Use Standalone VectorDB
Use Standalone VectorDB to run a vector search through a set of dashboards. The following processes are covered:
All the dashboards are powered by the fit command. The dashboards showcase Standalone VectorDB functionalities. You are not limited to the options provided on the dashboards. You can tune the parameters on each dashboard, or embed a scheduled search that runs automatically.
Configure embedding models
Complete the following steps:
- Make sure that you have configured the embedding service on the Setup LLM-RAG (optional) page prior to spinning up the container. If you haven't, finish the configuration and restart the container.
- When configuring the embedding service, specify the output dimensionality of the model in the Output Dimensions field.
If you have downloaded local Huggingface embedding models, add the prefix
/srv/app/model/to the Embedding Model Name of your choice.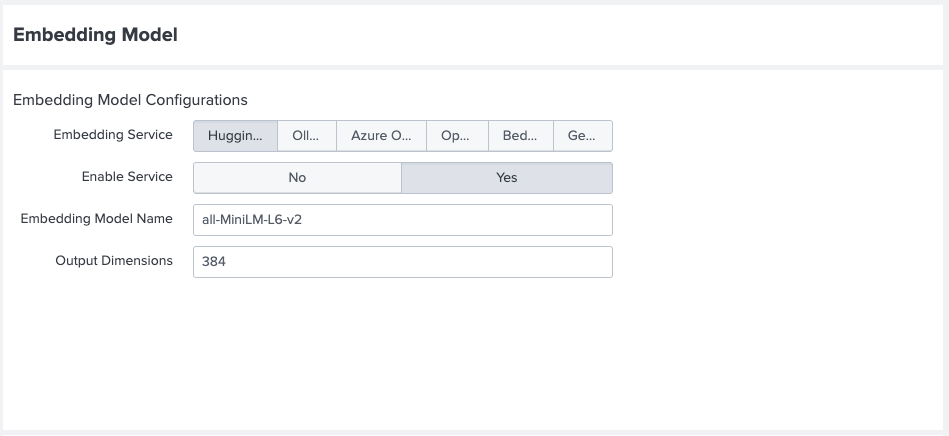
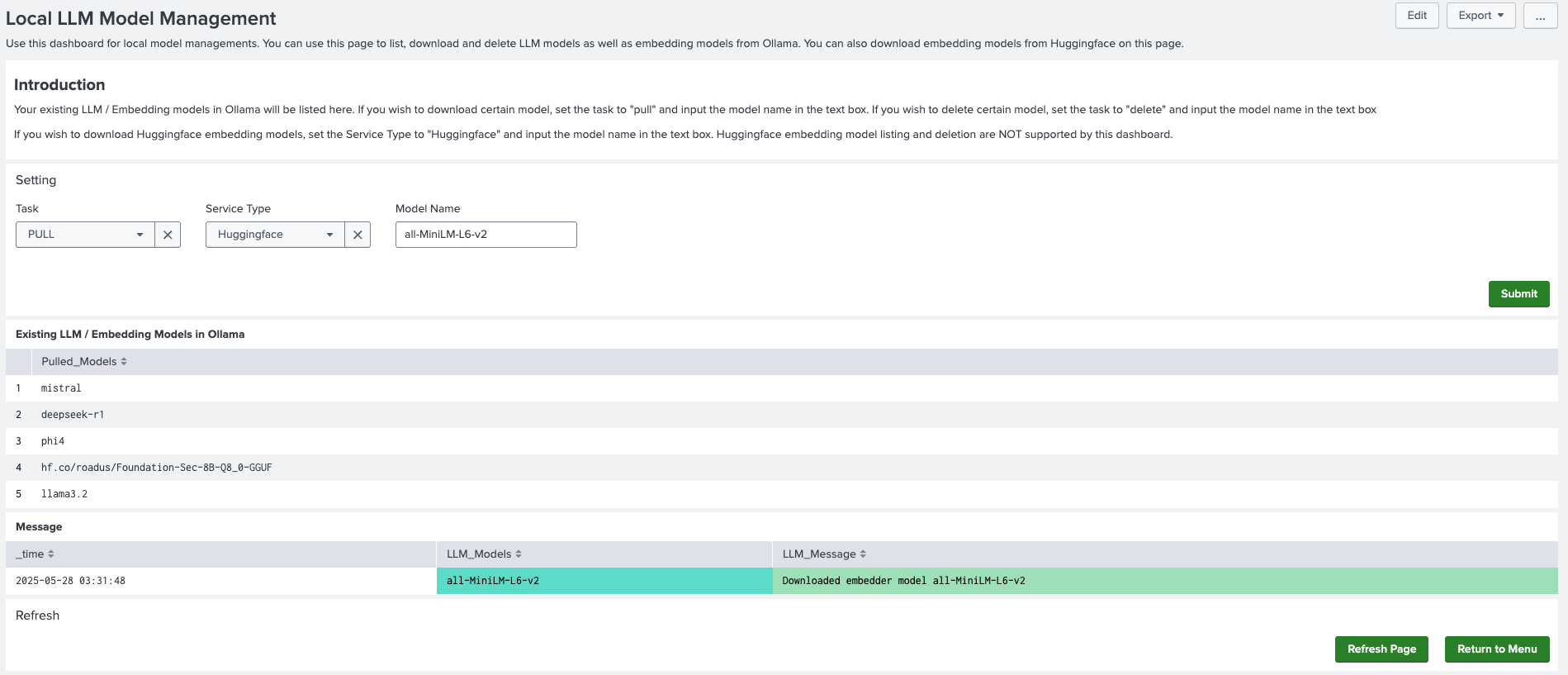
- To download a Huggingface embedding model prior to the configuration, navigate to Assistants, then LLM-RAG, then Querying LLM, and then select Local LLM and Embedding Management.
