Splunk Infrastructure Monitoring でナビゲーターを使用する 🔗
Splunk Infrastructure Monitoring では、ナビゲーターはリソースのコレクションであり、サービスのさまざまなインスタンスにわたってメトリクスとログを監視し、主要なパフォーマンスナビゲーターに基づいてインスタンス集団の外れ値を検出することができます。ナビゲーター内のリソースには、エンティティの完全なリスト、ダッシュボード、関連するアラートとディテクター、サービスの依存関係が含まれますが、これらに限定されません。
すべてのナビゲーターを確認する 🔗
すべてのナビゲーターを表示するには、Splunk Observability Cloud ホームページから Infrastructure を選択します。
Infrastructure Monitoring のランディングページでは、各カードがナビゲーターを表し、Splunk Observability Cloud で監視するサービスに対応しています。ナビゲーターカードは、母集団内のインスタンス数を表示し、その母集団にリンクする重要なアラートをハイライトします。
ドリルダウン 🔗
ヒートマップビューでは、ナビゲーターで四角にカーソルを合わせると、四角で表されたインスタンスに関する情報が表示されます。四角をクリックすると、そのインスタンスにドリルダウンできます。
または、テーブルビューで、インスタンスのインスタンスIDをクリックして、そのインスタンスにドリルダウンすることもできます。
例えば、ホストインスタンスを表す四角をクリックすると、ビルトインダッシュボードでシステムメトリクス情報をチャート付きで見ることができます。また、[プロパティ]サイドバーで、ホストのさまざまなプロパティ、ホスト上で実行されているプロセスなどを確認できます。
注釈
要素の色や統計は、ドリルダウンしたり、システム内をクリックしたりすると変化することがあります。これは、ナビゲーションを開始してからターゲット要素が表示されるまでの間に、情報が更新される可能性があるためです。
1つのインスタンスにドリルダウンすると、パンくずトレイルを使用して別のインスタンスのドリルダウンビューに切り替えたり、ナビゲータービューに戻ったりできます。
ダッシュボードセクションを使用する 🔗
ダッシュボード セクションには、表示されているインスタンスの詳細情報にアクセスできるビルトインダッシュボードが含まれています。
ナビゲーターのダッシュボードは‑の読み取り専用なので、直接変更を加えることはできません。ただし、組み込みダッシュボードをクローンしてそのクローンに変更を加えたり、組み込みダッシュボードをダウンロードすることはできます。管理者として、カスタムダッシュボードを追加または削除したり、使用しない組み込みダッシュボードを非表示にしたりすることもできます。
詳細については、内蔵ダッシュボード ドキュメン トのナビゲーターの内蔵ダッシュボードを複製する および ナビゲーターの内蔵ダッシュボードをエクスポートする を参照してください。
注釈
Amazon EC2、GCP Compute Engine、Azure Virtual Machinesインスタンスは、それぞれのパブリック クラウドサービスと Splunk Distribution of OpenTelemetry Collector によって動いています。ビルトインダッシュボードでデータを表示するには、すべてのチャートにこの両方が必要です。
