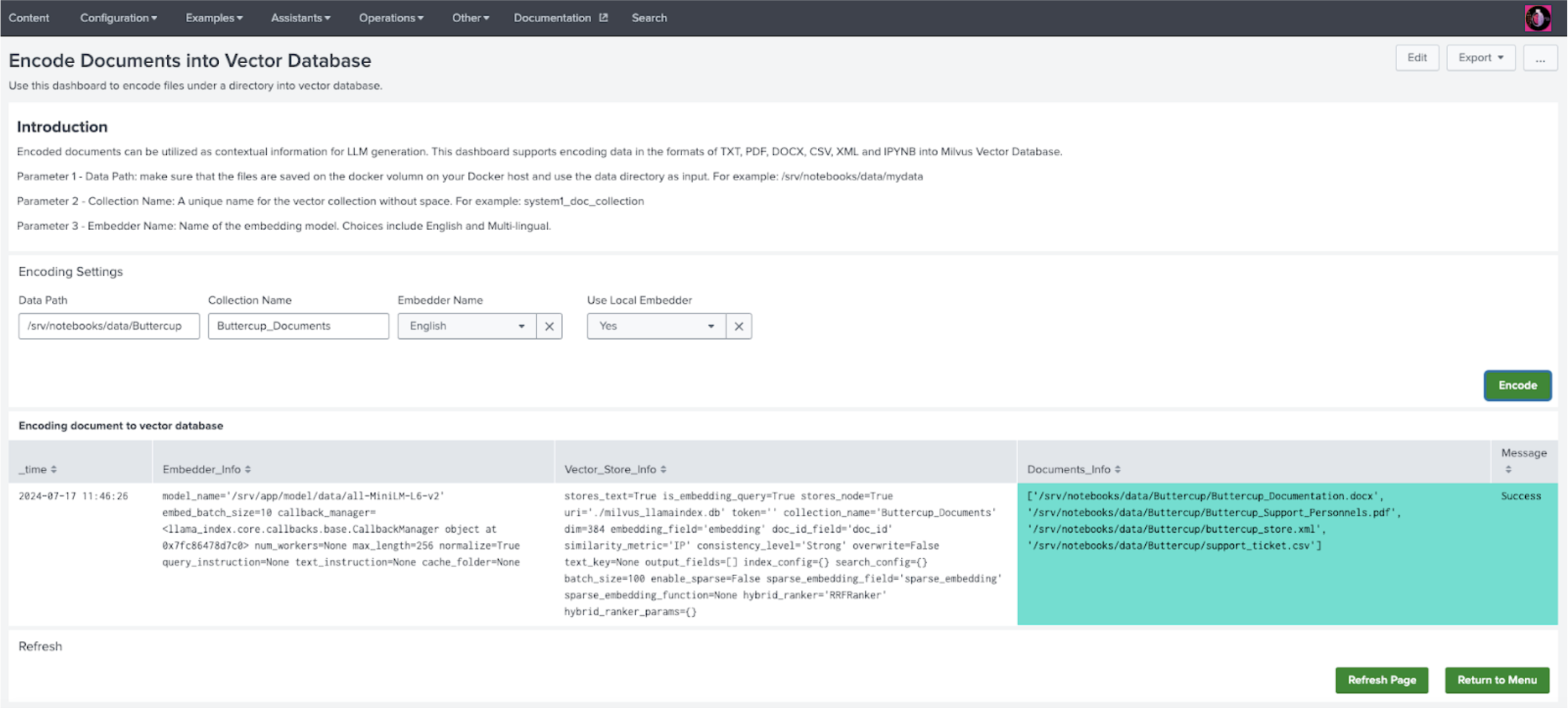
- In DSDL, navigate to Assistants, then LLM-RAG, then Encoding data into Vector Database, and then select Encode documents.
- On the dashboard, input the data path with prefix "/srv". For example, if you have a folder on JupyterLab notebooks/data/Buttercup, your input would be /srv/notebooks/data/Buttercup.
- Create a unique name for a new Collection Name. If you want to add more data to an existing collection, use the existing name.
- For Embedder Name, choose Multi-lingual for non-English data. If you downloaded the embedder models, select Yes to use local embedders.
- Select Encode to start encoding. A list of messages is shown in the associated panel after the encoding finishes.
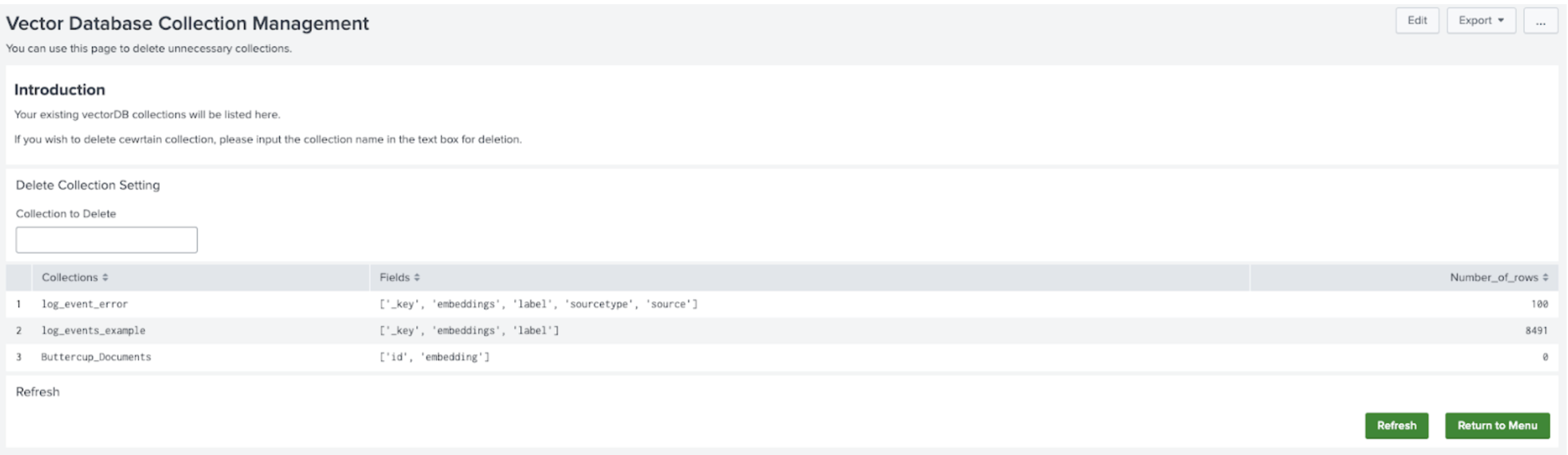
- Select Return to Menu and then select Manage and Explore your Vector Database. You will see the collection listed on the main panel.
