Configure algorithm performance costs
Running machine learning algorithms impacts your Splunk platform performance costs. Machine learning requires compute resources, run-time, memory, and disk space. Each machine learning algorithm has a different cost, complicated by the number of input fields you select and the total number of events being processed.
The Machine Learning Toolkit's mlspl.conf file controls the settings for the ML-SPL commands of fit and apply. This mlspl.conf file ships with conservative default settings to prevent the overloading of a search head. The default settings for the file are set to intelligently sample down to 100K events.
On-premises Splunk platform users with admin permissions can configure the default settings of the mlspl.conf file on the default directory, or make edits using the in-app Settings tab. Changes can be made across all algorithms, or for individual algorithms. Splunk Cloud Platform users must create a support ticket to make changes to the mlspl.conf file.
Edit default settings in the mlspl.conf file
Admin users can edit the settings of the mlspl.conf file located in the default directory.
Prerequisite
To avoid losing your configuration file changes when you upgrade the app in the future, create a copy of the mlspl.conf file with only the modified stanzas and settings. Save the copy to $SPLUNK_HOME/etc/apps/Splunk_ML_Toolkit/local/ or %SPLUNK_HOME%\etc\apps\Splunk_ML_Toolkit\local\ depending on your operating system.
Access and edit the mlspl.conf file
Perform the following steps to access and edit the default algorithm settings:
- Access the default directory with the file path that corresponds to your operating system:
- For *nix based systems: $SPLUNK_HOME/etc/apps/Splunk_ML_Toolkit/default/mlspl.conf
- For Windows systems: %SPLUNK_HOME%\etc\apps\Splunk_ML_Toolkit\default\mlspl.conf
- For *nix based systems: $SPLUNK_HOME/etc/apps/Splunk_ML_Toolkit/default/mlspl.conf
- In the mlspl.conf file, specify default settings for all algorithms, or for an individual algorithm. To apply global settings, use the [default] stanza. To apply algorithm-specific settings, use a stanza named for the algorithm. For example, use [LinearRegression] for the LinearRegression algorithm.
Not all global settings can be set or overwritten in an algorithm-specific section. For further information, see How to edit a configuration file in the Splunk Enterprise Admin Manual.
You must close and relaunch the Splunk platform for any mlspl.conf setting changes to take effect.
Available fields in the mlspl.conf file
The following fields can be edited within the mlspl.conf file provided you have admin permissions:
Setting name Default value Description max_inputs100000 The maximum number of events an algorithm considers when fitting a model. If this limit is exceeded and use_samplingis true, thefitcommand down samples its input using the Reservoir Sampling algorithm before fitting a model. Ifuse_samplingis false and this limit is exceeded, thefitcommand throws an error.use_samplingtrue Indicates whether to use Reservoir Sampling for data sets that exceed max_inputsor to instead throw an error.max_fit_time600 The maximum time, in seconds, to spend in the "fit" phase of an algorithm. This setting does not relate to the other phases of a search such as retrieving events from an index. max_memory_usage_mb1000 The maximum allowed memory usage, in megabytes, by the fitcommand while fitting a model.max_model_size_mb15 The maximum allowed size of a model, in megabytes, created by the fitcommand. Some algorithms such as SVM and RandomForest might create unusually large models, which can lead to performance problems with bundle replication.max_distinct_cat_values100 The maximum number of distinct values in a categorical feature field, or input field, that will be used in one-hot encoding. One-hot encoding is when you convert categorical values to numeric values. If the number of distinct values exceeds this limit, the field will be dropped, or excluded from analysis, and a warning appears. max_distinct_cat_values_for_classifiers100 The maximum number of distinct values in a categorical field that is the target, or output, variable in a classifier algorithm.
Edit default settings in-app
You can edit the default algorithm settings through the Settings tab of the Machine Learning Toolkit.
You must have admin permissions to make setting changes.
Perform the following steps to access and edit the Settings tab:
- In your Splunk platform instance, choose the Machine Learning Toolkit app.
- From the main navigation bar, choose the Settings tab.
