シナリオ:KaiがSplunk OTel Collectorを使用して、クラウド環境のインフラストラクチャとアプリを監視する 🔗
Kaiは、大手フィンテック企業「PonyBank」のサイト信頼性エンジニアのリーダーです。Kaiのタスクは、Amazon Elastic Kubernetes Service(EKS)上でJavaアプリケーションを実行する数百のコンテナで構成されるAWSインフラストラクチャの監視です。また、IT部門が管理する数十のLinuxおよびWindowsのElastic Compute Cloud(EC2)インスタンスもインストルメントする必要があります。主な目標は、各アセットから信頼性とパフォーマンスのメトリクスおよびログを抽出することと、Splunk APMを使ったパフォーマンス監視のためにJavaアプリケーションをインストルメントすることです。
PonyBankは、Splunk Observability Cloudを使用しています。これによって、オープンソースのSplunk Distribution of the OpenTelemetry Collector(複数ソースからのデータ収集およびデータエクスポートができるエージェント)を通じてデータを取り込みます。Splunk OTel Collectorは、ログとトレースの転送も実行でき、ソフトウェアの完全なオブザーバビリティを可能にします。
Splunk OTel Collectorを使用してインフラストラクチャをインストルメントするために、Kaiは以下の手順をとります:
クラウドへの移行以来、PonyBankのアプリケーションはEKSで稼働しています。Kaiは、ホームページからアクセスできるガイド付きのセットアップを使用して、Splunk Observability Cloudからクラウドインテグレーションをセットアップすることから開始します。ガイド付きセットアップを使用すると、適切な取り込みトークンを選択して、選択したオプションからインストールコマンドと設定スニペットを生成することができます。Kaiはこれらを使用して迅速にインストルメンテーションをデプロイします。
