シナリオ:KaiがSplunk Observability Cloudを使用してブラウザからバックエンドまでの問題をトラブルシューティングする 🔗
架空の企業、Buttercup Gamesは、自社製品を販売するためのECサイトを運営しています。彼らは最近、マイクロサービスアーキテクチャとKubernetesをインフラに採用したクラウドネイティブなアプローチを使用するように、サイトを再設計しました。
Buttercup Gamesのサイト信頼性エンジニア(SRE)とサービスオーナーは、人々がサイトを訪問した際に素晴らしいエクスペリエンスを提供できるよう、協力してサイトの監視とメンテナンスを行っています。彼らがクラウドネイティブのアプローチを取ることを決めた多くの理由のうちの1つは、オブザーバビリティを促進できるからです。彼らは、オブザーバビリティのソリューションとして、Splunk Observability Cloudを選択しました。
このシナリオでは、SREのKaiとサービスオーナーのDeepuがSplunk Observability Cloudを使用して以下のタスクを実行し、Buttercup Gamesのサイトで最近発生したインシデントのトラブルシューティングと根本原因の特定を行った方法について説明します:
このシナリオの動画版は、Splunk Observability Cloudのデモ をご覧ください。
オンコール対応のSREであるKaiは、Buttercup Gamesサイトでの購入数が過去1時間において大幅に減少し、精算の完了率が極めて低いことを示すアラートを受け取りました。Kaiは、自分のチームがSplunk Observability Cloudで設定したアラートルールが、静的閾値を使用するのではなく動的なベースラインとして時間と曜日を考慮に入れていることから、これらのアラートが本当に異常な挙動を示すものであることを信用しています。