It might take a few minutes for the complete number of rows to display.
On this page you can also delete any collection.


Use LLM-RAG
Complete the following steps:
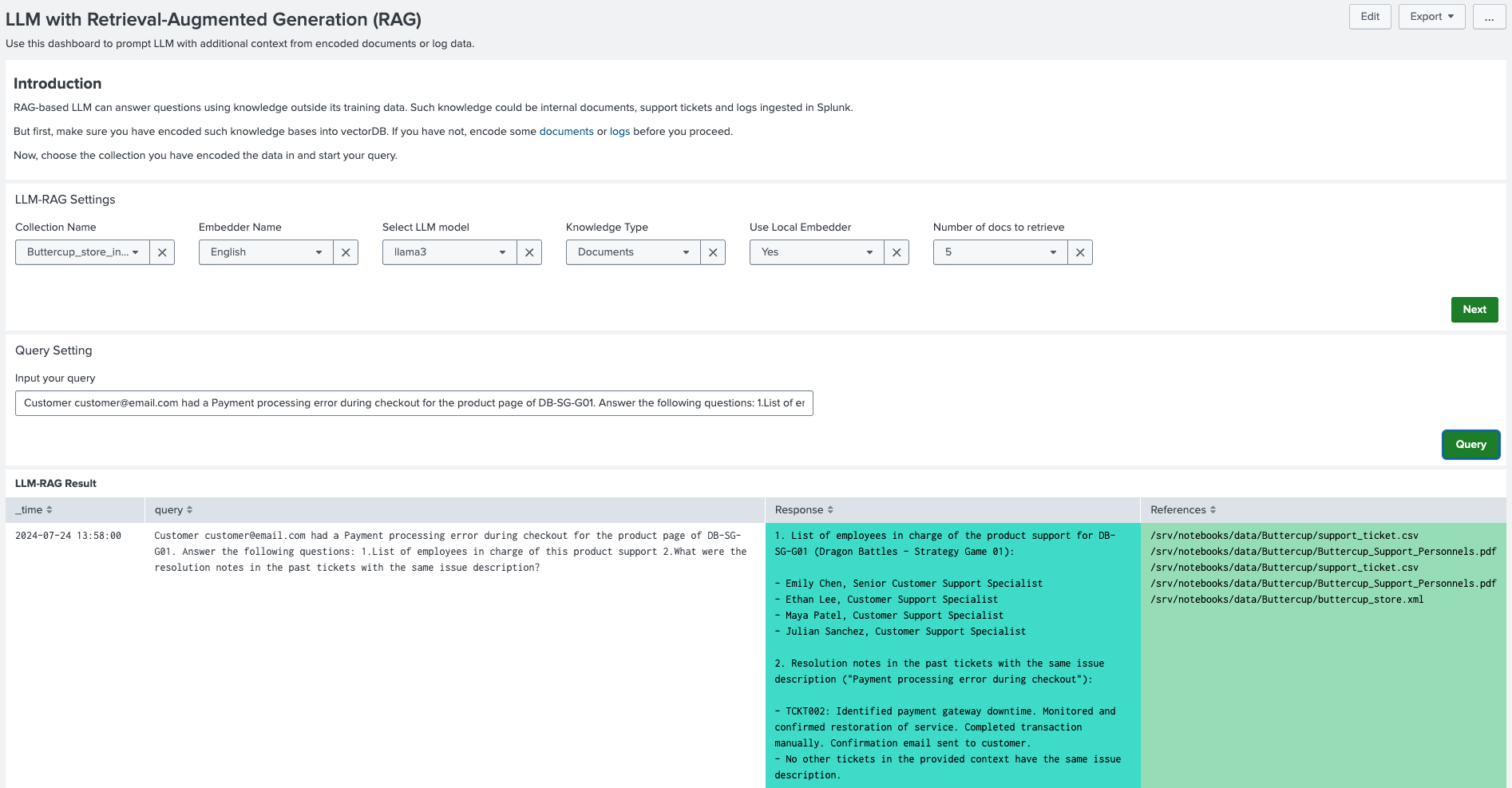
- In DSDL, navigate to Assistants, then LLM-RAG, then Querying LLM with Vector Data, and then select RAG-based LLM.
- In Collection Name, select an existing collection on which you would like to search. Select the same embedder model that you used for encoding.
- For Knowledge Type, select "Documents" as well as a number of pieces of documents to retrieve.
- Select Next to submit the settings.
- An Input your Query field becomes available. Enter your search and select Query as shown in the following image:

| Use Standalone VectorDB | Use Function Calling LLM-RAG |
This documentation applies to the following versions of Splunk® App for Data Science and Deep Learning: 5.2.0
Feedback submitted, thanks!