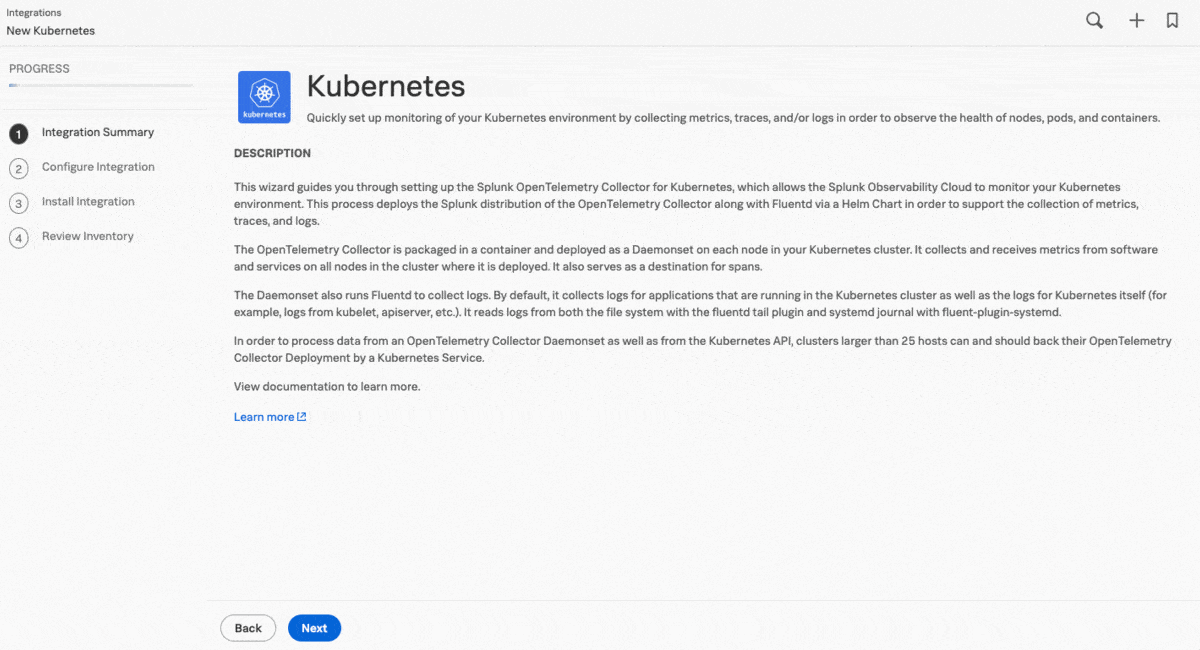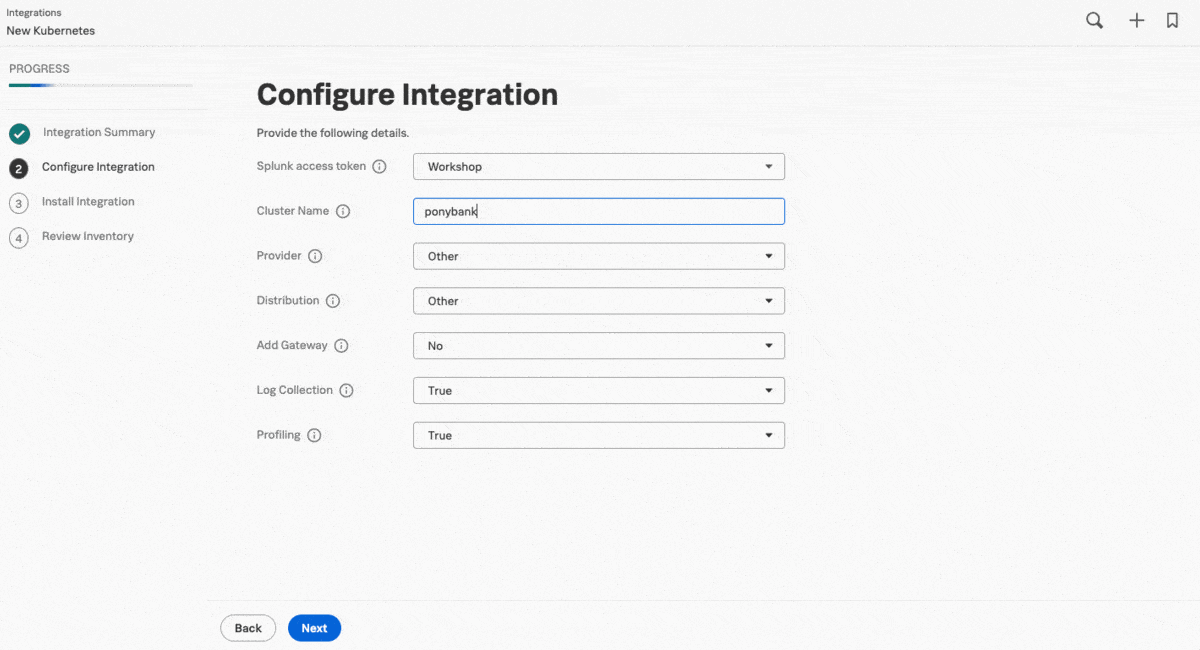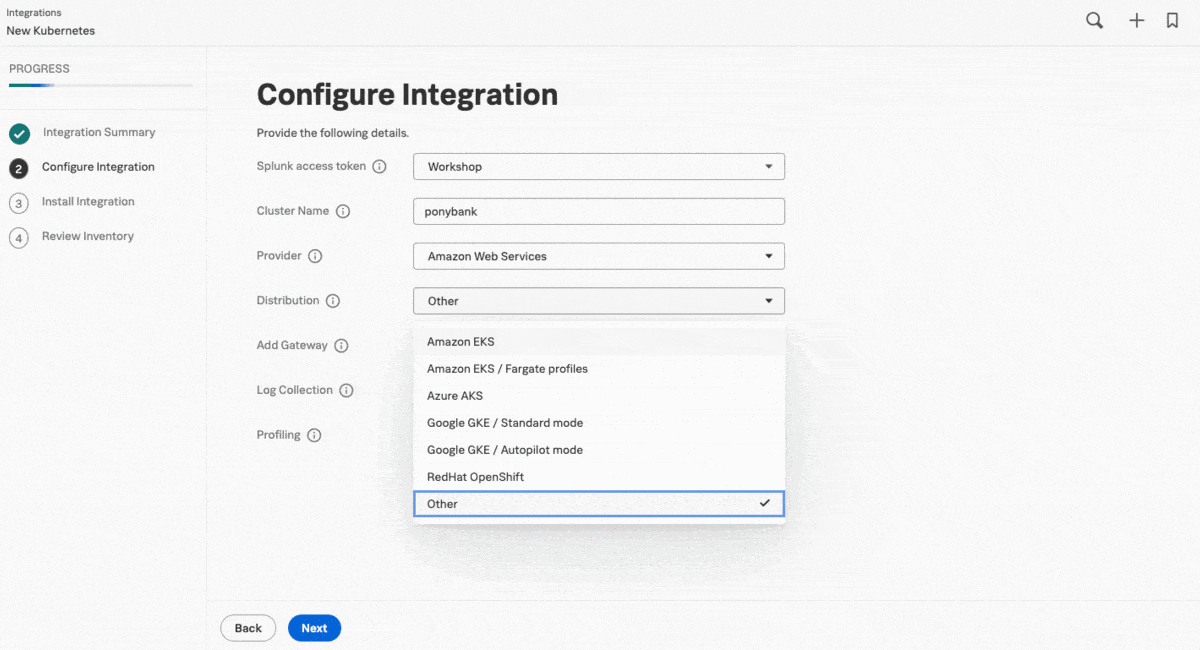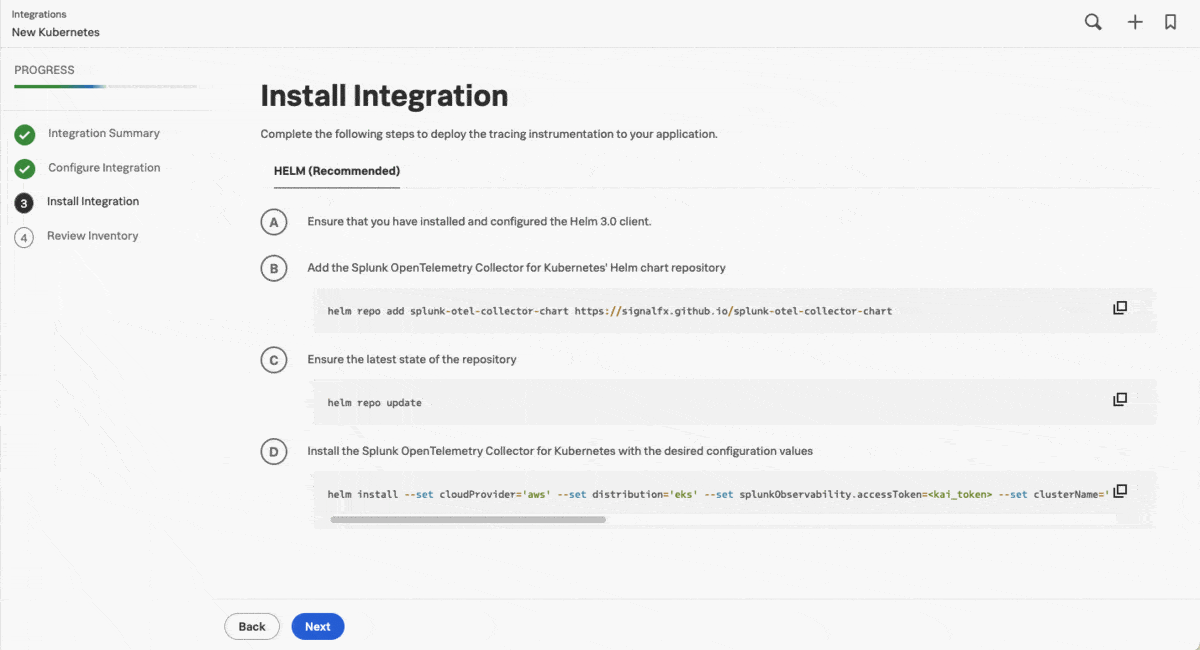
クラウドに直接アクセスできない数百のコンテナを含むクラスターが仮想プライベートクラウド(VPC)内にあるため、Kaiはガイド付きセットアップを使用して、データ転送(ゲートウェイ)モードでSplunk OTel Collectorインスタンスのクラスターを追加し、元の構成の安全性を維持しながらデータの受信と転送ができるようにしました。次のステップでは、ガイド付きセットアップによってHelm用にカスタマイズされたコマンドが提供されます。
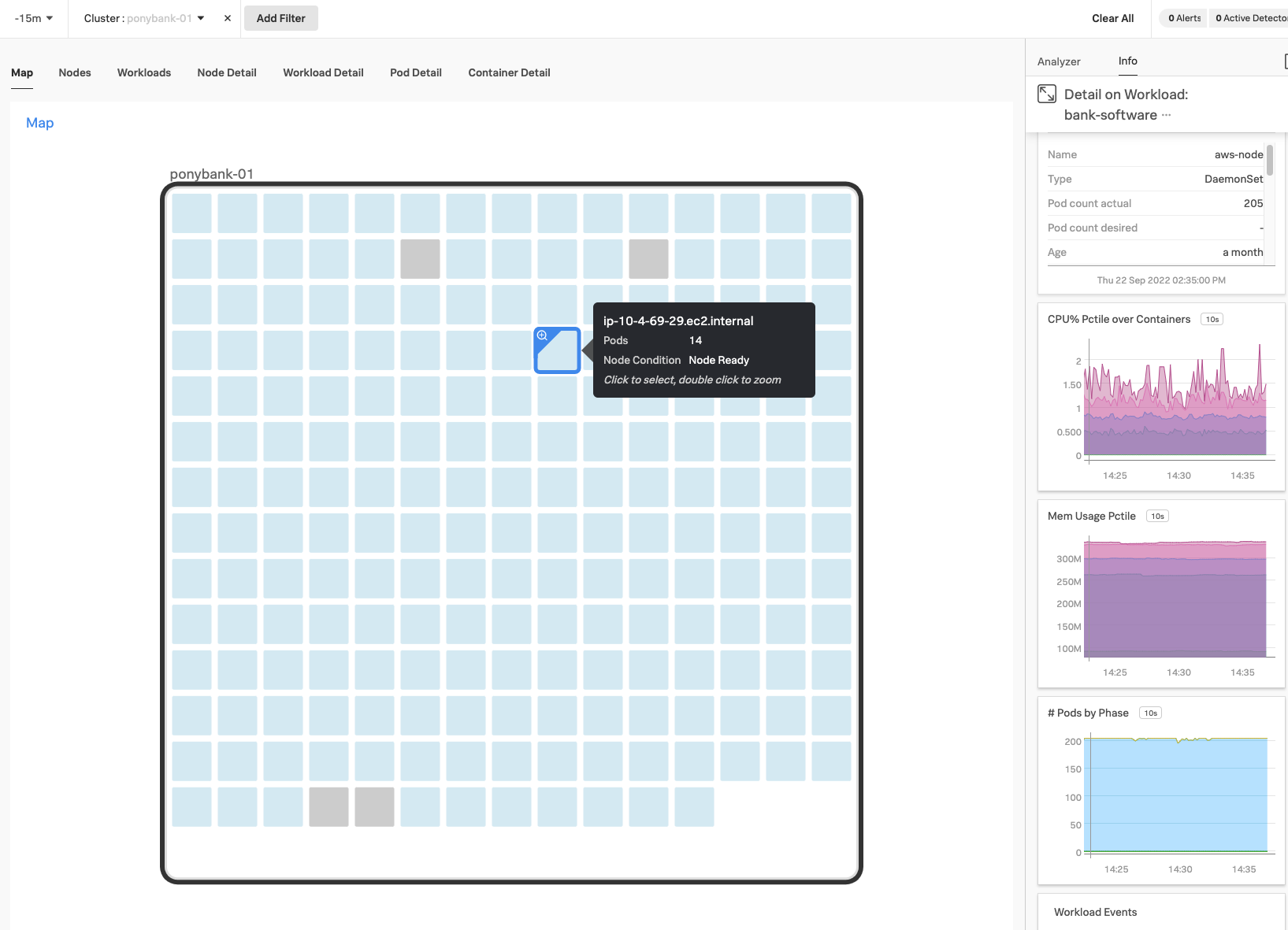
ガイド付きセットアップの最後で、KaiはInfrastructure MonitoringのKubernetesマップに入り、クラスターのステータスを確認します。Kubernetesマップ上のノードを選択します。これは、グリッド内に色付きのキューブとして表示されており、ワークロードやシステムメトリクスといった各要素のステータスの詳細を知ることができます。