KaiはラップトップでSplunk Observability Cloudにログインして調査します。
Kaiが受信したアラートについてまず知りたいのは:ユーザーへの影響
KaiはSplunk Real User Monitoring(RUM)を開いて、サイト上のブラウザベースのパフォーマンスを基に、問題の手がかりを探します。購入数の減少と精算の完了率の低さに関連している可能性のある、以下の2つの問題に気が付きました:
フロントエンドのエラーの急増
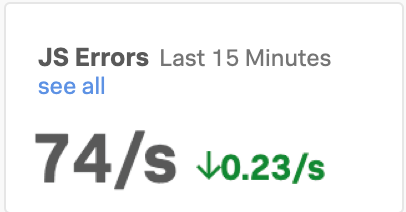
バックエンドのエンドポイントの高レイテンシ
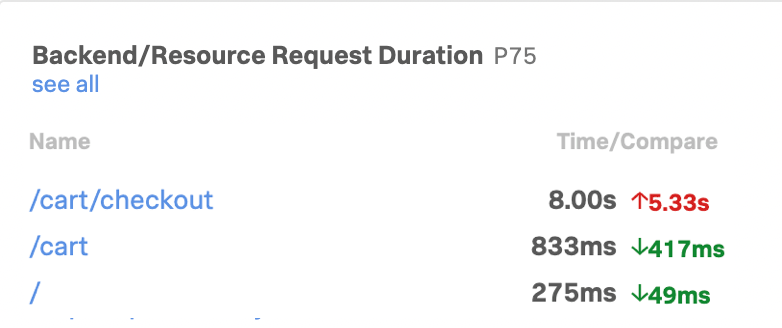
Kaiは、この2つの問題には関連があるのか、また、これらがサイトの問題の原因であるかどうかについて、確信が持てません。「 /cart/checkout 」のエンドポイントのレイテンシが高いことについて調査することにしました。「 cart/checkout 」のページ読み込み時間と最大コンテンツの描画も高くなっているためです。
Kaiは「 /cart/checkout 」エンドポイントのリンクを選択し、Splunk RUMのTag Spotlightビューで複数のエラーを確認します。エラーは特定のどのタグにも関連していないようなので、「 ユーザーセッション 」タブを選択してユーザーセッションを調べます。
Kaiは、他のセッションよりも時間がかかっているように見えるセッションを1つ見つけました。フロントエンドからバックエンドまでの完全なトレースを見るためにそのセッションを選択すると、このセッションに通常よりも長い時間がかかっていることが分かりました。このデータ例に基づいて、Kaiは、このレイテンシはフロントエンドの問題ではなく、バックエンドまでトレースをたどる必要があることを理解しました。
