SLIの測定とアラート 🔗
Splunk Observability Cloudは、サービスレベル指標(SLI)とサービスレベル目標(SLO)を監視するためのパッケージ済みのソリューションを提供します。また、カスタムディテクターを使用して独自のシグナルを定義し、チームにとって最も重要なデータに対してアラートを出すこともできます。
Splunk Observability Cloudを他のSplunkプラットフォーム製品と併用する方法については、Splunk Observability CloudとSplunkプラットフォームのシナリオ のユースケースサンプルを参照してください。
SLIとSLO 🔗
SLIとは、顧客とのSLAを満たすために役立つため、重要です。SLIは、システムの可用性を測定するために使用されるメトリクスです。サービスレベル目標(SLO)とは、SLIによって測定される可用性の適切なレベルを決定するものです。サービスレベルアグリーメント(SLA)とは、SLOをどの程度の時間で達成するのか、また達成しなかった場合はどうするのかに関する顧客との約束です。
次の例は、システム可用性のSLIと、適切なSLOおよび顧客向けのSLAを示しています:
SLI:システムが利用可能である時間の割合。ここであなたは、トランザクションの完了にかかる時間が0.5秒未満であることを「利用可能」な状態と定義します。
SLO:あなたのシステムは、99.99%の時間において利用可能であることを目標とします。