IT部門がElastic Compute Cloud(EC2)インスタンスとして管理するホストについて、Kaiは、PonyBankの既存のPuppet設定を使用してSplunk OTel Collectorをデプロイすることにしました。Splunk Observability CloudでLinux監視用のガイド付きセットアップを開き、Puppetタブを選択します。必要な情報を入力した後は、2つのステップに従うだけです:
Puppet ForgeからSplunk OTel Collectorモジュールをインストールする
以下のように、マニフェストファイルに新しいクラスを含める:
class { splunk_otel_collector: splunk_access_token => '<kai_token>', splunk_realm => 'us0', collector_config_source => 'file:///etc/otel/collector/agent_config.yaml', collector_config_dest => '/etc/otel/collector/agent_config.yaml', }
またKaiは、Puppetで管理されていない、組織内に散在するいくつかのEC2インスタンスに対しても、Linuxガイド付きセットアップを使用し、インストーラスクリプトタブの手順に従います。カスタマイズされたインストーラスクリプトコマンドによって、必要な構成でコレクターのダウンロードと実行が行われます。
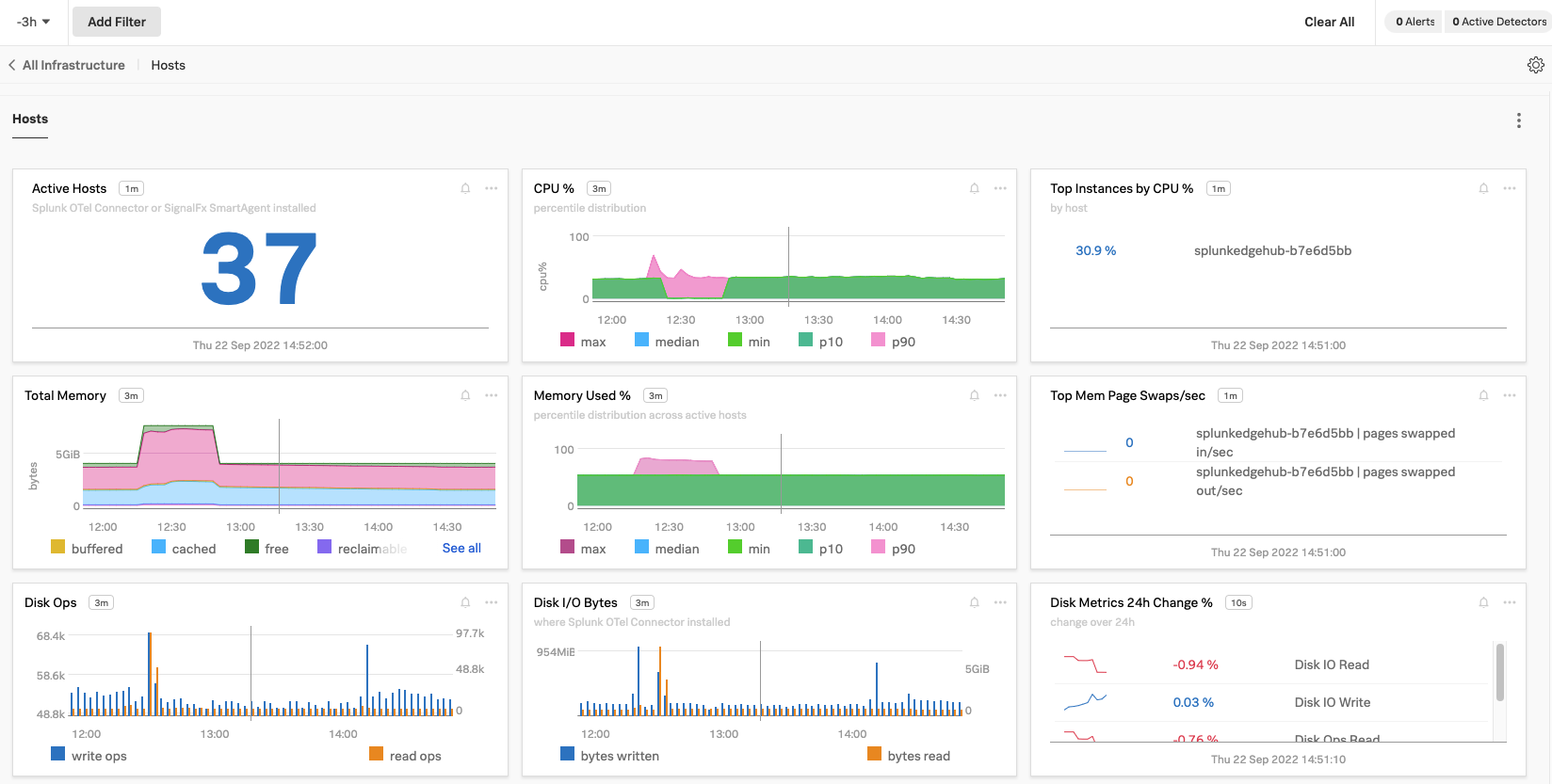
これで、Kaiは、各ホストからのデータがInfrastructure Monitoringに流れていることを確認できます。各ホストについて、データポイントの中でも特にメタデータ、システムメトリクス、プロセスを見ることができます。
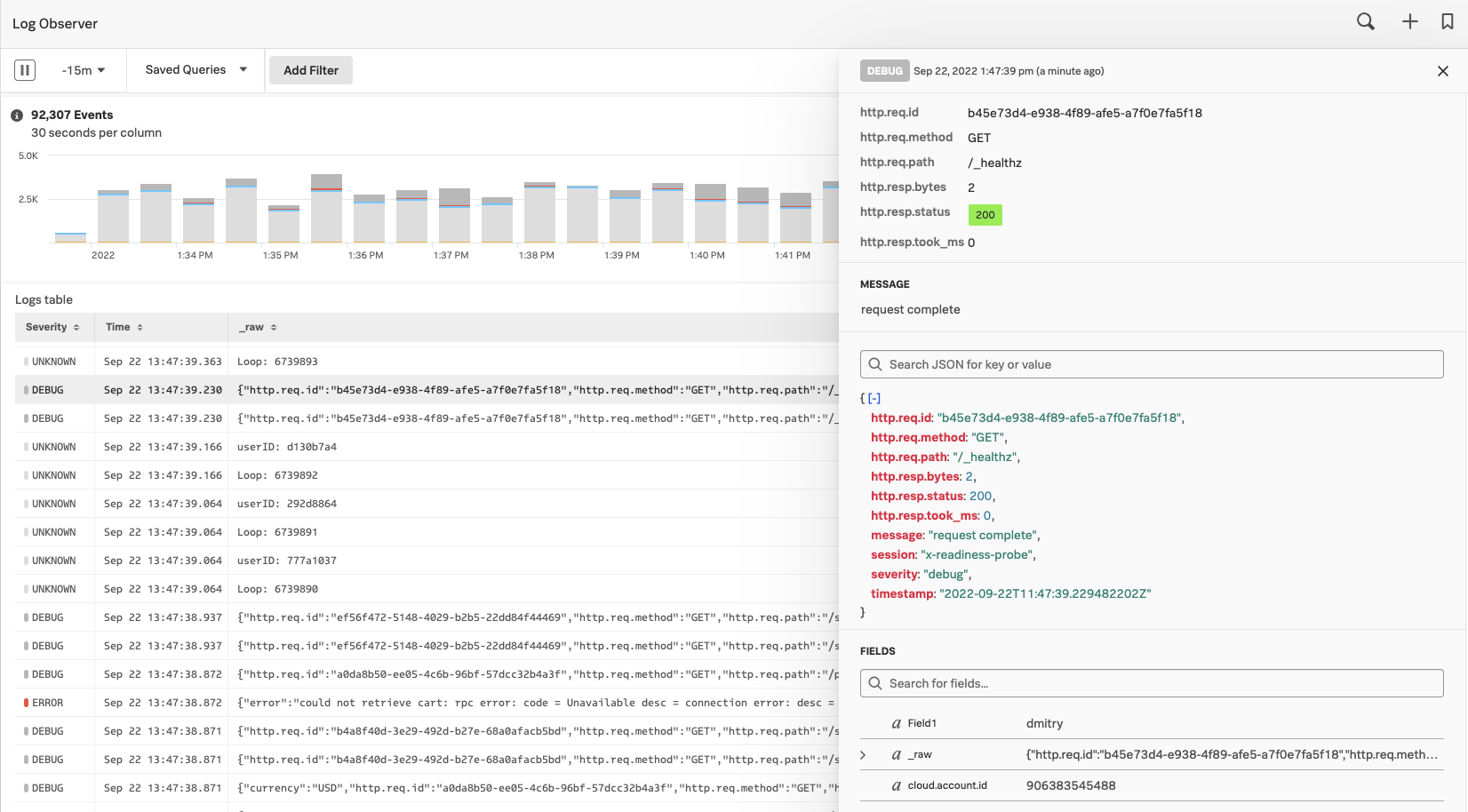
同時に、KaiはSplunk Log Observerで各ホストとノードからのログを確認することもできます:
Kaiの最終目標は、PonyBank社のJavaサービスをSplunk APM用にインストルメントして、チームがSplunk Observability Cloudでスパンとトレースを分析し、AlwaysOn Profilingを使ってCPUやメモリを使いすぎている非効率なコードを迅速に特定できるようにすることです。
これを行うために、Javaのガイド付きセットアップを選択します。これには、Collectorのデプロイ後にSplunkのJavaエージェントを有効にするために必要なすべての手順が含まれています。Kaiは、APMとInfrastructure Monitoring間での「関連コンテンツ」機能を有効にするために不可欠な環境とサービス名を定義します。
必要な機能とオプションをすべて選択した後に、現在のKubernetes構成に追加できるYAMLスニペット、ならびにカスタマイズされたランタイムコマンドを取得します。
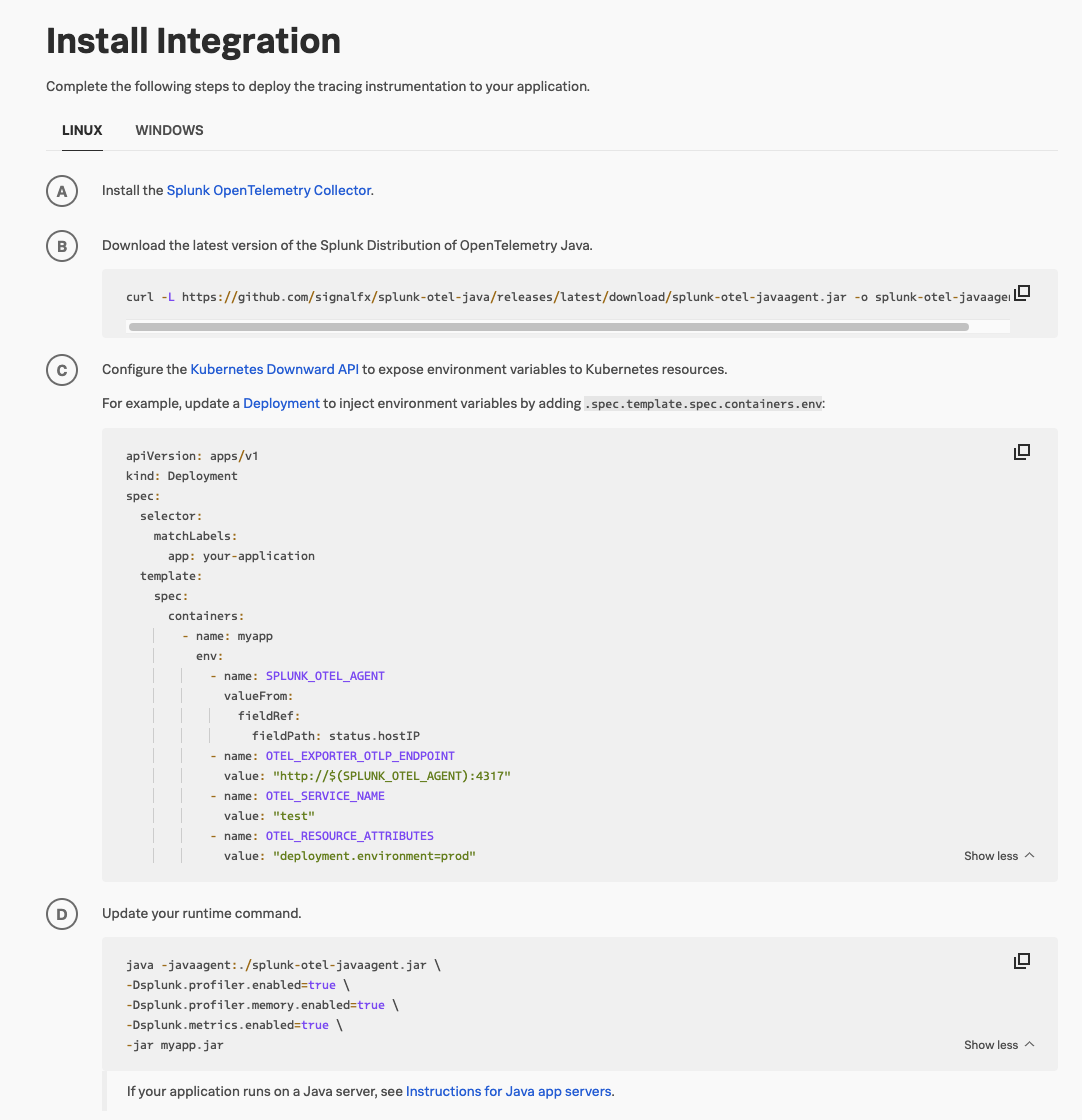
同様にJavaサービスを含むEC2インスタンスについても、Kaiは同じガイド付きセットアップを使用して、カスタマイズされたコマンドをコンソールで実行します。アプリケーションのインストルメンテーションには数秒かかります。