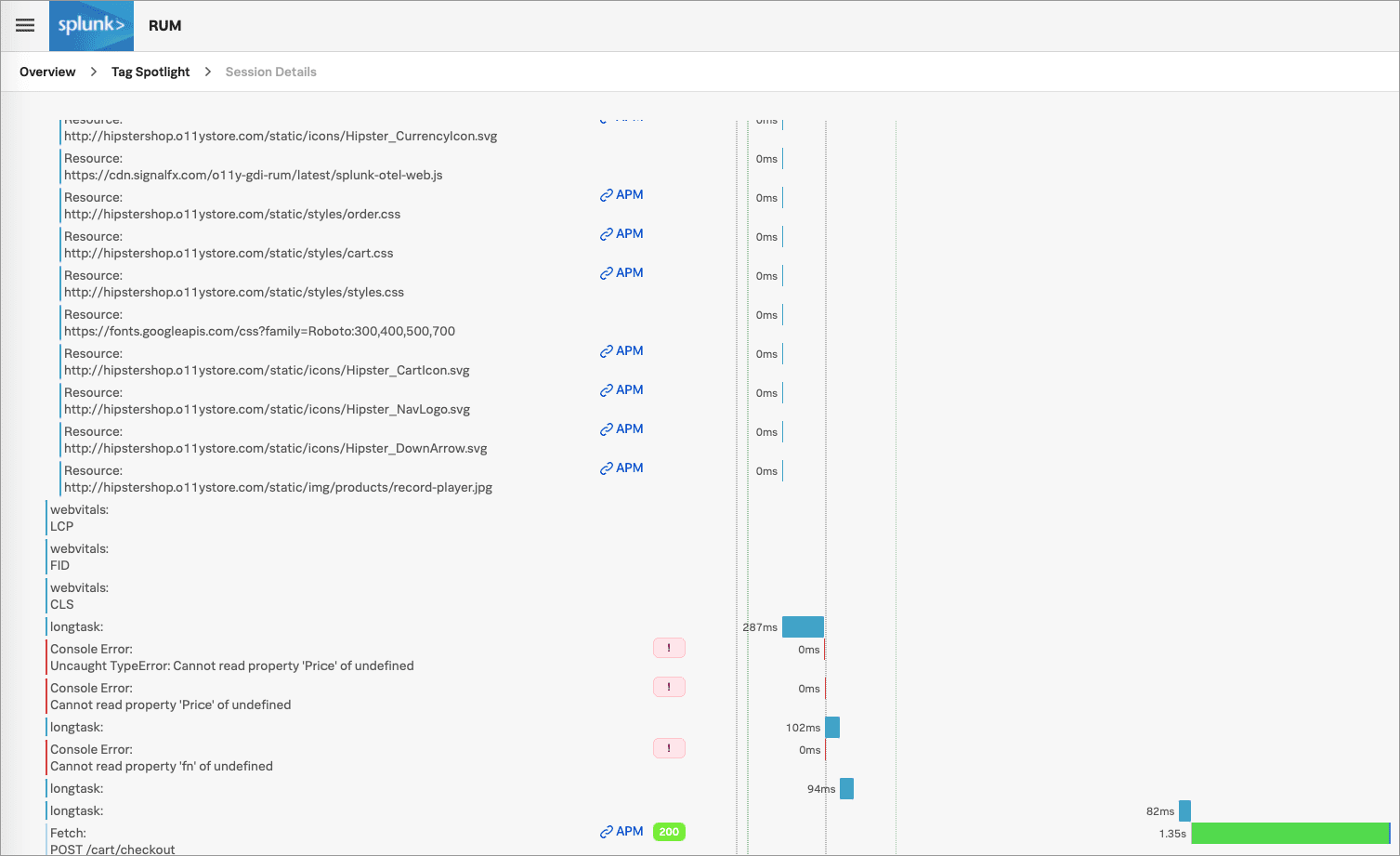
Kaiは APM のリンクを選択して、パフォーマンスサマリーとこのセッションのトレースおよびワークフローの詳細にアクセスします。
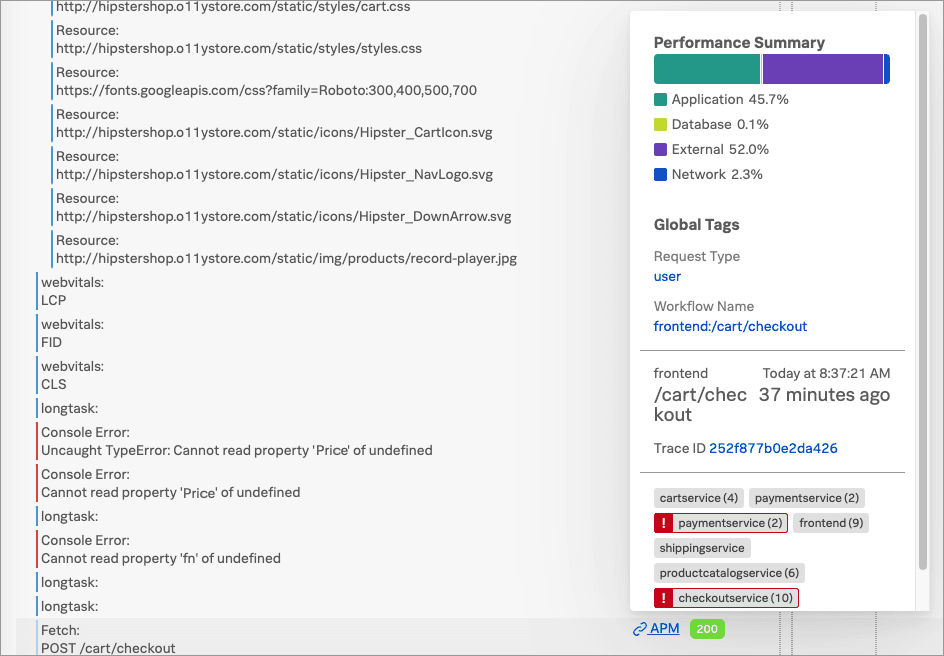
Kaiは、エンドツーエンドのトランザクションのワークフローを見てみることにしました。
Splunk RUMで、Kaiは frontend:/cart/checkout のビジネスワークフローのリンクを選択し、Splunk Application Performance Monitoring(APM)でそのサービスマップを表示します。ビジネスワークフローとは、システム内のエンドツーエンドのトランザクションを反映するトレースのグループのような、論理的に関連付けられたトレースのグループです。
このサービスマップを見て、Kaiは、あるサービスから別のサービスへのエラーの伝搬を含め、トラブルシューティング対象の「 /cart/checkout 」のアクションを支えるサービスの全一式における依存関係の相互作用を理解します。
特に、paymentservice に問題があることが分かります。Splunk APMはこの問題を根本原因エラーとして特定しました。つまり、paymentservice では、ワークフローのエクスペリエンス低下の原因となっているダウンストリームエラーの数が最も多いということです。
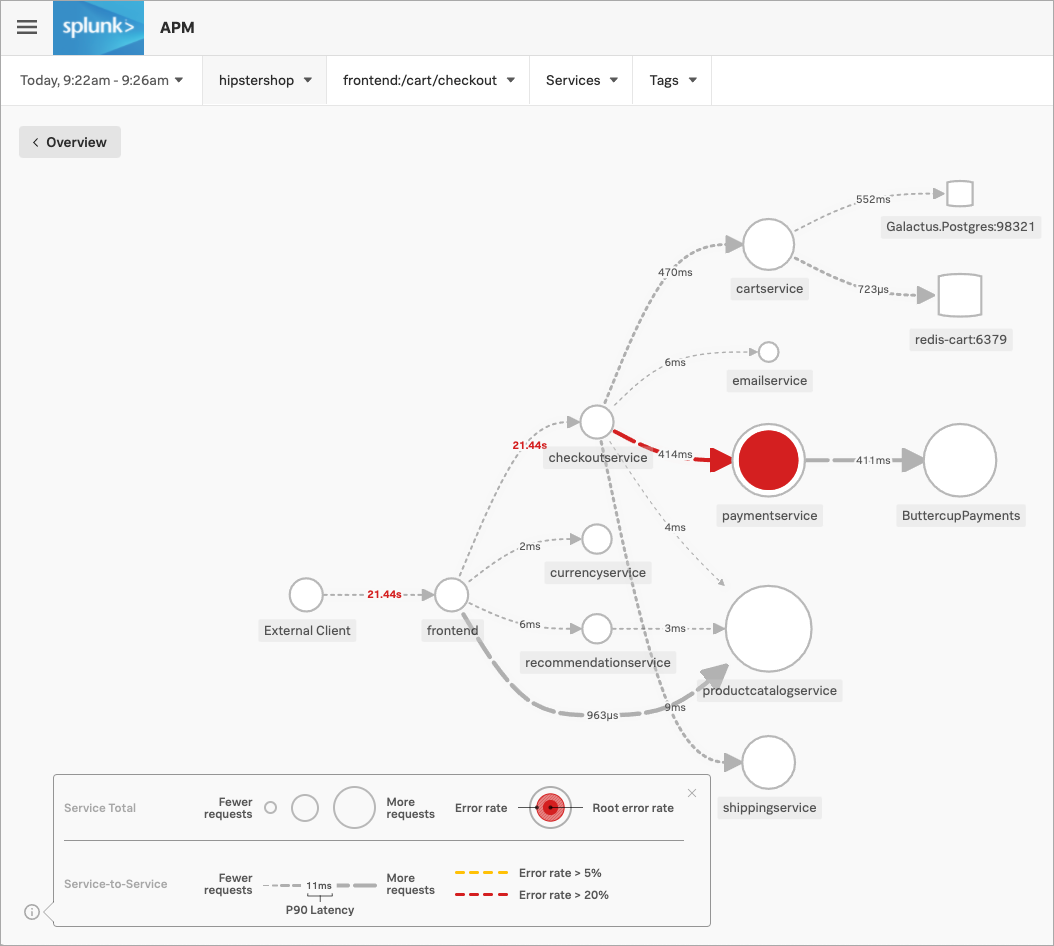
Kaiは、paymentservice を選択します。サービスのエラーとレイテンシの詳細が表示されるだけでなく、Splunk Observability Cloudによって、アプリケーションの他領域にある関連データへのアクセスを提供する「関連コンテンツ」のタイルも表示されます。