SLA:1ヶ月間においてシステムが利用可能な状態にある時間が99.99%ではなかった場合、あなたは顧客にリベートを支払います。
ビジネス目標を達成するためには、SLIによって測定された正確なデータに基づいてSLOを設定し、管理する必要があります。Splunk Observability Cloudは、SLIを即座に監視および分析し、エラーバジェットの決定から推測を排除し、ビジネス目標を達成するための合理的なSLOの設定を支援します。次のセクションでは、SLIおよびSLOの測定とアラートに使用できるツール、「SLO管理」を紹介します。最後のセクションでは、Splunk Observability Cloudを使用してサービスに関する重要なシグナルを監視するためのその他の方法を詳しく説明します。
サービスレベル目標(SLO)管理 🔗
Splunk Observability Cloudは、ビジネスニーズとエンジニアリングの信頼性目標を一致させるのに役立つサービスレベル監視エクスペリエンスを提供します。サービスレベル監視とは、特定のサービスに関連するさまざまなサービスレベル指標(SLI)を測定、追跡、分析するプロセスです。これにより、デプロイしたソフトウェアやサービスの健全性をビジネス目標と比較することができます。SLO管理と独自のSLOの作成方法の詳細は、Splunk Observability Cloudにおけるサービスレベル目標(SLO)管理の概要 を参照してください。
サービス監視のその他の方法 🔗