- On the resulting Algorithm Settings page, edit all algorithm settings, or settings for a specific algorithm:
- Choose the Edit Default Settings button in the top right of the page change settings across all algorithms.
- Select the name of an individual algorithm to change the settings for that particular algorithm.
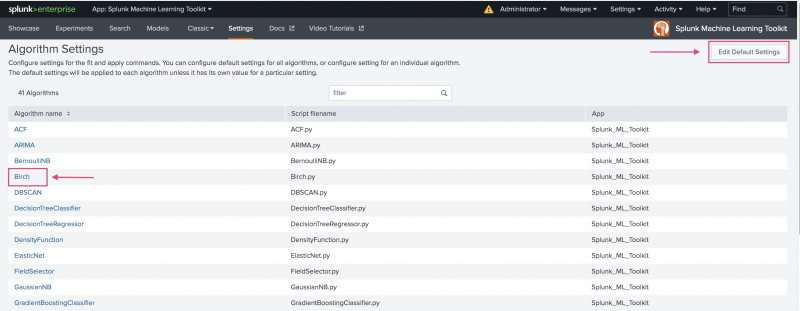
- On the edit settings page, hover over any field name for additional information. Make changes to one or more fields as needed.
- Click Save when done.


You must close and relaunch the Splunk platform for any mlspl.conf setting changes to take effect.
Available fields on the in-app Settings page
The following fields are available to edit across all algorithms offered in the MLTK:
This table does not include fields that are only available for certain algorithms. For example, only DensityFunction offers a default_prob_threshold field.
Field name Default value Description handle_new_catdefault Action to perform when new value(s) for categorical variable/ explanatory variable is encountered in partial_fit. Default sets all values of the column that correspond to the new categorical value to zeroes. Skip skips over rows that contain the new value(s) and raises a warning. Stop stops the operation by raising an error.max_distinct_cat_values100 The maximum number of distinct values in a categorical feature field, or input field, that will be used in one-hot encoding. One-hot encoding is when you convert categorical values to numeric values. If the number of distinct values exceeds this limit, the field will be dropped, or excluded from analysis, and a warning appears. max_distinct_cat_values_for_classifiers100 The maximum number of distinct values in a categorical field that is the target, or output, variable in a classifier algorithm. max_distinct_cat_values_for_scoring100 Determines the upper limit for the number of distinct values in a categorical field that is the target (or response) variable in a scoring method. If the number of distinct values exceeds this limit, the field will be dropped (with an appropriate error message). max_fit_time600 The maximum time, in seconds, to spend in the "fit" phase of an algorithm. This setting does not relate to the other phases of a search such as retrieving events from an index. max_inputs100000 The maximum number of events an algorithm considers when fitting a model. If this limit is exceeded and use_samplingis true, thefitcommand downsamples its input using the Reservoir Sampling algorithm before fitting a model. Ifuse_samplingis false and this limit is exceeded, thefitcommand throws an error.max_memory_usage_mb1000 The maximum amount of memory in megabytes that can be used by the fitcommand when computing the model.max_model_size_mb15 The maximum allowed amount of space in megabytes that the final model as created by the fitcommand is allowed to take up on disk. Some algorithms such as SVM and RandomForest, might create unusually large models, which can lead to performance problems with bundle replication.max_score_time600 The maximum time, in seconds, to spend in the "score" phase of an algorithm. streaming_applyfalse This setting has been deprecated. Leave the default setting as False to prevent bundle replication performance issues on index clusters. use_samplingtrue Indicates whether to use Reservoir Sampling for data sets that exceed max_inputsor to instead throw an error.
The streaming_apply field has been deprecated and is scheduled for removal from the Settings tab. Leave the default setting as False to prevent bundle replication performance issues on index clusters.
| Algorithm support of key ML-SPL commands quick reference | Scoring metrics in the Machine Learning Toolkit |
This documentation applies to the following versions of Splunk® Machine Learning Toolkit: 5.2.0, 5.2.1, 5.2.2, 5.3.0
Feedback submitted, thanks!