例えば、Kaiは、paymentservice を実行するKubernetesクラスターの健全性を調べたり、paymentservice によって発行されるログを調べたりすることができます。
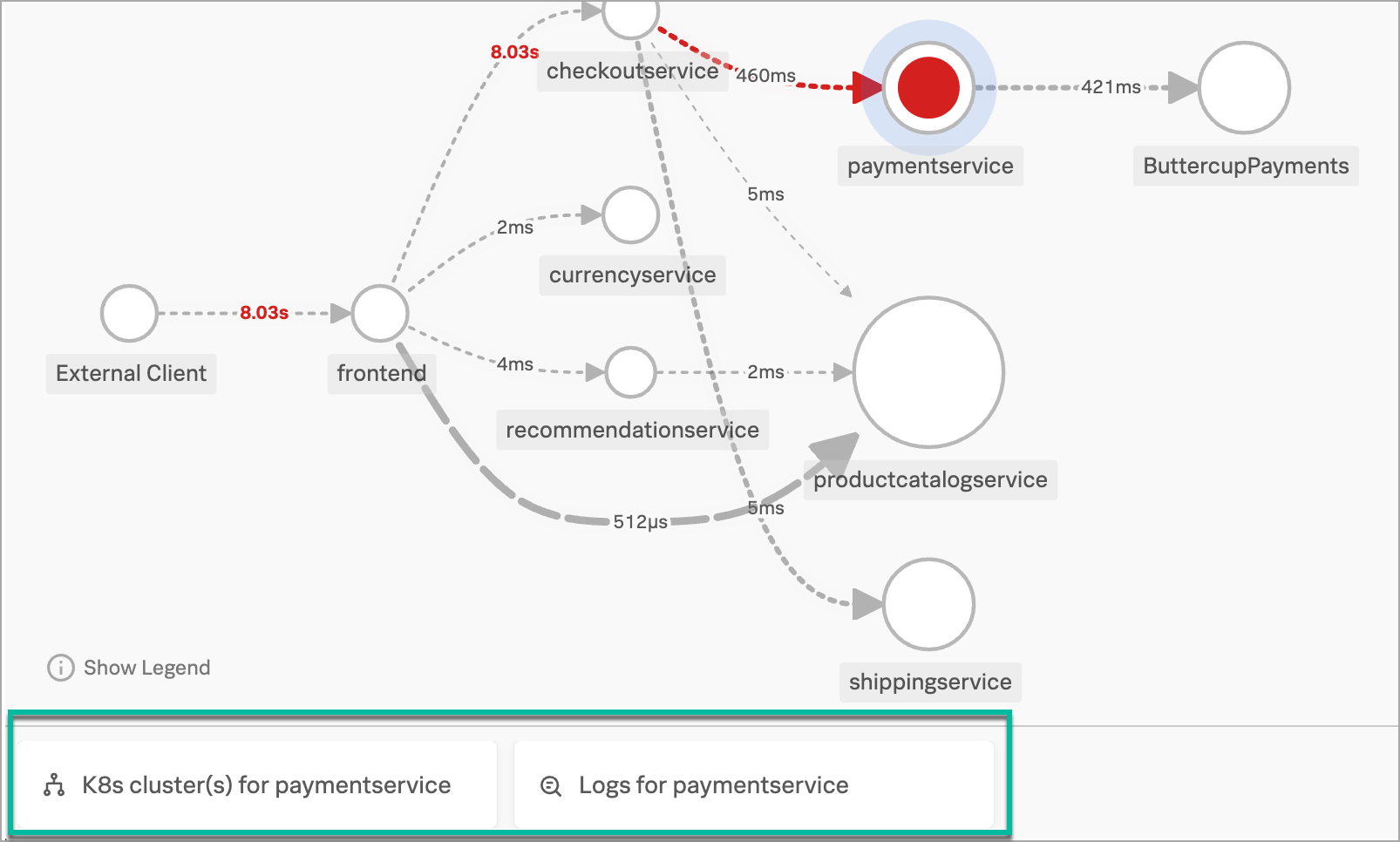
KaiはKubernetesクラスターを調べて、このエラーがインフラストラクチャの問題に基づいているものかどうかを確認することにしました。
Kaiは、Splunk APMで「 paymentserviceのK8sクラスター 」の「関連コンテンツ」タイルを選択し、Splunk Infrastructure MonitoringのKubernetesのナビゲーターを表示します。ここでは、Splunk APMで表示していたコンテキストを保持するため、自動的にビューが「 paymentservice 」に絞り込まれています。
クラスターマップの「 paymentservice 」ポッドを選択して、データを深く掘り下げます。
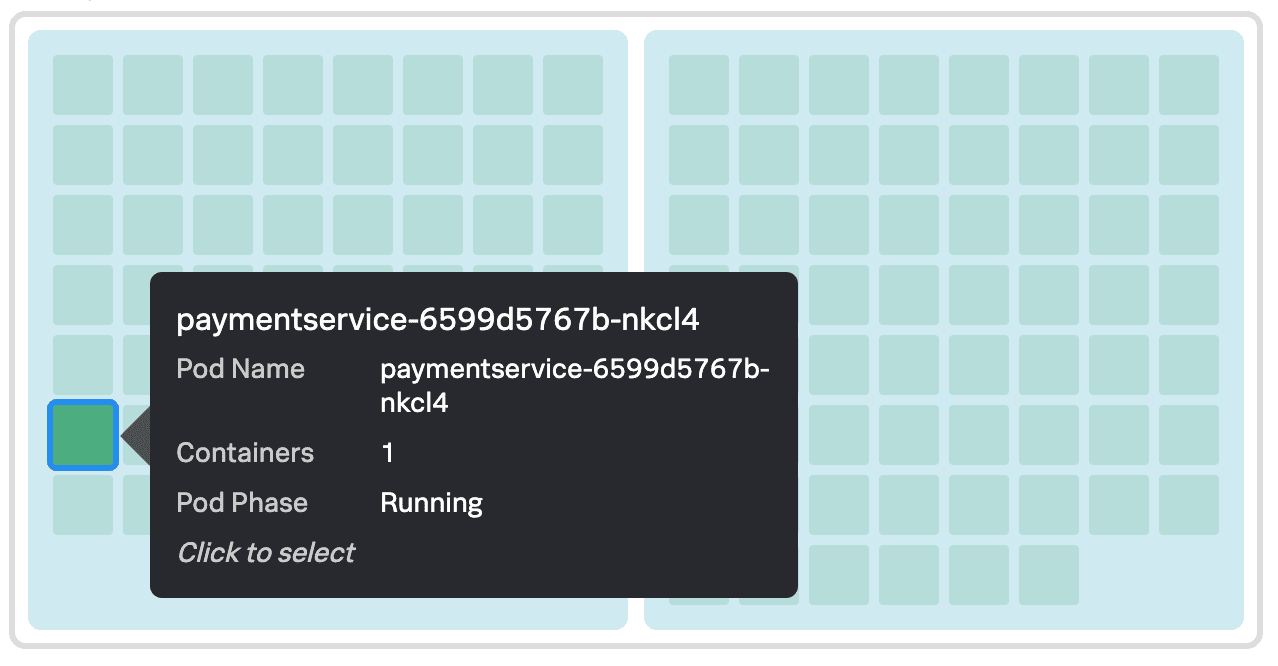
Kaiは、このポッドがエラーもイベントもなく安定していることを確認します。
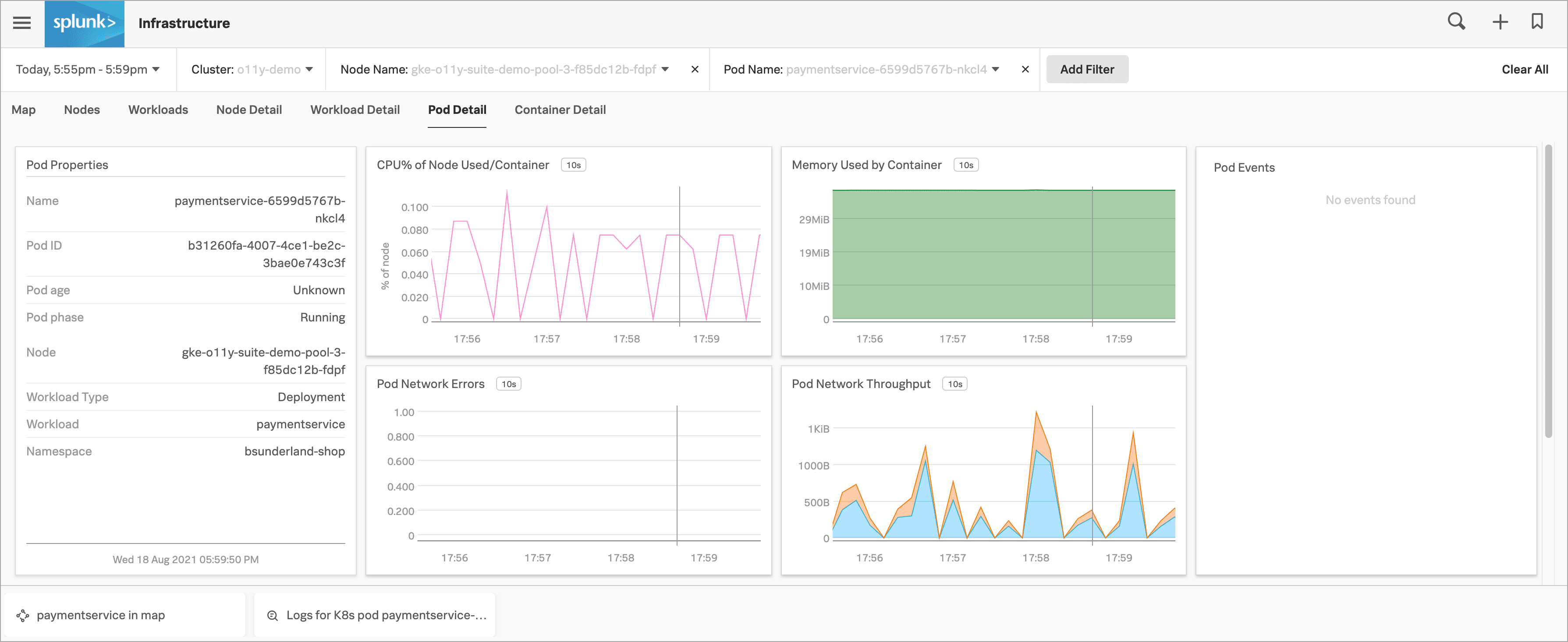
問題の原因としてKubernetesインフラストラクチャを除外できたので、Splunk APMでの調査に戻ることにしました。Splunk Infrastructure Monitoringの現在のビューで、マップ内のpaymentservice の「関連コンテンツ」タイルを選択します。
Splunk APMで、Kaiは Tag Spotlight` を選択し、調査中のエラーのタグ値の相関関係を調べます。
例えば、Kaiが tenant.level モジュールを見ると、すべてのレベルでエラーが発生していることが分かります。このため、根本原因はテナント固有のものではない可能性が高いです。
