Scenario: Kai fixes a detector that misfires alerts 🔗
Kai, a site reliability engineer at Buttercup Games, is creating a new detector and wants to receive an alert whenever their server latency is higher than 260 milliseconds. Kai considers latency lower than 260 milliseconds as healthy for their service, so they want to get alerts when latency exceeds that threshold.
Reduce excessive alerts 🔗
Kai creates a detector to report on latency by following these steps:
In the Detectors & SLOs page, Kai selects New Detector.
Kai selects Infrastructure or Custom Metrics Alert Rule.
Kai enters the signal they want to alert on:
latency.Kai selects the Static Threshold alert condition.
In the Alert settings tab, Kai enters a threshold of 260 milliseconds.
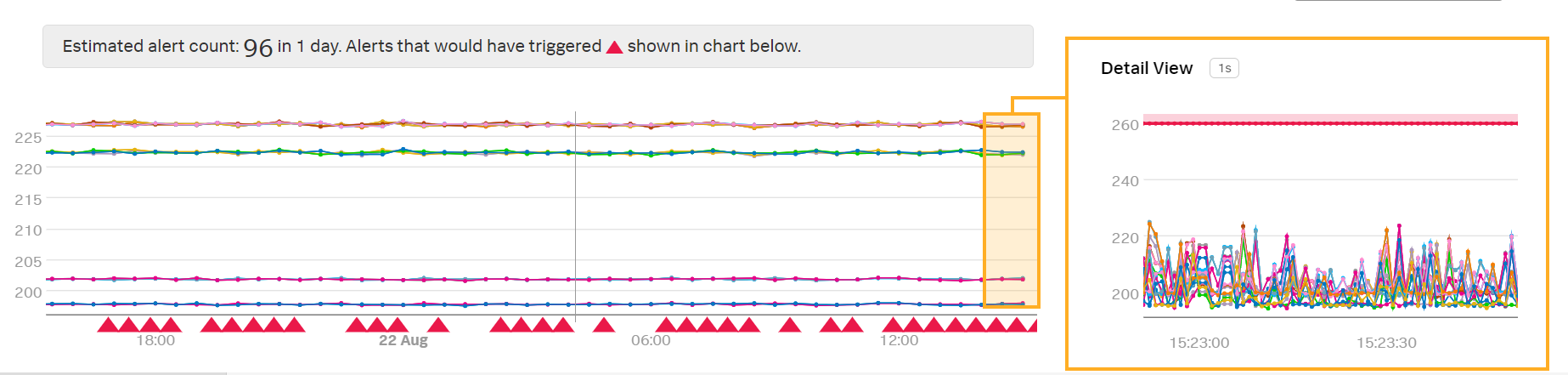
In the preview detector, Kai notices that this alert condition will trigger a very large number of alerts:
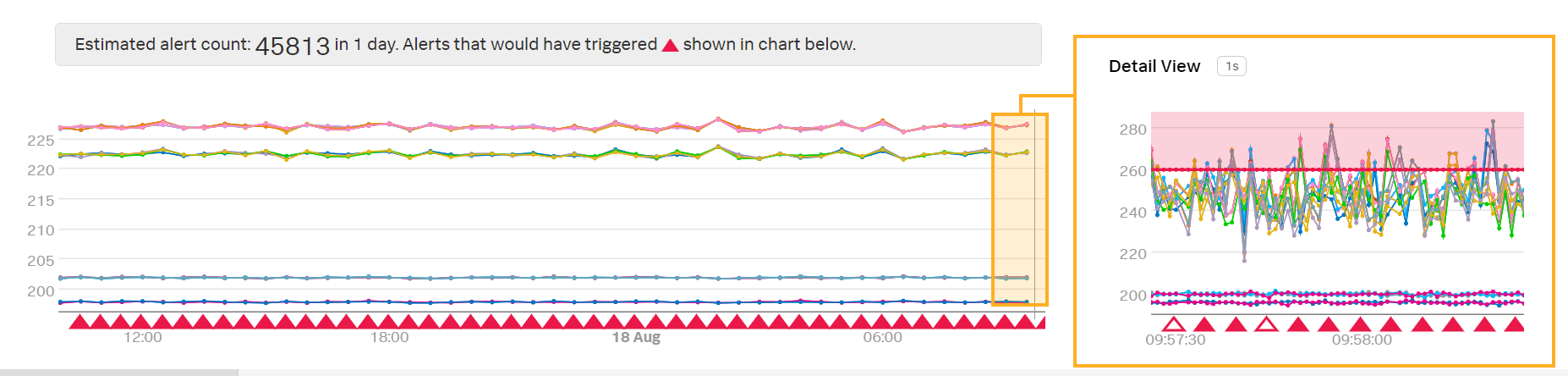
When looking at the native resolution of the data in the Detail View, Kai sees that occasional spikes in latency cause alerts to fire. Kai would prefer that an alert only fires when the latency is high for a longer period of time, such as when latency is over 260 milliseconds for at least 1 minute.
