シナリオ:KaiがKubernetesナビゲーターを使用してサーバー障害のトラブルシューティングを行う 🔗
以下のシナリオは、架空のeコマース企業であるButtercup Gamesの例です。
Buttercup Games のサイト信頼性エンジニア (SRE) である Kai は、Kubernetes 環境の Web サーバーの監視を担当しています。この1 時間、Kai は Apache ウェブサーバーが Splunk Observability Cloud でデータを表示しなくなったことに気づきました。他の Web サーバーはすべてデータを送信し続けているため、Kai は Apache 固有の問題ではないかと疑っています。
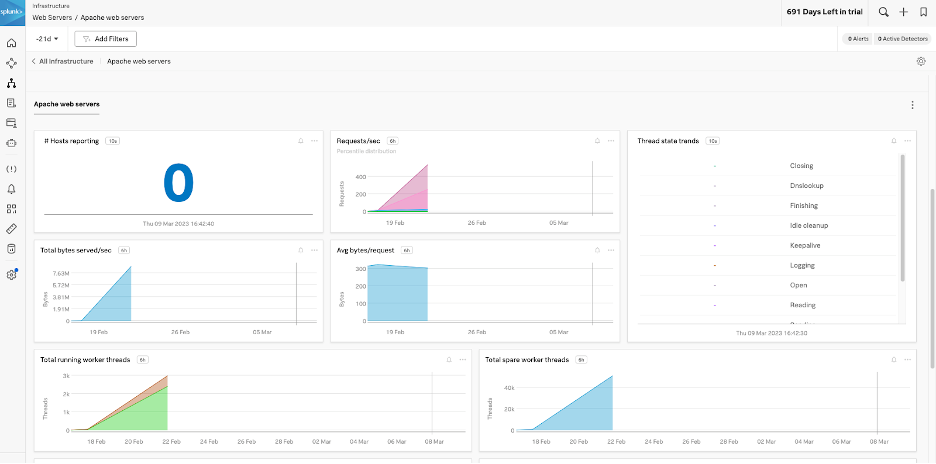
サービスの依存関係を調べる 🔗
さらに詳しく調査するため、Kai は Apache のサービス依存関係を調べています。
Kai はApacheナビゲーターからKubernetesノードナビゲーターに切り替えると、すぐにいくつかのKubernetesポッドが実行されていないように見えることに気づきます。
