Key concepts in Splunk RUM 🔗
This topic introduces important terminology and concepts in Splunk RUM for Browser and Splunk RUM for Mobile. Each key concept is linked to an example.
Term |
Definition |
|---|---|
A collection of operations that represents a unique transaction handled by an application and its constituent services. |
|
A single operation within a trace. |
|
A field name that identifies each span in your application. |
|
Made up of a collection of spans and traces. A collection of spans and traces generated in a continuous period of user interaction. |
|
A field name that identifies each session in your application. |
|
A field name that is an attribute of your span. Use tags to filter events. |
|
A session that contains a certain behavior you want to analyze. |
|
Expanded view of each session with waterfall view of events. |
|
A crash happens when a user encounters an error and has to exit the app. |
|
|
|
In Splunk RUM, the error ID is created by hashing the associated stack trace, error message, and error type. |
|
Customized user flows that capture meaningful metrics about customer journeys and user behavior on your site. |
|
Use built-in dashboards to assess application health at a glance. |
|
Global attributes are key-value pairs added to all reported data. |
Session 🔗
A session refers to a group of user interactions on an application for a maximum of 4 hours. A Session begins when a user loads the front-end application and ends when the application is terminated or expires. Sessions expire after 15 minutes of inactivity. The definitions for trace and span are the same in both Splunk RUM and Splunk APM. For more information about traces in APM, see Manage services, spans, and traces in Splunk APM.
Session ID 🔗
The session ID is a field name that identifies each session in your application.
Spans 🔗
A span is a single operation within a trace.
Spans in Splunk RUM for Browser 🔗
A browser span can represent one of the following actions:
Document load
Resource request
UI calls to the back-end or third party resources
User xpath requests and interactions with pages
Custom events
Web vital events
Network errors
JavaScript errors
Spans in Splunk RUM for Mobile 🔗
A mobile span can represent one of the following actions:
Crashes
Network errors
Application errors
Application lifecycle events
Custom events
Back-end and resource requests
Trace 🔗
A trace is a collection of operations that represents a unique transaction handled by an application and its constituent services. The general definition for a trace is the same in both Splunk RUM and Splunk APM.
For example, This image shows a trace represented by a series of multicolored bars labeled with the letters A, B, C, D, and E. Each lettered bar represents a single span. The spans are organized to visually represent a hierarchical relationship in which span A is the parent span and the subsequent spans are its children.
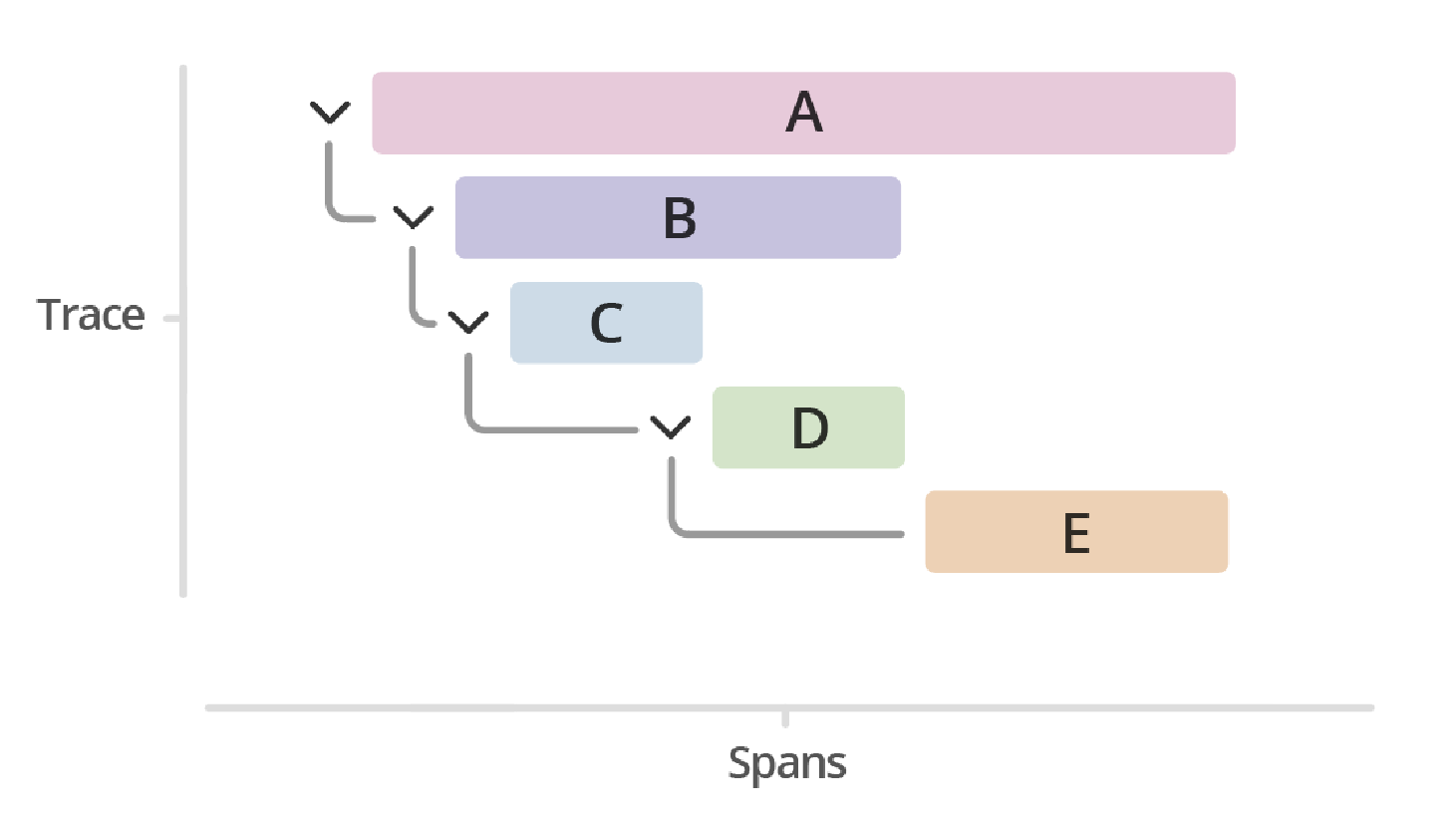
There are two unique kind of traces in Splunk RUM:
Browser traces
Back-end traces
Browser trace 🔗
A browser trace is a collection of spans that specifically represents activity on the browser, such as an XHR request or a document load.
Back-end trace 🔗
Back-end traces are collections of back-end spans. Backend-spans are calls that microservices make to each other, such as an account service making a request to a database.
User sessions 🔗
A User session is a session that contains a certain behavior you want to analyze.