Kai modifies the detector by following these steps:
In the Alert settings menu, Kai selects Trigger sensitivity.
Kai selects Duration.
In the Duration box, Kai enters 1m.
The detector will only trigger an alert if every data point from latency is higher than 260 milliseconds for 1 minute. This alert condition reduces the number of alerts that Kai receives:
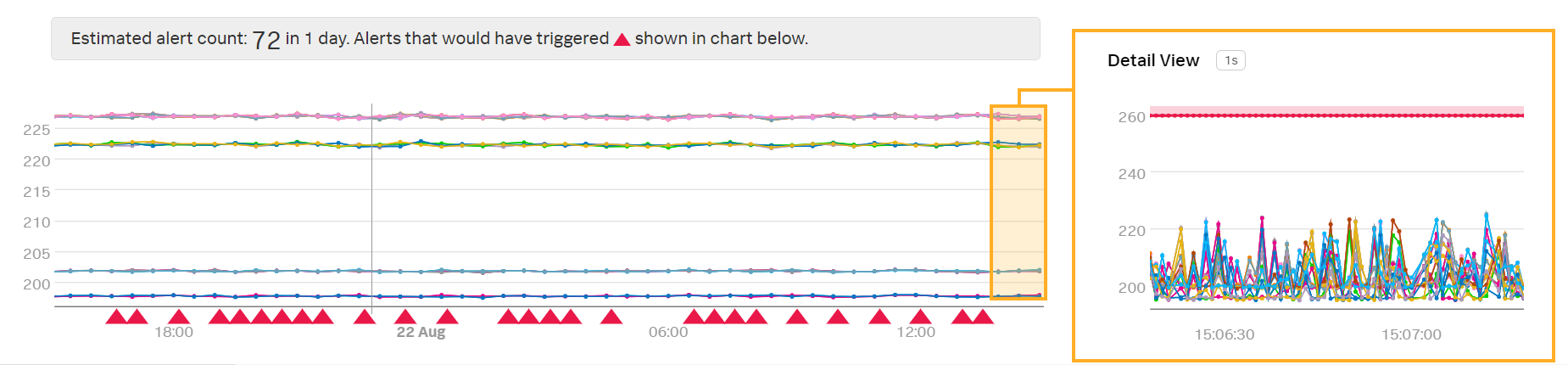
Troubleshoot missing alerts 🔗
After creating their detector, Kai notices that their detector is not triggering alerts even when Kai thinks it should have.
Kai notices some of the data points are not appearing in the preview. For their alert to trigger, every data point must arrive on time and exceed the threshold during the 1 minute duration.
Kai has three options for fixing the missing data point problem:
Change extrapolation policy
Apply aggregation to the metric
Use percent of duration
Change extrapolation policy 🔗
Kai can change the extrapolation policy of the data to account for missing data points. Kai follows these steps:
In the detector menu, Kai selects Alert signal.
Kai selects the settings icon for the latency signal.
Under Advanced Options, Kai selects Extrapolation Policy.
Kai selects Last Value.
Kai’s metric will now report the last data point received whenever the expected data point does not arrive on time.
Kai sees a preview detector with the new extrapolation policy:
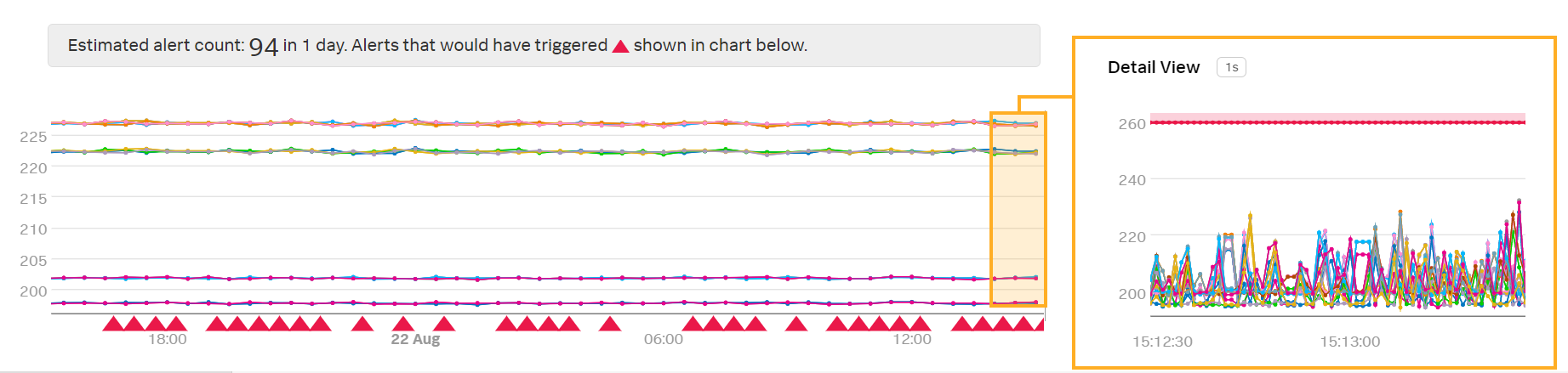
Note
While Last Value is useful for handling the occasional missing data point, if your data point has a lot of missing data points, you may end up firing unwanted alerts when a lot of the data points are extrapolated.