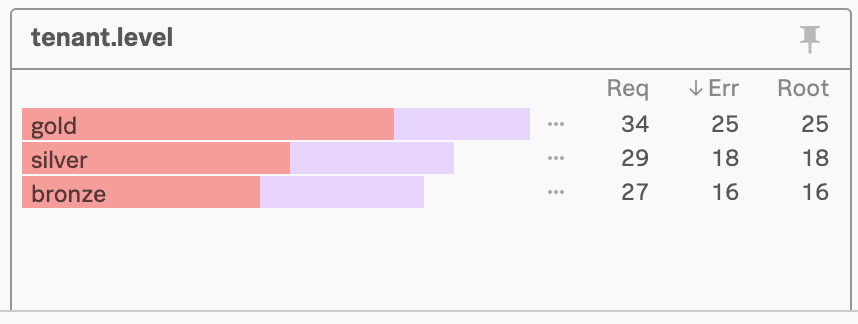
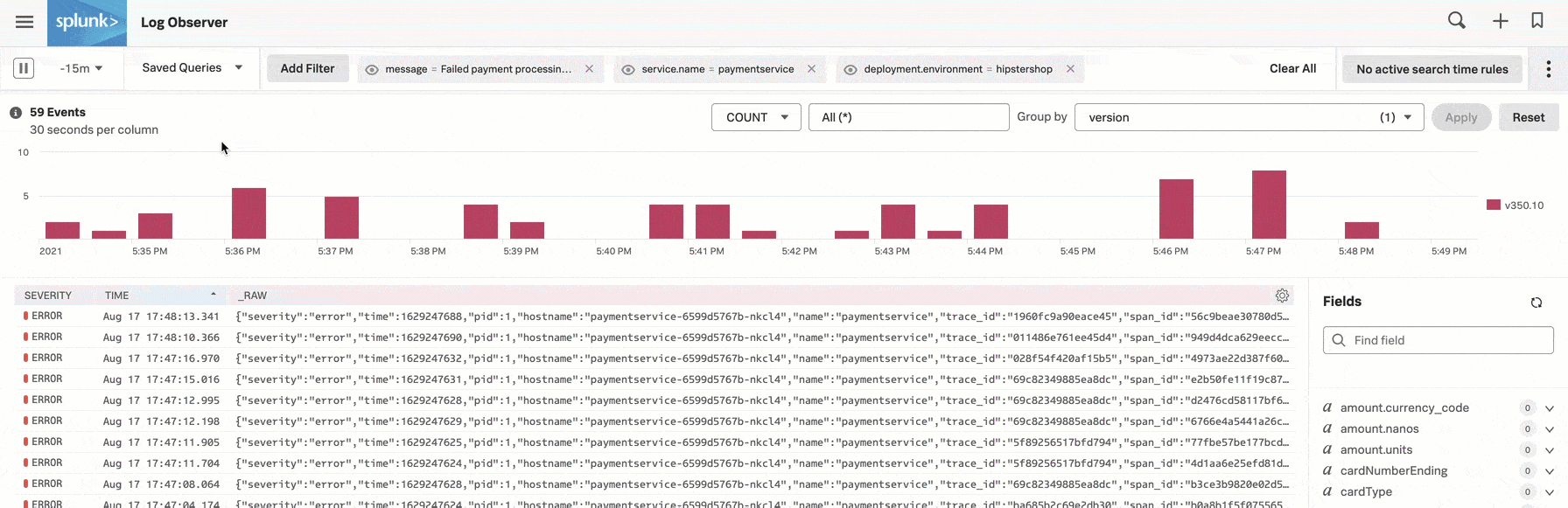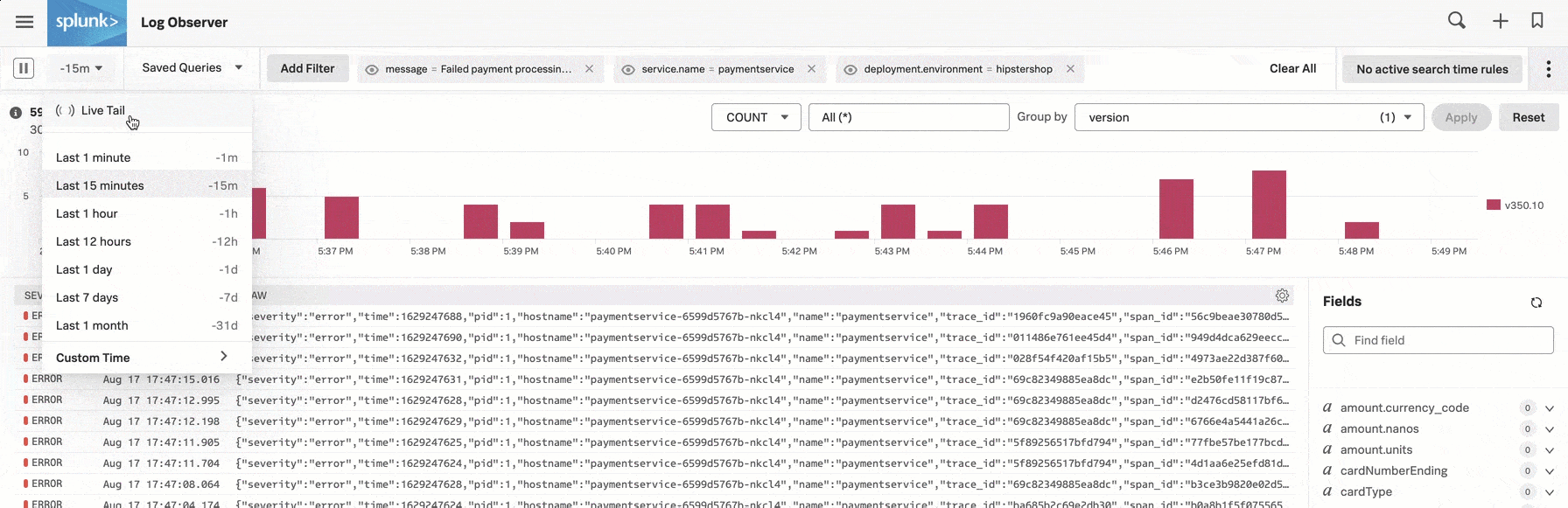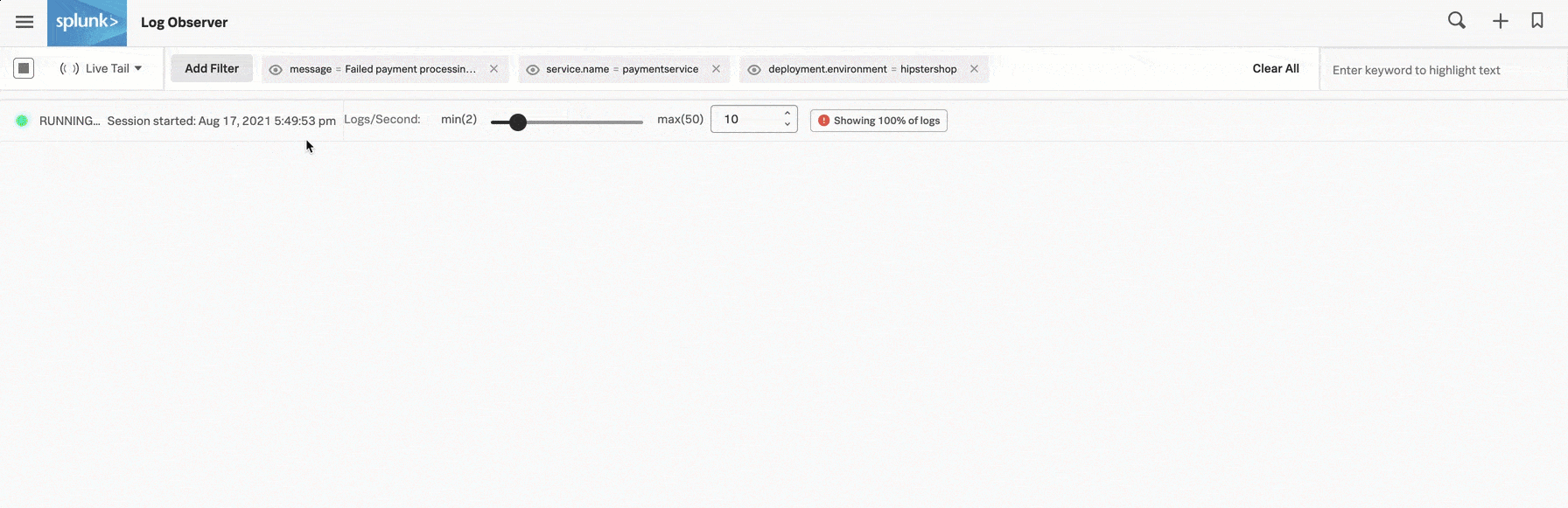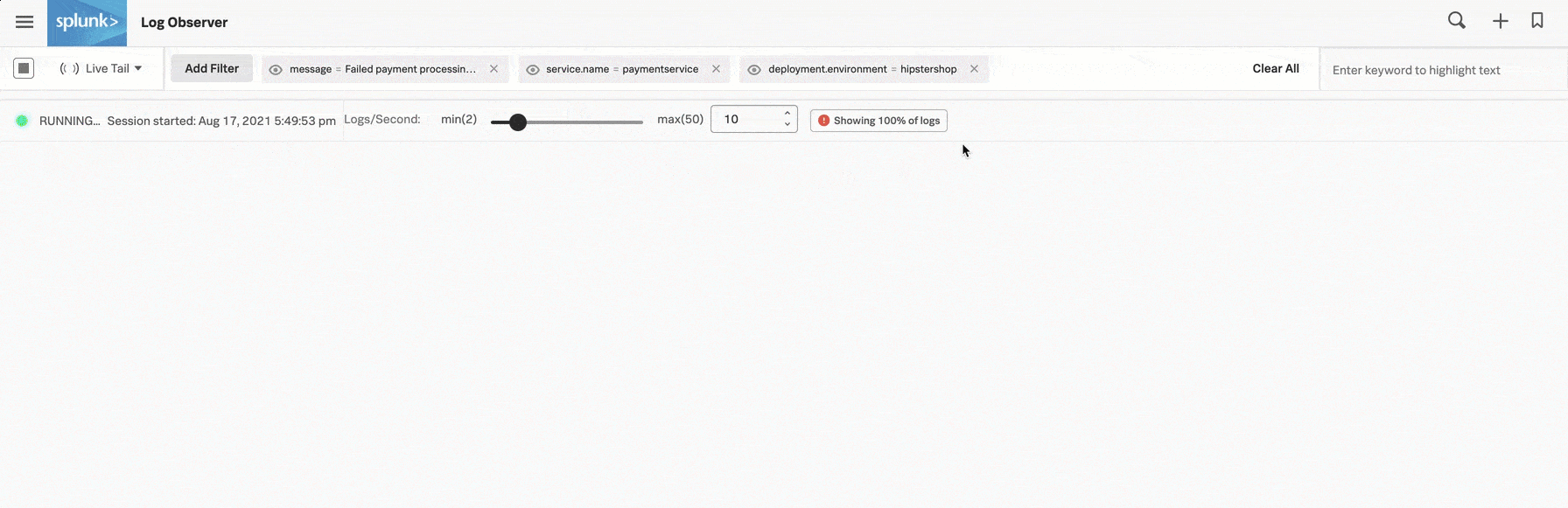
しかし、Kaiが バージョンモジュール を見ると、興味深いパターンが確認できました。エラーはバージョン v350.10 でのみ発生しており、下位の v350.9 バージョンでは発生していません。
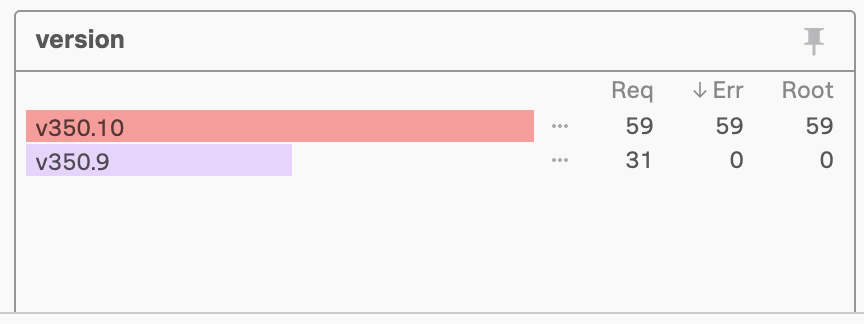
これは有力な手がかりのようなので、Kaiはログの詳細を調べることにしました。paymentserviceのログ の「関連コンテンツ」タイルを選択します。
さて、Splunk Log Observer ConnectではKaiのビューが自動的に絞り込まれ、「 paymentservice 」について受信したログデータのみが表示されています。
いくつかのエラーログを見て、1つのログを選択し、構造化されたビューで詳細を確認します。ログの詳細を見ると、次のエラーメッセージが表示されています:「ButtercupPaymentsで決済処理が失敗:無効なAPIトークン(test-20e26e90-356b-432e-a2c6-956fc03f5609)」。
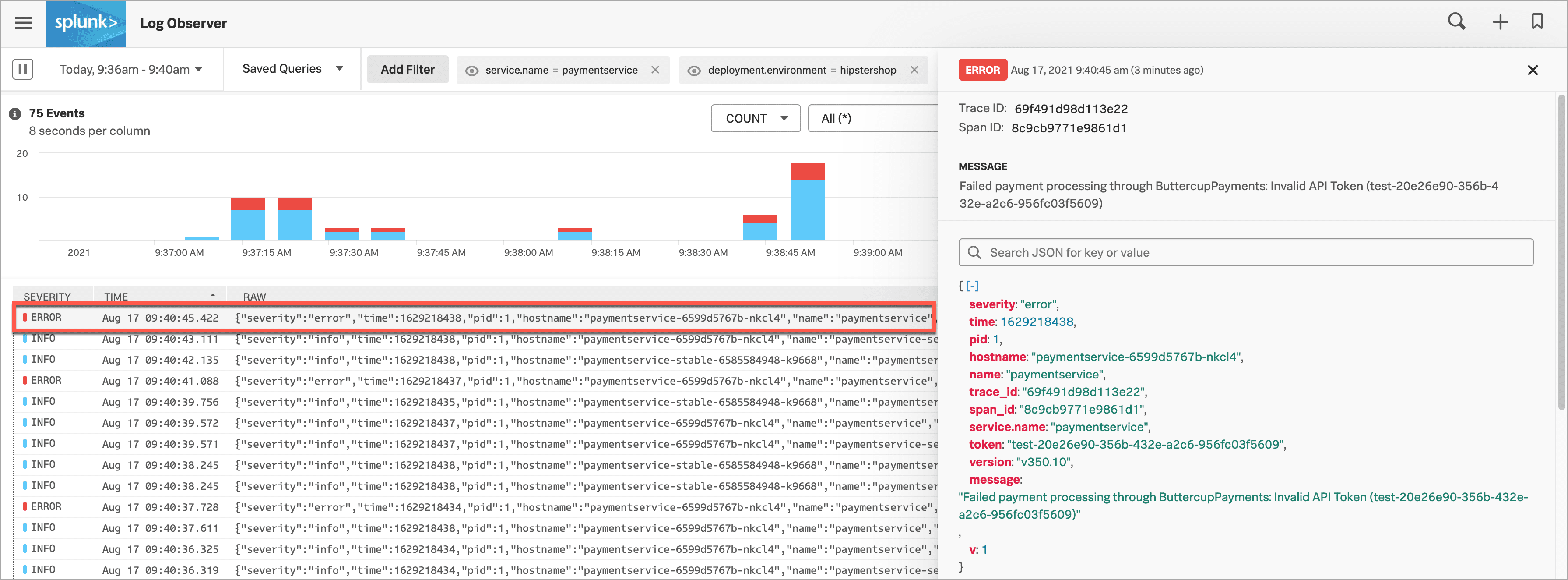
エラーメッセージの中に、Kaiはエラーの明確な兆候と思われるものを見つけました。APIトークンが「test」で始まっています。あるチームが、本番環境では動作しないテストトークンを使ってv350.10をライブ環境にプッシュしたと考えられます。