For example, suppose you want to see the slowest load time for the web vital LCP. Then, you can open a User session like in the following image.

Session details 🔗
In session details you can search by session ID and toggle between raw and parsed views of the session.
Raw: All of the information available for the session.
Parsed: A curated view of the custom tags and unique values excluding all default tags and XHR requests.
Span ID 🔗
A span ID is a field name that identifies each span in your application. A span ID can represent:
browser spans
mobile spans
back-end spans
Tag 🔗
A tag is a field name that is an attribute of your span that you can use to filter events. An example of a tag is a property about the user, such as the operating system or the browser the user uses to view your application. The definition for tags and span tags are the same in both Splunk APM and Splunk RUM. In Splunk APM, tags are called span tags. For more, see Analyze services with span tags and MetricSets in Splunk APM.
RUM metrics for mobile applications 🔗
Splunk RUM for Mobile uses a set of metrics to measure the health of your application, such as app startup times, error rates, and crash rates. For more, see Splunk RUM metrics reference in the Splunk RUM metrics reference.
App start 🔗
In Splunk RUM for Mobile, app start is when the app is responsive and the user can interact with the app. For example, when a user opens your application, it might take a few milliseconds or seconds to initialize the code or application before app start and then the OS reports that the app is responsive.
App crashes and errors 🔗
A crash happens when a user encounters an error and has to exit the app. App errors are all other types of errors that occur but don’t result in the user having to exit the app. For example ANR (application not responding).
Presentation transition 🔗
Presentation transitions are screen transitions and screen changes, such as when a user goes from the login screen to the home screen. Splunk RUM for mobile captures transitions in fragments and view controllers for Android and iOS respectively.
RUM metrics for browser applications 🔗
Splunk RUM for Browser uses these metrics to measure the health of your application. For more, see Splunk RUM metrics reference in the Splunk RUM metrics reference.
Web vitals 🔗
Web Vitals are made up of three metrics that measure user experience:
LCP (largest contentful paint)
CLS (cumulative layout shift)
INP (Interaction to next paint)
Google uses web vitals to determine page ranking. Splunk RUM automatically measures Web Vital metrics. To learn more about web vitals, see https://web.dev/vitals/ in the Google developer documentation.
Errors 🔗
Splunk RUM collects metrics on Javascript and network errors.
Error ID 🔗
The error ID uniquely identifies a specific error. The error ID can represent:
Hash ID of a stack trace
Hash ID of a message
Hash ID of the error type
Custom events 🔗
Create custom logic to capture a specific workflow that is important to your organization to understand through a custom event. Custom events support filtering by tags and the ability to add custom attributes. For more, see Create custom events.
Built-in dashboards 🔗
Built-in dashboards offer charts, metrics, and aggregations about your applications. For more, see Splunk RUM dashboards
Global attributes 🔗
Global attributes are useful for reporting app or user-specific values as tags. You can set global attributes either at the time of library initialization, or afterwards. For more, see Search for global attributes.