SLO管理のほかにも、ビジネス目標との整合性を保つためにサービスに関する重要なシグナルを監視する方法は数多くあります。以下のセクションでは、それらの方法について詳しく説明します。
Splunk APM 🔗
Splunk APMで重要なサービスシグナルを監視できます。Splunk APMは、サービスを選択すると、インストルメントしたすべてのサービスとすべての推定サービス、それらの依存関係、およびそれぞれのSLIを表示するサービスマップを自動的に生成します。サービスマップでサービス間の依存関係を表示する を参照してください。サービスマップには、エラー率、ルートエラー率、レイテンシといったサービスのシグナルが表示されます。サービスマップの右側にあるパネルでは、サービスのエラー率、上位のエラーソース、レイテンシ別のサービスも表示されます。たとえば、各サービスの90パーセンタイルのサービスレイテンシのシグナルが5秒未満かどうかを追跡できます。以下のサービスマップでは、右側の レイテンシ別サービス(P90) のチャートでは、すべてのサービスのP90が1分未満であることがわかります。また、サービスマップ上の エラー率別サービス のチャートでは、エラー率を追跡することもできます。
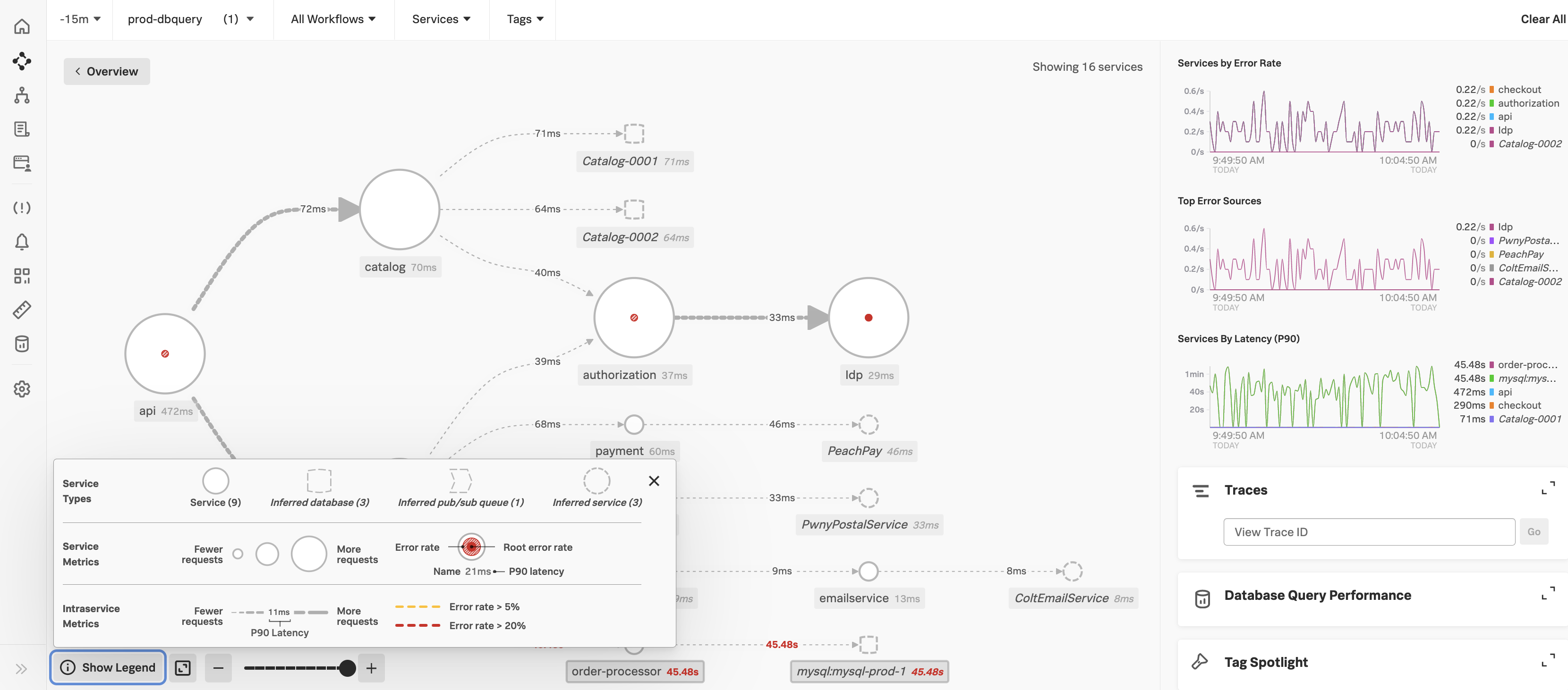
ディテクターを作成することで、サービスに対するアラートを発することができます。方法については、アラートをトリガーするディテクターを作成する を参照してください。また、内蔵のアラート条件を使用して、ディテクターをチャートにリンクすることもできます。内蔵のアラート条件 および ディテクターをチャートにリンク を参照してください。