この仮説をチェックするために、Kaiはこのエラーメッセージを選択し、このエラーメッセージを含むログのみを表示するため、フィルターに追加 を選択します。
次に、「 グループ化の方法 」を「 重大度 」から「 バージョン 」に変更します。
これでKaiは、このテストAPIトークンのエラーを含むログのすべてがバージョン v350.10 のものであり、バージョンv350.9のものは1つもないことを確認しました。
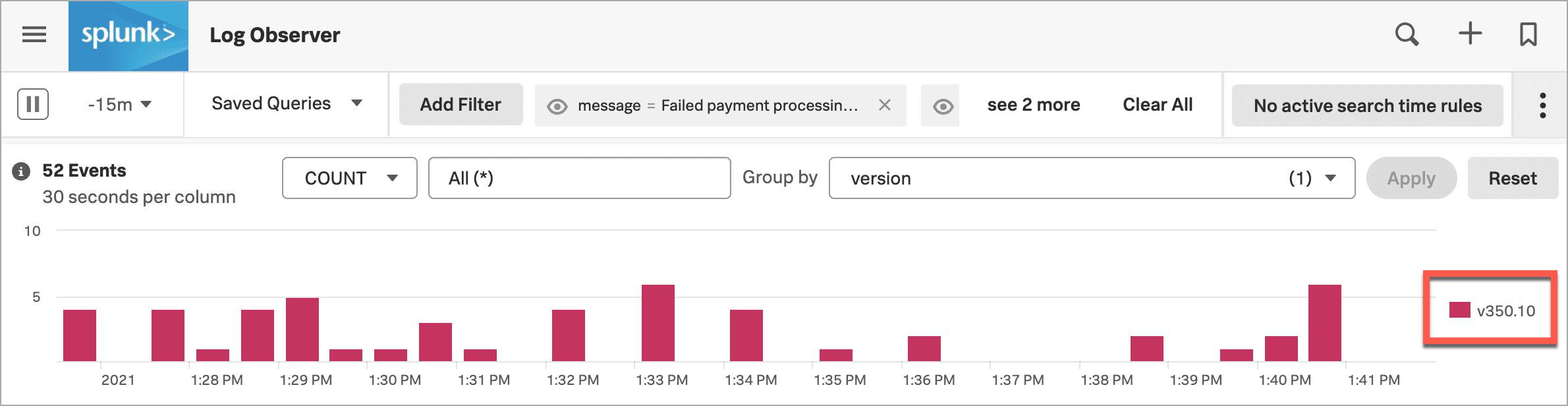
確認のため、Kaiは、このフィルターを一時的に除外するために、このメッセージフィルター値の目型のアイコンを選択します。これでバージョンv350.9のログも表示されましたが、それらのログにはエラーメッセージは含まれていません。
この調査により、Kaiはv350.10のテストAPIトークンが問題の原因である可能性が最も高いと確信しました。Kaiは、paymentservice のオーナーであるDeepuに、この調査結果を通知します。
Kaiの調査結果に基づいて、paymentservice のオーナーであるDeepuがSplunk Log Observer Connectでエラーログを確認します。そして、テストAPIトークンが問題の原因である可能性が高いというKaiの評価に同意しました。
Deepuは、Buttercup Gamesのサイトを既知の正常な状態に戻すことを試みるために、バージョンをv350.9に戻して暫定的な修正を実施し、その間にチームでv350.10への修正に取り組むことを決定しました。
バージョンv350.9に戻すことで問題が解決するかどうかを確認するための1つの方法として、DeepuはSplunk Log Observer Connectの左上隅にあるタイムピッカーを開き、Live Tail を選択します。Live Tailは、受信ログのサンプルのリアルタイムストリーミングビューを提供します。