- On the page, select PULL from the Task drop-down menu and Huggingface from Service Type and input the model name.
- Select Submit to download the embedding model locally.


Encode data into a VectorDB
Complete the following steps to encode Splunk platform data into a VectorDB:
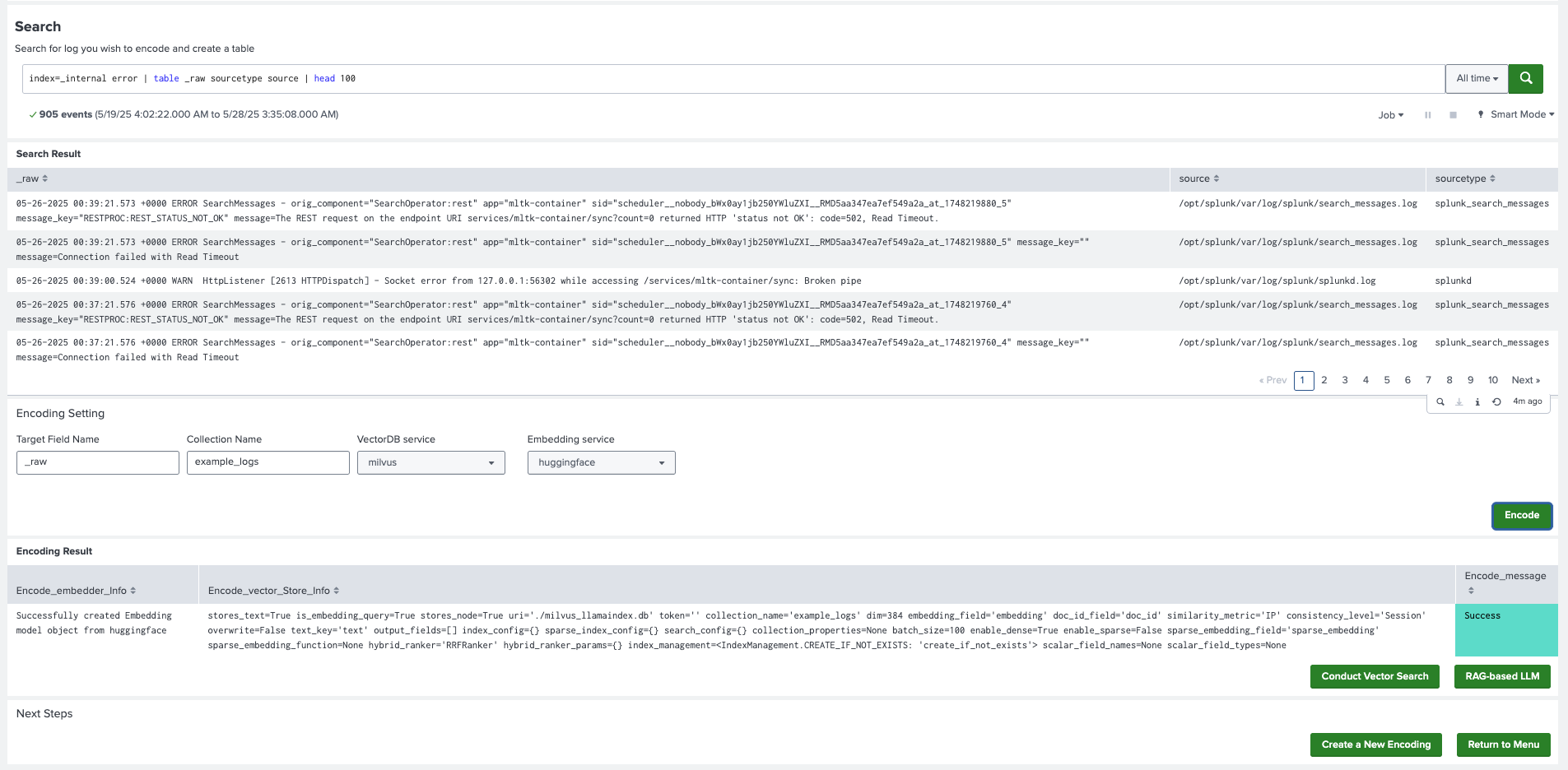
- In DSDL, navigate to Assistants, then LLM-RAG, then Encoding data to Vector Database, and then select Encode data from Splunk.