Splunk APMの内蔵ダッシュボードには、インテグレーションしたすべてのサービスのシグナルが自動的に入力されます。詳細は 内蔵ダッシュボード を参照してください。以下のAPMダッシュボード例では、複数のシグナル(リクエスト率、リクエストのレイテンシ、リクエストレイテンシの分布、エラー率)が表示されています。
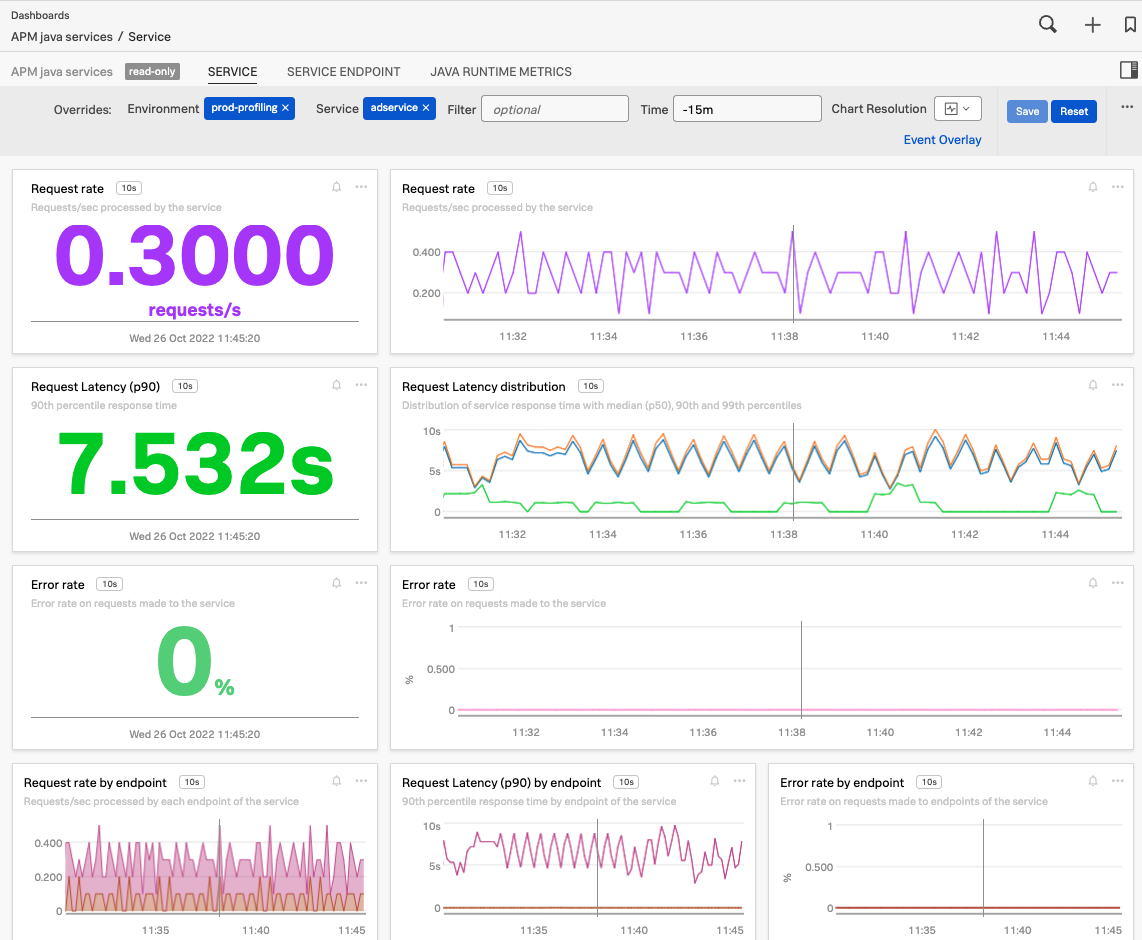
サービスのダッシュボードを表示するには、サービスマップ上でサービスを選択して、ダッシュボードの表示 を選択します。
ダッシュボードのリストと、ダッシュボードの作成、カスタマイズ、インポート、エクスポート、複製、および共有の方法については、Splunk Observability Cloudのダッシュボード を参照してください。パフォーマンスの追跡、ダッシュボードからのトラブルシューティング、将来的にダッシュボードやチャートでアラートを発するためのディテクターの作成の方法は、Splunk APMのダッシュボードを使用してサービスパフォーマンスを追跡する を参照してください。APMを使用したSLO管理のシナリオについては、シナリオ:Kaiが、ある顧客グループ向けのサービスのレイテンシのディテクターを監視する を参照してください。
Splunk Observability Cloudのアラートとディテクター 🔗
