シナリオ:Kai がサービスに影響を及ぼすネットワークの問題を特定する 🔗
以下のシナリオでは、架空のeコマース企業であるButtercup Gamesの例を取り上げています。
Buttercup Games 社のサイト信頼性エンジニア(SRE)であるKai は、同社サイトの checkoutservice サービスでトランザクション量が減少しているというアラートを受け取りました。
彼らは手持ちの簡単なランブックを実行し、最近新しいものがデプロイされていないこと、サービスインスタンスが健全に稼動していること、ノードに十分なメモリとCPUがあることを確認しました。ログをチェックし、たくさんのエラーメッセージに気づきます。
現在、サービスオーナーのタイムゾーンでは午前2時なので、Kai も連絡する前にネットワークの問題を除外したいと考えています。
Kai はNetwork Explorer を開き、ネットワークエッジ ナビゲーターを確認することから調査を始めます。
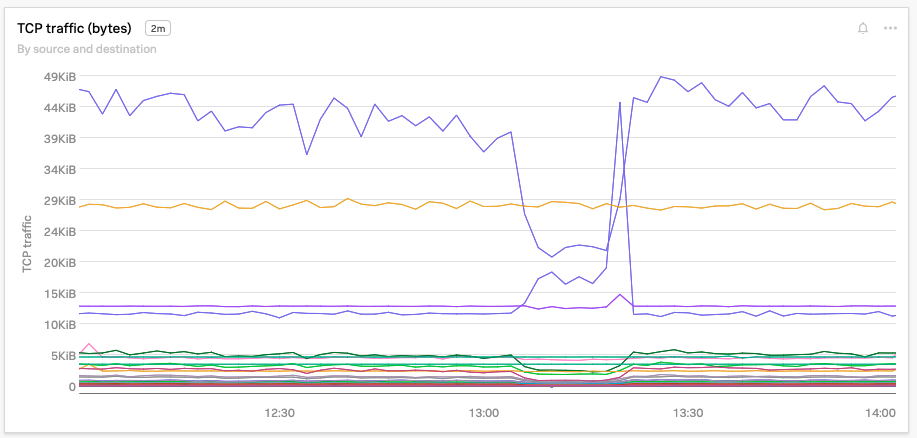
Kai はすぐに、checkoutservice へのトラフィック量が確かに減少していることに気づきます。
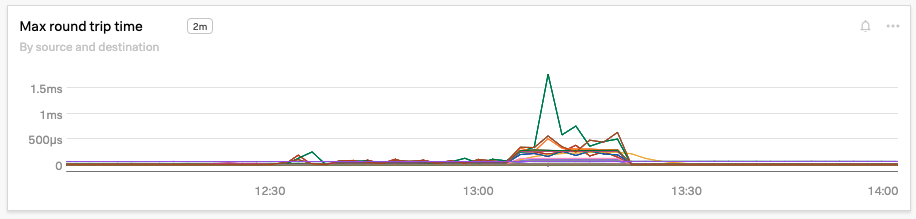
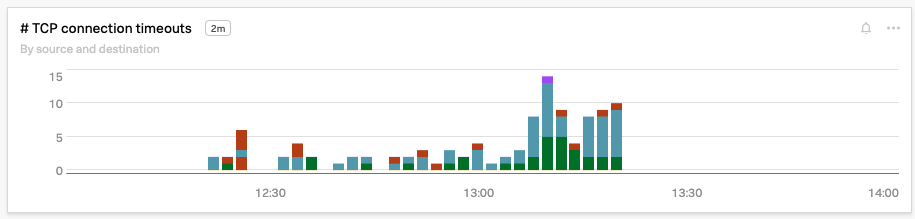
念のため、Kai も 最大ラウンドトリップタイム 、TCP接続タイムアウト 、再送信 のチャートを調べ、各指標が過去5分間に大幅に急上昇していることを確認します。
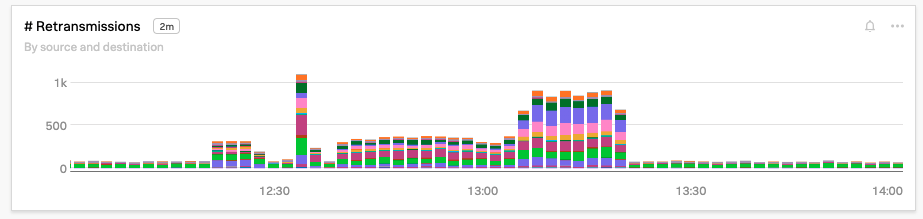
checkoutservice がクラウドプロバイダーのネットワーク問題の影響を受けていることを理解した Kai は、クラスタに新しい Kubernetes ノードをいくつか追加することで問題を解決し、 checkoutservice のポッドをローリングリスタートして問題のあるクラウドインスタンスから削除します。10分以内にトランザクション量は正常に戻ります。
Kai がインシデントレポートを書き終えてから30分後、クラウドプロバイダーは自社のステータスページに、このクラスタの可用性にネットワークの問題が発生したことを投稿し、Kai が以前に検知したことを確認しました。
Network Explorer の助けを借りて、Kai はネットワークの問題を自分でトラブルシューティングできるようになりました。クラウドプロバイダーからのアナウンスを待つ必要も、checkoutservice を担当する過重労働のチームを起こす必要もありません。