- On the search bar of the dashboard, search for the data that you want to encode. You have 2 options:
- You can search for data stored in Splunk platform indexes and create a table.
- You can use the
inputlookupcommand to load a lookup table.
- In Target Field Name enter the field name that contains data you wish to encode. For example, enter
_rawfor raw log events.The other fields in the search result are automatically added to the collection as metadata fields stored in plain text.
- Create a unique name for a new Collection Name. If you want to add data to an existing collection, use the existing name.
- For Vector Service and Embedding Service, choose the services you have enabled in the Setup LLM-RAG (optional) page.
- Select Encode to start encoding. A list of messages is shown in the associated panel after the encoding finishes.
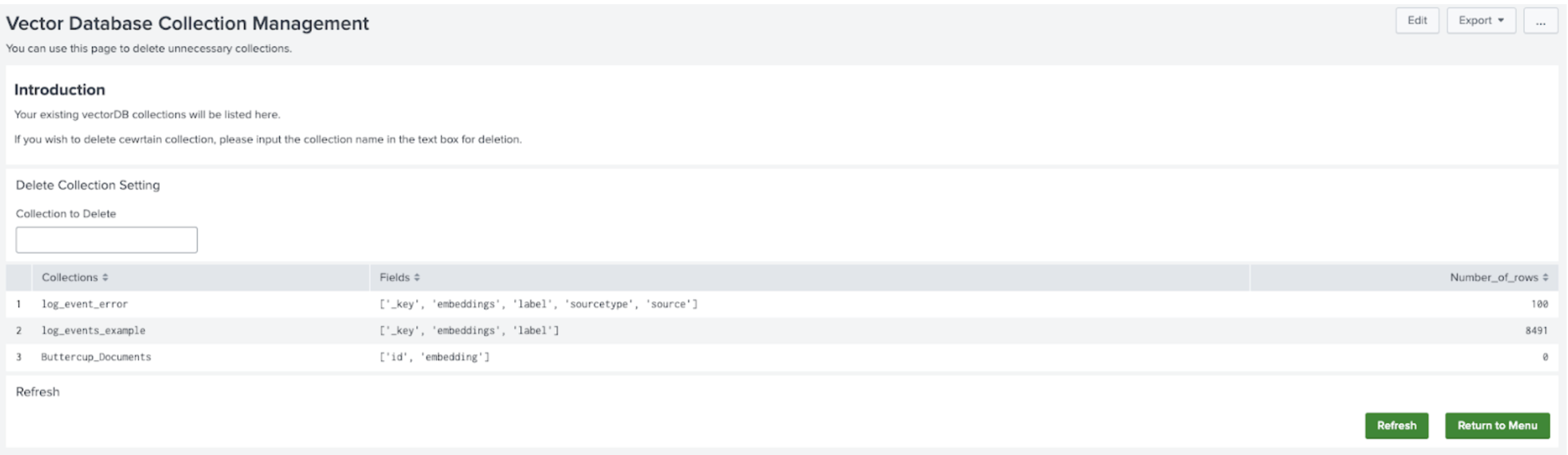
- Select Return to Menu and then select Manage and Explore your Vector Database. You see the collection listed on the main panel.
It might take a few minutes for the complete number of rows to display.
On this page you can also delete any collection.