Apply aggregation to the metric 🔗
Kai can change how the metric is reported by adjusting metric analytics. Kai follows these steps:
In the detector menu, Kai selects Alert signal.
Kai selects Add Analytics for the latency signal.
Kai selects Mean, then Mean:Aggregation.
Kai’s detector reports on the mean of all latency values, which accounts for missing data points of individual server machines.
Kai sees a preview detector with the Mean:Aggregation analytic applied:
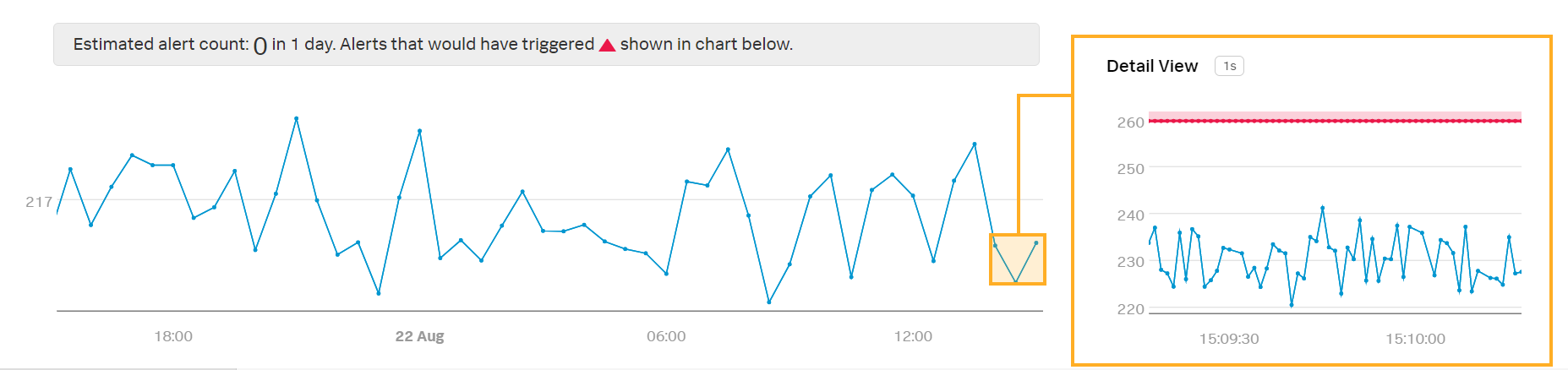
Note
This detector takes the mean of all latency values, so Kai might not receive an alert when an individual server machine exhibits a high latency. Kai might have to adjust their alert condition threshold to account for the change in the preview.
Use percent of duration 🔗
Kai can account for missing data points by using a percent of duration alert setting. Kai follows these steps:
In the detector menu, Kai selects Alert settings.
Kai selects Trigger sensitivty.
Kai selects percent of duration.
Kai enters the percentage of their duration they would like to trigger an alert. Kai enters 80.
The detector triggers an alert when 80% of the data points receieved in a 1 minute period are over 260 milliseconds. Since Kai’s latency data arrives every 10 seconds, there should be 6 data points every minute. To trigger the alert, 5 out of the 6 data points need to arrive and need to be higher than 260 milliseconds.
Kai sees a preview detector with the new alert setting applied:
Note
If Kai has a large number of missing data points, the detector still might not trigger an alert when Kai expects it to. In this case, Kai should find out why the data points are missing or use other methods to account for missing data points, such as extrapolation.
To learn more about troubleshooting missing data points, see Troubleshoot timestamp issues.
Summary 🔗
In this scenario, Kai filtered out unwanted alerts by changing the alert settings.
Kai also explored three options for fixing a detector that did not fire alerts when expected:
Change extrapolation policy
Apply aggregation to the metric
Use percent of duration
Learn more 🔗
To learn more about troubleshooting detectors, see Troubleshoot detectors in Splunk Observability Cloud.