パブリック クラウドサービスとスマートエージェントのみが構成されている場合、Amazon EC2、GCP Compute Engine、およびAzure Virtual Machinesインスタンスのビルトインダッシュボードの一部のチャートにはデータが表示されません。
パブリック クラウドサービスのみを構成している場合、データの送信元サービスを表すすべてのカードが表示されますが、Amazon EC2、GCP Compute Engine、Azure Virtual Machinesインスタンスのビルトインダッシュボードの一部のチャートにはデータが表示されません。
Smart Agentのみを設定している場合、Amazon EC2、GCP Compute Engine、Azure Virtual Machinesのインスタンスナビゲーターは利用できません。
グローバルデータリンクを表示する 🔗
デフォルトでは、Splunk Infrastructure Monitoringは自動的に グローバルデータリンク を作成し、ナビゲーターテーブルビューと Metadata タブに表示します。
Metadata タブに表示されるグローバルデータリンクを追加設定するには、グローバル・データリンクを使用して、メタデータを関連リソースにリンクする を参照してください。
メタデータを表示する 🔗
テーブルまたはヒートマップビューで、単一のインスタンスを選択し、Metadata タブを選択すると、インスタンスに関連するタグとメタデータが表示されます。
依存関係を表示する 🔗
テーブルビュー、ヒートマップビュー、またはシングルインスタンスビューで、Dependencies タブを選択し、次の依存関係を追跡します:
Kubernetes コンテナ。
ホスト( My Data Center ホスト、仮想ホスト、Amazon EC2、Azure Virtual Machines、Google Cloud Platform ホスト)。
Kubernetes コンテナまたはホスト上で動作しているサービス。
以下の表は、Dependencies タブに表示される内容をナビゲーター別に説明したものです:
ナビゲーター |
依存関係タブに表示される内容 |
|---|---|
Kubernetesナビゲーター |
Kubernetes エンティティで稼働しているサービスとホスト |
ホストナビゲーター |
|
その他のナビゲーター |
サービスが実行されている Kubernetes エンティティまたはホスト。 |
ベストプラクティス 🔗
Dependencies タブを最大限に活用するには、Splunk Distribution of OpenTelemetry Collector設定ファイルで追跡したいサービスを extraDimensions の下に service.name の値として設定します。 service.name 値を設定することで、特定のホストインスタンスで実行されている個々のサービスなど、データの詳細を確認できます。
例 🔗
例えば、redis-cart サービスは、この Splunk Distribution of OpenTelemetry Collector 設定に含まれています。
receiver_creator:
receivers:
smartagent/redis:
rule: type == "pod" && name contains "redis"
config:
type: collectd/redis
host: redis-cart
port: 6379
extraDimensions:
service.name: redis-cart
Splunk Distribution of OpenTelemetry Collector の設定の詳細については、Collector コンポーネント を参照してください。
ナビゲーターを使ってアラートを表示する 🔗
サービスに有効なアラートがある場合、ナビゲーターを通じてサービスのアラート一覧を表示できます。
Splunk Observability Cloud ホームページから Infrastructure を選択します。
表示するナビゲーターを検索してください。
ナビゲーターのタイトルの下で、アラートの数を表示するテキストを選択します。アラートの数とタイプはナビゲーターによって異なります。
以下のナビゲーターの例では、ユーザーは 90 Critical alerts を選択しています。
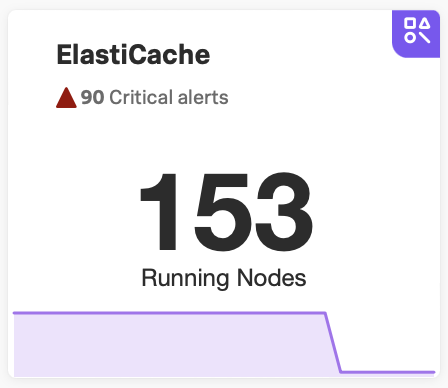
このテキストを選択すると、ナビゲーターの詳細ビューが開き、サイドバーにアクティブなアラートのリストが表示されます。
アラートを使用してナビゲーターを表示する 🔗
アラートを調査しているとき、そのアラートを表示しているモーダルウィンドウの Next Steps セクションの Infrastructure を一目で参照できます。このセクションには、関連するインフラストラクチャモニタリングナビゲーターへのリンクが表示されます。そのリンクを選択すると、アラートからのコンテキスト メタデータを失うことなくナビゲーターを開くことができます。該当するメタデータは、アラートからナビゲーターに自動的に渡されます。
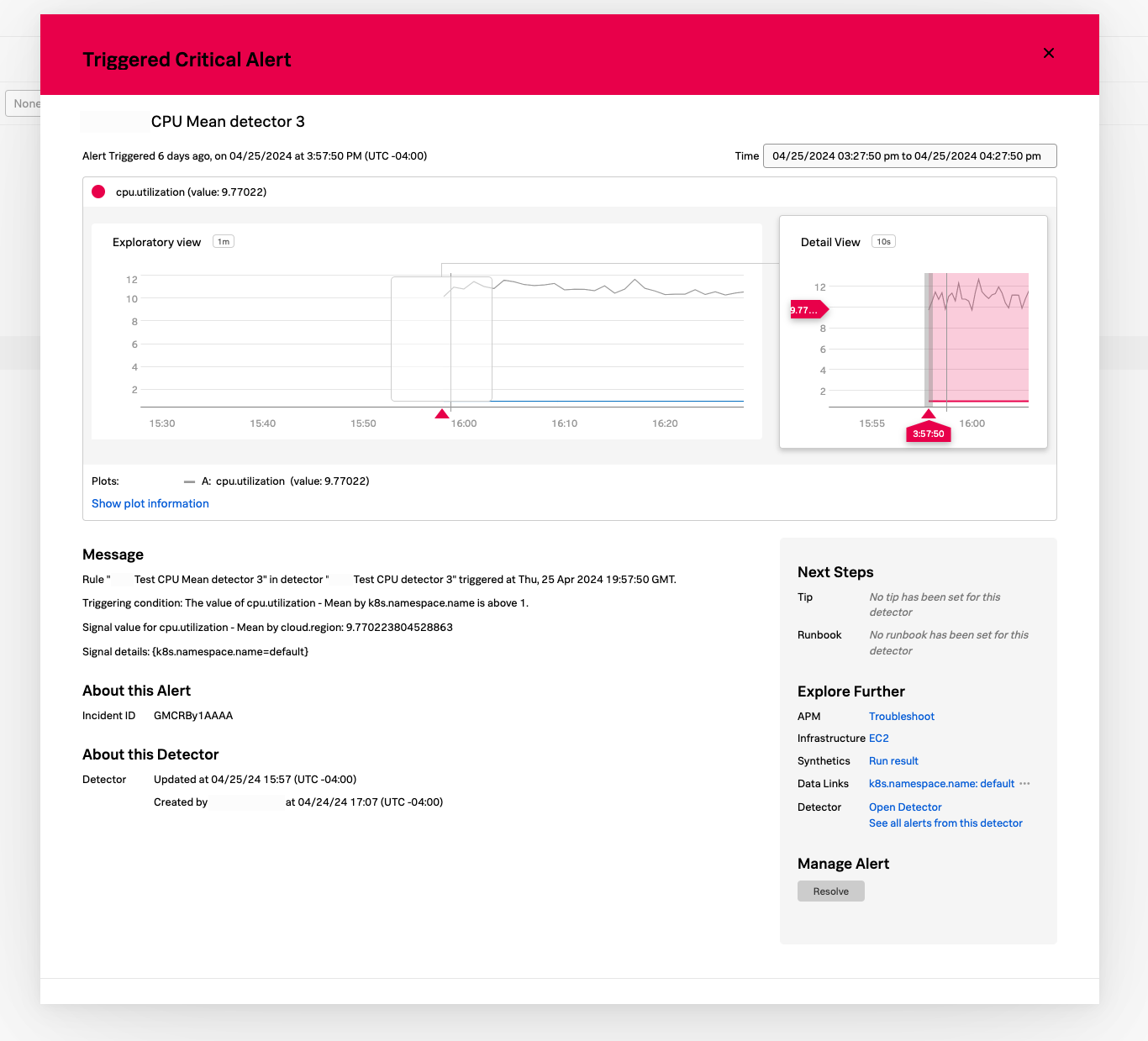
アラートからナビゲーターに渡される可変データには、アラートが発生した時刻のほか、アラートに関連するメトリクスやプロパティが含まれます。
アラートとそのトリガーとなったナビゲーターをリアルタイムでリンクさせることで、「アラートからナビゲーターへ」というエクスペリエンスがトラブルシューティングを迅速化します。
非アクティブなナビゲーターを削除する 🔗
注釈
ナビゲーターを削除するには管理者である必要があります。
インテグレーションのデータが 72 時間受信されないと、そのインテグレーションのナビゲーターは非アクティブになり、表示から削除するオプショ ンがあります。インテグレーションは、インテグレーションのデータが再び受信されると自動的に再表示されます。
非アクティブなナビゲーターを削除するには、以下の手順に従います。
Splunk Observability Cloud ホームページから Infrastructure を選択します。ナビゲーターを削除できるのは、Infrastructure Monitoring ランディングページビューにいるときだけです。
非アクティブなナビゲーターで、Remove Navigator を選択します。
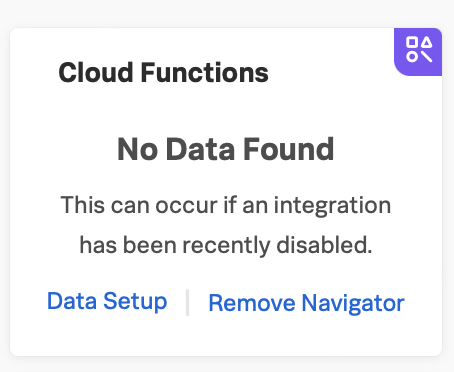
選択を確認します。