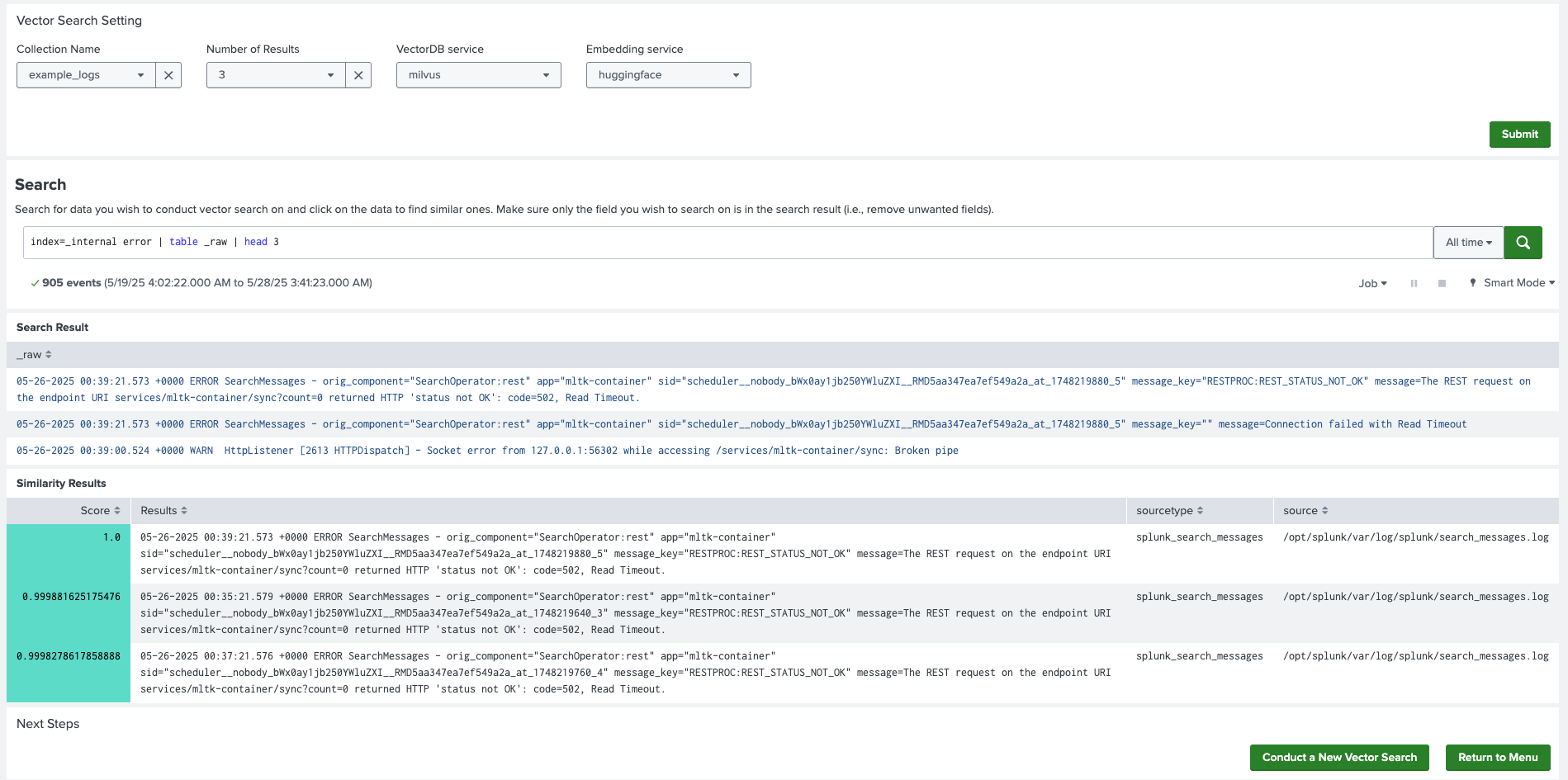
Conduct vector search
Complete the following steps:
- In DSDL, navigate to Assistants, then LLM-RAG, then Encoding data to Vector Database, and then select Conduct Vector Search on Splunk data.
- In Collection Name, select an existing collection on which you want to search. Select the same vector service and embedding service that you used for encoding.
- Select a number for the Number of Results to control the top N results.
- Select Submit to proceed.
- On the search bar, search for data to conduct vector search on. The result should be a table containing only the field you want to search on.
- Select any data to conduct vector search against it. The top N results from the collection are listed in the panel, along with the metadata saved in the collection, as shown in the following image:

| Use Standalone LLM | Use Document-based LLM-RAG |
This documentation applies to the following versions of Splunk® App for Data Science and Deep Learning: 5.2.1
Feedback submitted, thanks!