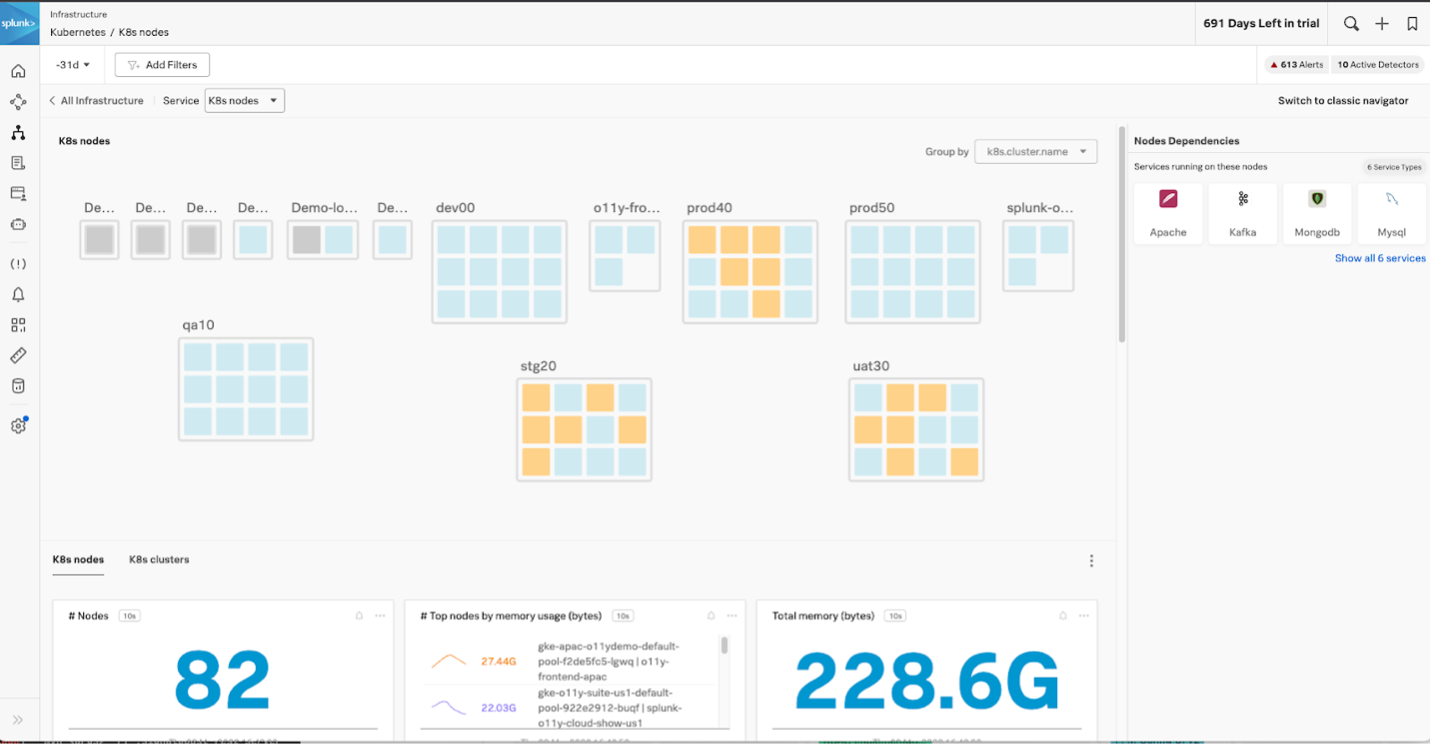
問題箇所を特定する 🔗
階層マップを使用して、Kaiは適切なクラスタにドリルダウンし、障害が発生しているポッドのあるノードを特定します。Kaiは、ポッドが failed の状態であることがわかります。
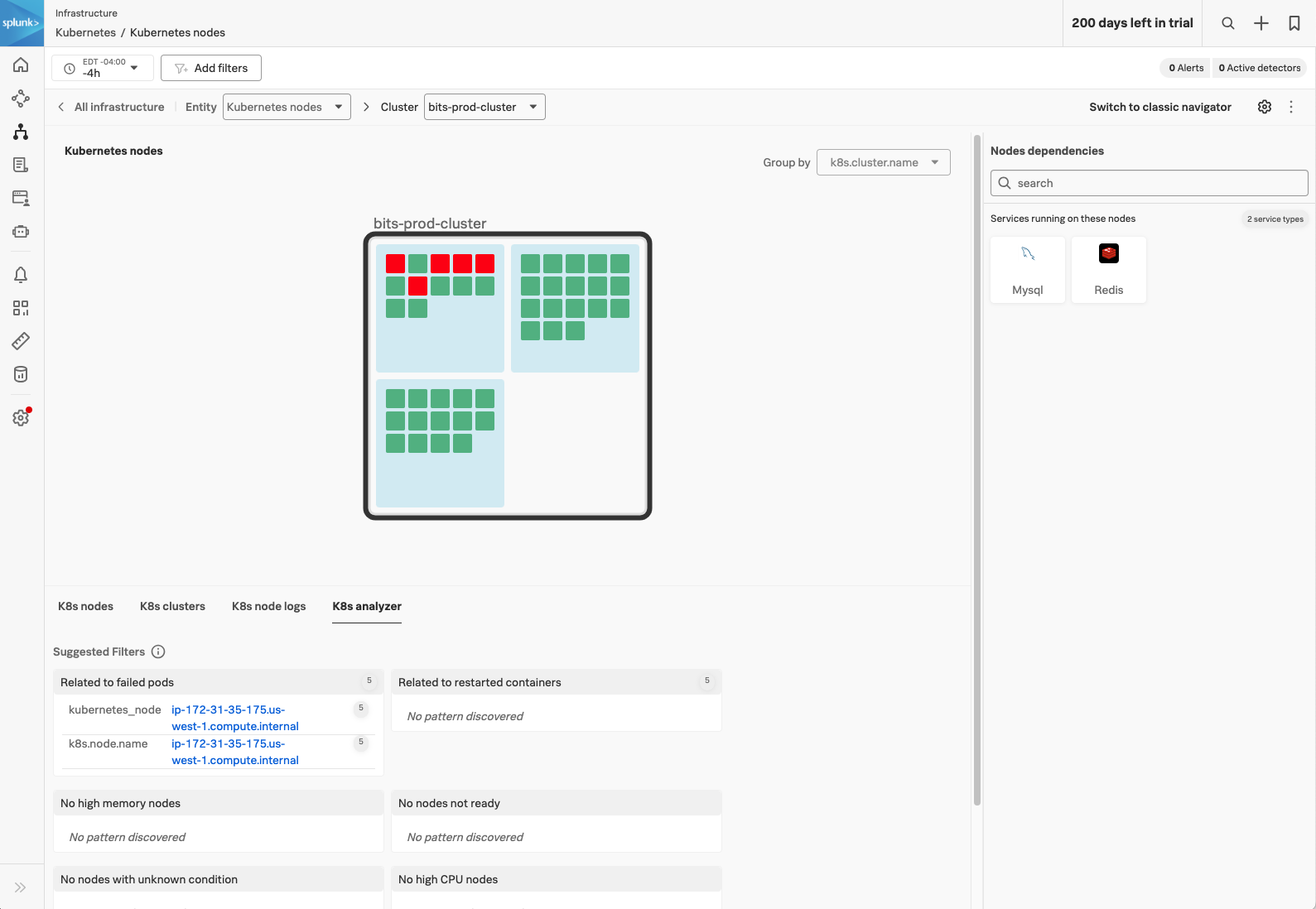
Splunk Observability アカウントチームの助けを借りて、Kai は Pending ポッドのメモリ制限が正しく設定されておらず、起動できないことを突き止めました。
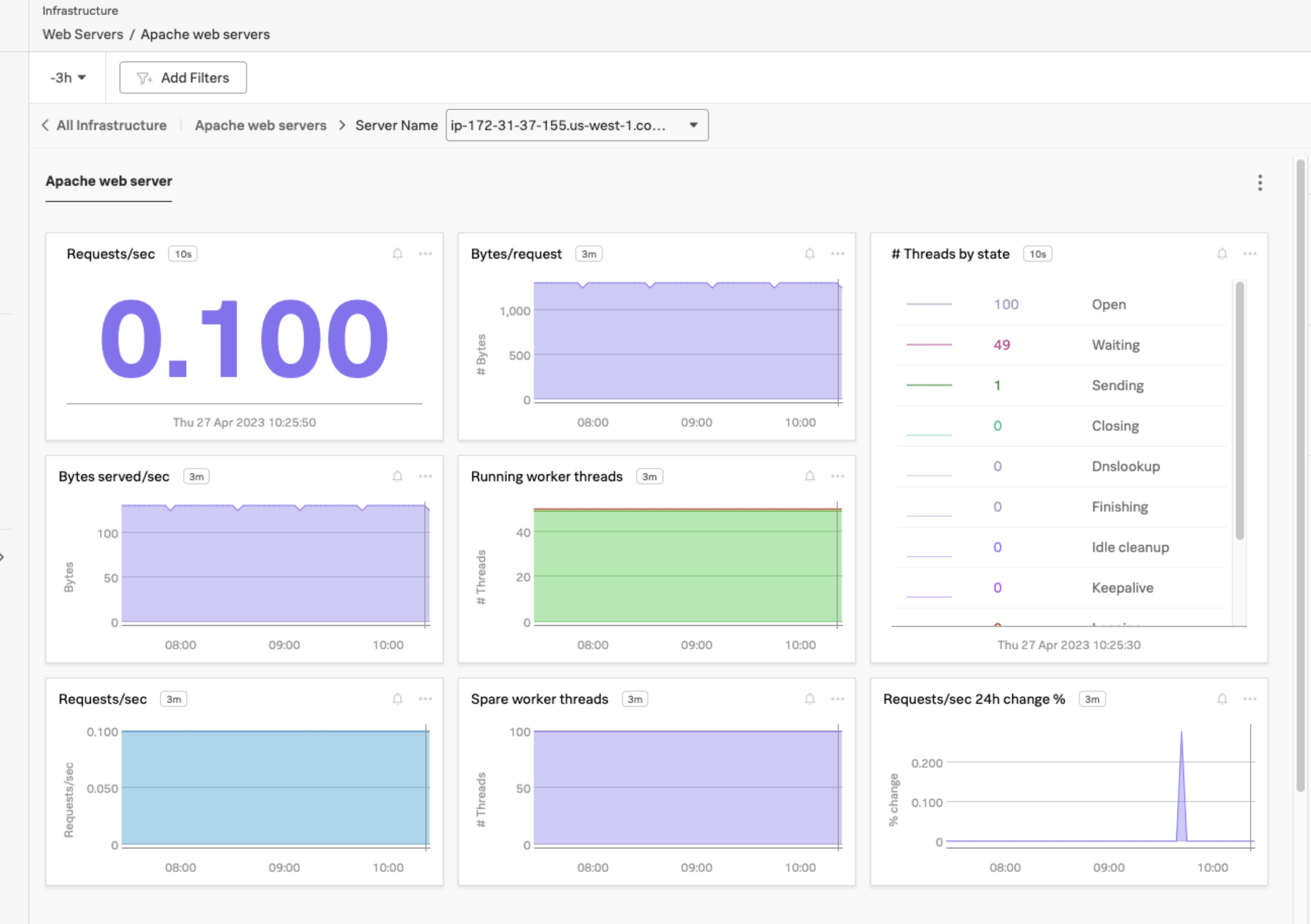
ポッドの障害を解決するために設定を更新する 🔗
Kaiはサーバー障害の根本原因を知ったので、Kubernetesの設定を更新し、ポッドを再起動した。Kai はポッドが稼働し、Apacheのダッシュボードに受信データが再び表示されていることを確認します。
概要 🔗
Kai は Splunk Observability Cloud を使って Kubernetes 環境の Web サーバーを監視し、Apache サーバーからのデータ不足を認識しました。Kai は次に Kubernetes Navigator (K8s Navigator とも呼ばれる) を開いてその問題を診断し、ナビゲーターインターフェースが提供する色分けされた可視化で欠陥のあるポッドを認識しました。彼らは個々のポッドまで掘り下げ、そこに表示されたパラメータについてSplunk アカウントチームと話し、不正なメモリ制限が障害を引き起こしていることを突き止めました。Kai が設定を更新し、ポッドを再起動すると、システムは再び設計通りに動作しました。
さらに詳しく 🔗
Splunk Observability Cloud へのデータ送信については、Splunk Observability Cloud にデータを取り込む を参照してください。
Splunk Infrastructure Monitoring のナビゲーターの概要については、Splunk Infrastructure Monitoring でナビゲーターを使用する を参照してください。