DeepuがLive Tailビューを見ると、確かに paymentservice のログに、決済の失敗を示すメッセージが現れなくなりました。Buttercup Gamesのサイトが安定した状態に戻ったことを確認して、Deepuは、チームによるv350.10の修正作業のサポートを開始します。
Kaiは、Buttercup Gamesのウェブサイトでユーザーの購入完了を妨げていたフロントエンドの問題に対応し、解決することができました。RUMを使用してエラーのトラブルシューティングを開始し、考えられる原因としてフロントエンドのエラーの急増とバックエンドのレイテンシを特定しました。/cart/checkout のエンドポイントを掘り下げ、RUMのTag Spotlightビューを使用して完全なトレースを調査しました。これに基づいて、レイテンシがフロントエンドの問題ではないことが分かりました。次に、APMでパフォーマンスサマリーとエンドツーエンドのトランザクションワークフローを確認しました。サービスマップを見ると、Splunk APMが paymentservice をエラーの根本原因として特定したことに気が付きました。Kubernetesによる問題の可能性を排除した後、Tag Spotlightを使ってエラーのタグ値の相関関係を探しました。エラーが特定のバージョンでのみ発生していることに気づき、ログの詳細を調べることにしました。Log Observer Connectを使用し、ログの詳細を見て、APIトークンのエラーメッセージが「test」で始まっていることに気が付きました。