「関連コンテンツ」機能のおかげで、アプリケーションの精算サービスを実行しているノードを選択すると、関連コンテンツバーに、Splunk APMへのリンクとしてサービスが表示されます。
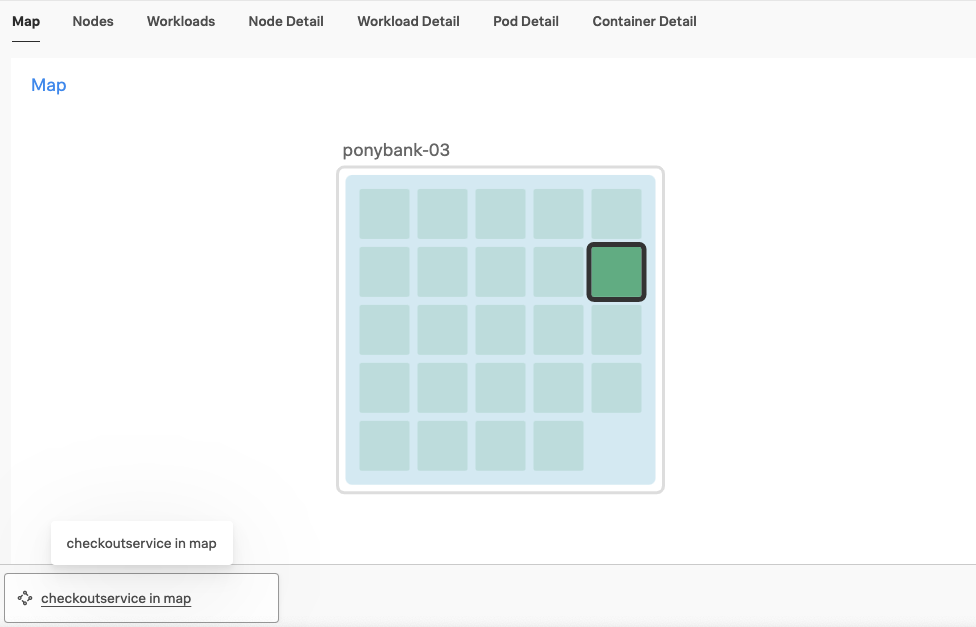
下の画像に示すように、KaiがSplunk APMを開いてサービスマップ内で精算サービスを選択すると同じことが起きます。checkoutserviceのEKSクラスターが、マップに続く「関連コンテンツ」バーに表示されます。Splunk Observability CloudがOpenTelemetryの属性とデータを使って実行するAPMとInfrastructureのマッピングのおかげで、Splunk Observability Cloudは、両方のリンクを提案できます。
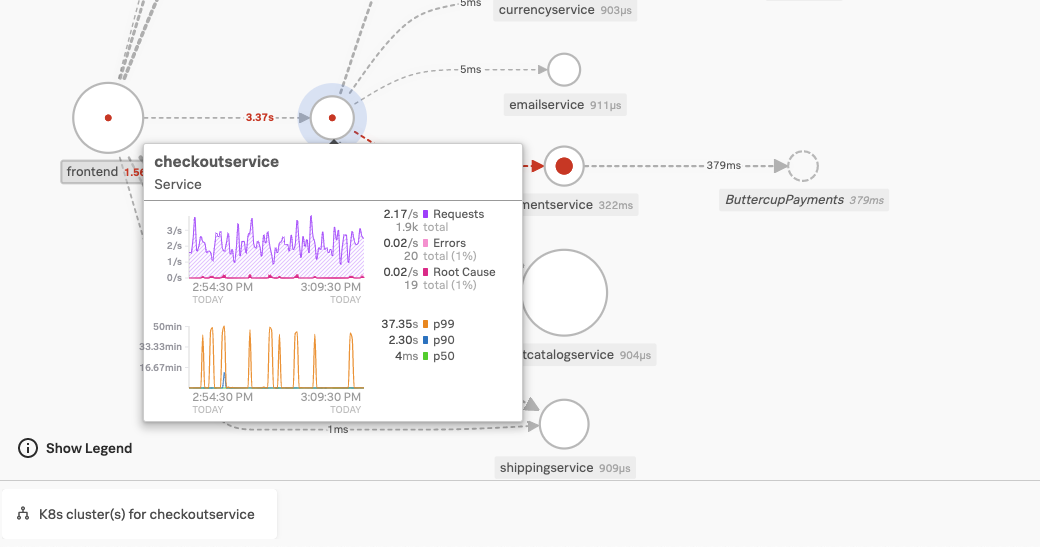
Kaiは、Splunk OTel Collectorを使用してPonyBank のクラウドインフラストラクチャ全体をインストルメントし、各環境と状況に合わせた設定ファイルとコマンドを迅速に取得しました。また、APM用のJavaインストルメンテーションを通じて、EKSクラスター上で実行されているJavaサービスからのトレースと、利用可能な関連コンテンツへのアクセスを取得しました。
Splunk Observability Cloudへのデータ送信方法については、Splunk Observability Cloud にデータを取り込む を参照してください。
複数のプラットフォームからインフラストラクチャメトリクスとログを収集する方法は、Splunk Distribution of the OpenTelemetry Collector の利用開始 を参照してください。
Splunk APM用にJavaサービスをインストルメントする方法は、Splunk Observability Cloud 用 Java アプリケーションのインストルメンテーション を参照してください。
Splunk Observability Cloudの「関連コンテンツ」機能の詳細については、InfraおよびAPMの関連コンテンツを有効にするために Collector を設定する を参照してください。