paymentservice のオーナーであるDeepuと相談し、テストAPIトークンが問題の原因である可能性が高いということで合意しました。Deepは修正を実施した後、Log Observer ConnectのLive Tailレポートを使用して、受信ログのリアルタイムストリーミングビューを監視しました。そして、決済のエラーが発生しなくなったことを確認しました。最終手順として、KaiはSplunk Log Observer Connectのクエリをメトリクスとして保存することで、チームにアラートを通知し、今後同様の問題を迅速に解決できるようにしました。
チャートまたはメトリクスに基づいてアラートを発するディテクターの作成方法の詳細については、アラートをトリガーするディテクターを作成する を参照してください。
ディテクターとアラートの設定方法の詳細については、Splunk Observability Cloudのアラートとディテクターの概要 を参照してください。
Splunk On-Call、PagerDuty、Jiraなどの通知サービスとのアラートの統合方法の詳細については、Splunk Observability Cloudを使用してサービスにアラート通知を送信する を参照してください。
Splunk RUMを使用してフロントエンドのエラーを特定しトラブルシューティングする方法の詳細については、ブラウザスパンでエラーを特定する を参照してください。
ビジネスワークフローの詳細については、トレースを関連付けてビジネスワークフローを追跡する を参照してください。
「関連コンテンツ」の使用方法に関する詳細は、Splunk Observability Cloudの関連コンテンツ を参照してください。
Kubernetesナビゲーターやその他のナビゲーターの使用方法に関する詳細は、Splunk Infrastructure Monitoring でナビゲーターを使用する を参照してください。
Tag Spotlightの使用方法に関する詳細は、Tag Spotlightを使用してサービスパフォーマンスを分析する を参照してください。