AutoDetectは、サポート対象のインテグレーションを構成する際にSplunk Observability Cloudが自動的に作成する読み取り専用のアラートとディテクターの一式です。前のセクションで説明したように、カスタムディテクターを設定して独自のシグナルを定義し、自分にとって重要なデータについてアラートを出すこともできます。詳細は、AutoDetectアラートおよびディテクターの使用とカスタマイズ を参照してください。
Splunk Infrastructure Monitoring 🔗
Infrastructure Monitoringは、インフラストラクチャ、アプリケーション、およびビジネスメトリクスの全体をリアルタイムで監視するためのカスタムメトリクスプラットフォームです。ご利用のデプロイ内のサーバー、仮想マシン、コンテナ、データベース、パブリッククラウドサービス、コンテナオーケストレーション、サーバーレスその他のバックエンドコンポーネントから、健全性データとパフォーマンスデータを収集します。200を超えるインテグレーションとダッシュボードを使用して、インフラストラクチャ全体を1つの画面で監視し、クラウド移行の作業を大幅にスピードアップできます。
例えば、AWS ELBインスタンスの直近1分間のレイテンシを表示する以下のナビゲーターチャートのように、パッケージ済みのナビゲーターでシグナルを監視します:
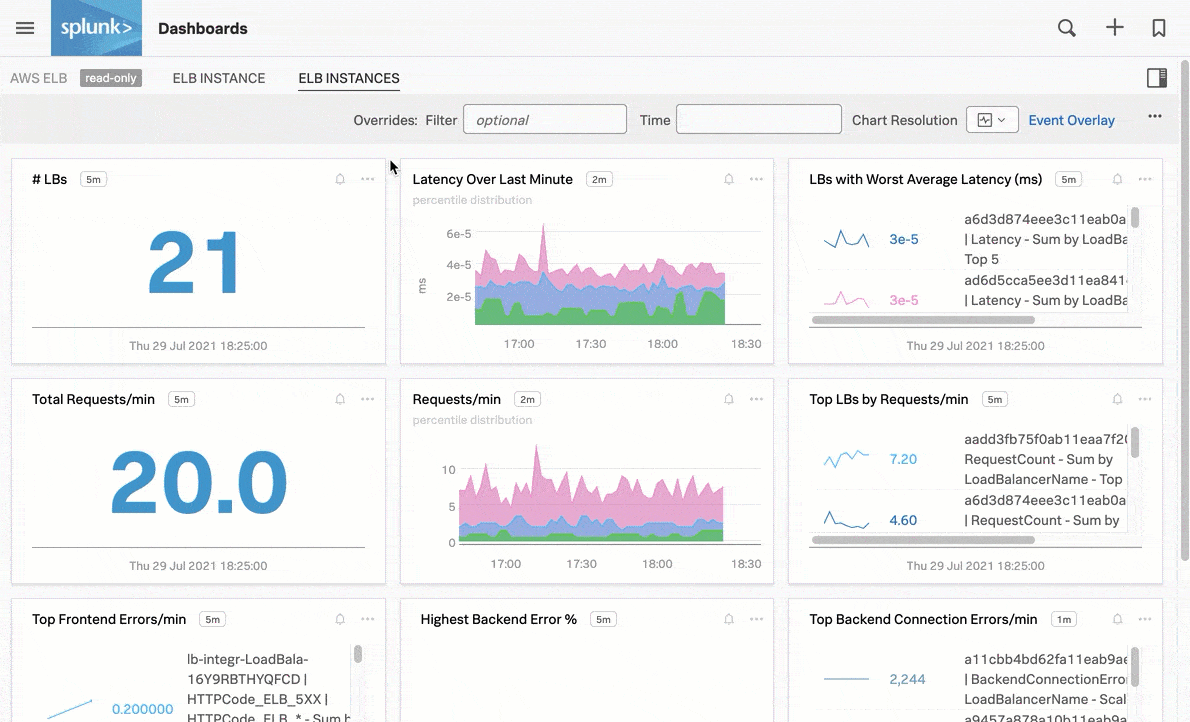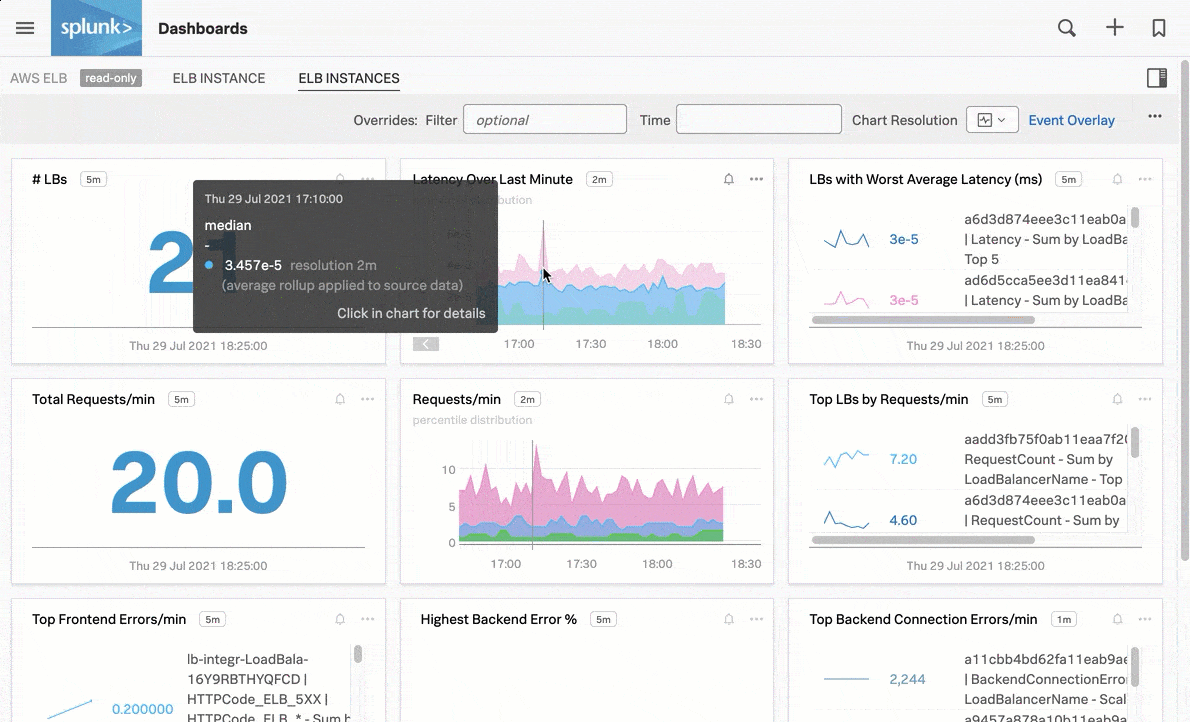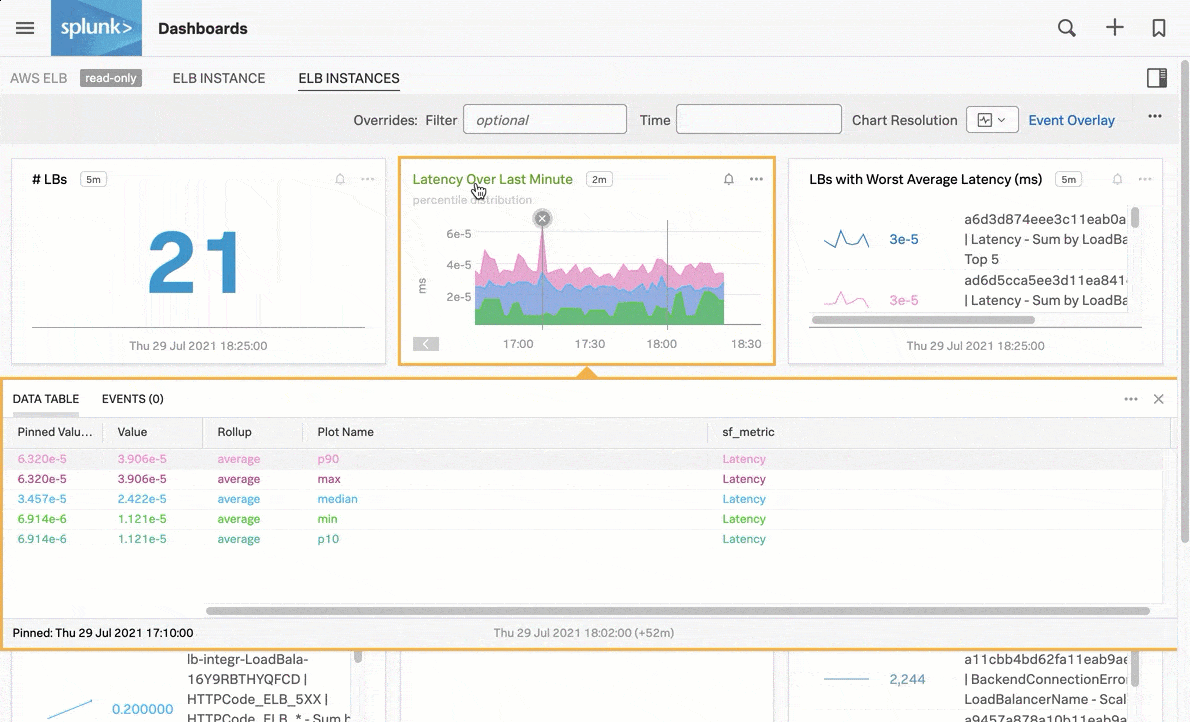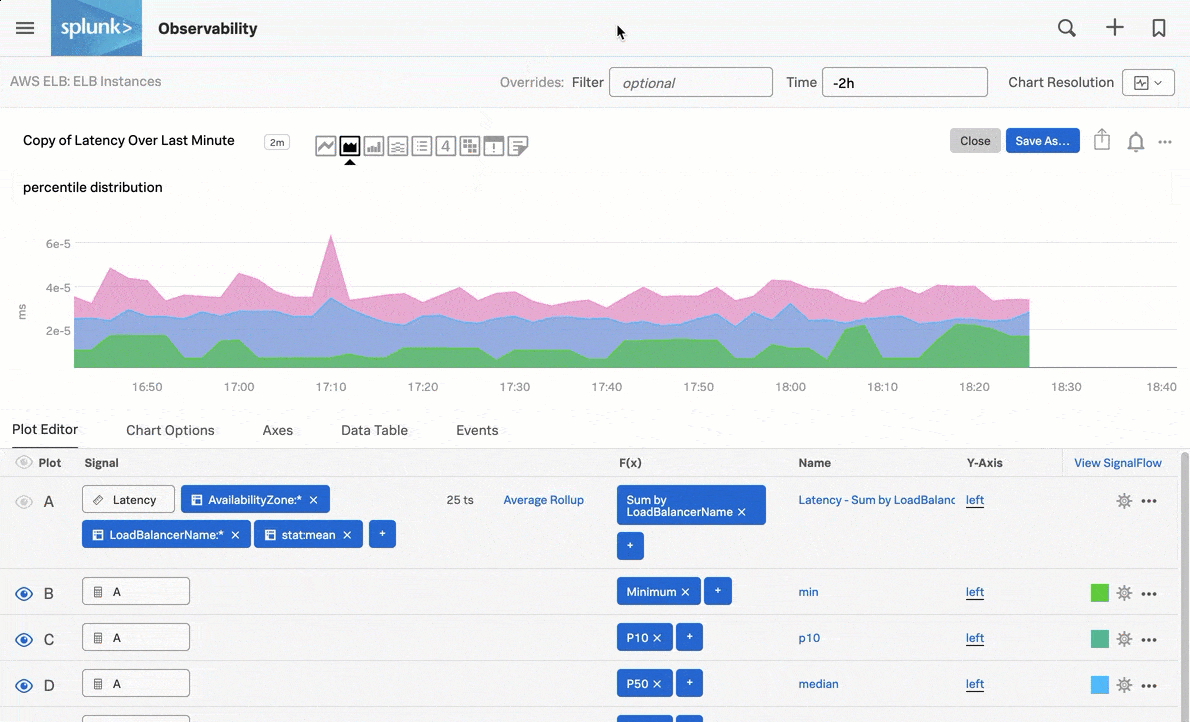
パッケージ済みのナビゲーターに加えて、自分にとって重要なカスタムのInfrastructure Monitoringデータに対して、アラートとディテクターを設定することもできます。Splunk Observability Cloudのアラートとディテクターの概要 を参照してください。
Splunk Infrastructure Monitoringの仮想メトリクスは、メトリクスを自動的に収集、集計、定義することで、シグナルの測定を支援します。仮想メトリクスは、利用可能なさまざまなオプションの中から最も適切なメトリクスソースを選択するための複雑性を取り除きます。Splunk Infrastructure Monitoring の仮想メトリクス を参照してください。
Real User Monitoring(RUM) 🔗
Splunk RUMは、UIにおけるユーザーのエクスペリエンスという観点からシグナルを表示します。以下の例では、Tag SpotlightビューのRUMダッシュボードは、15分間におけるネットワークリクエストとエラーの総数を表示するチャートから始まっています。次のチャートには、URL名、HTTPメソッド、および HTTPステータスコードごとにリクエストとエラーの数が表示されています。
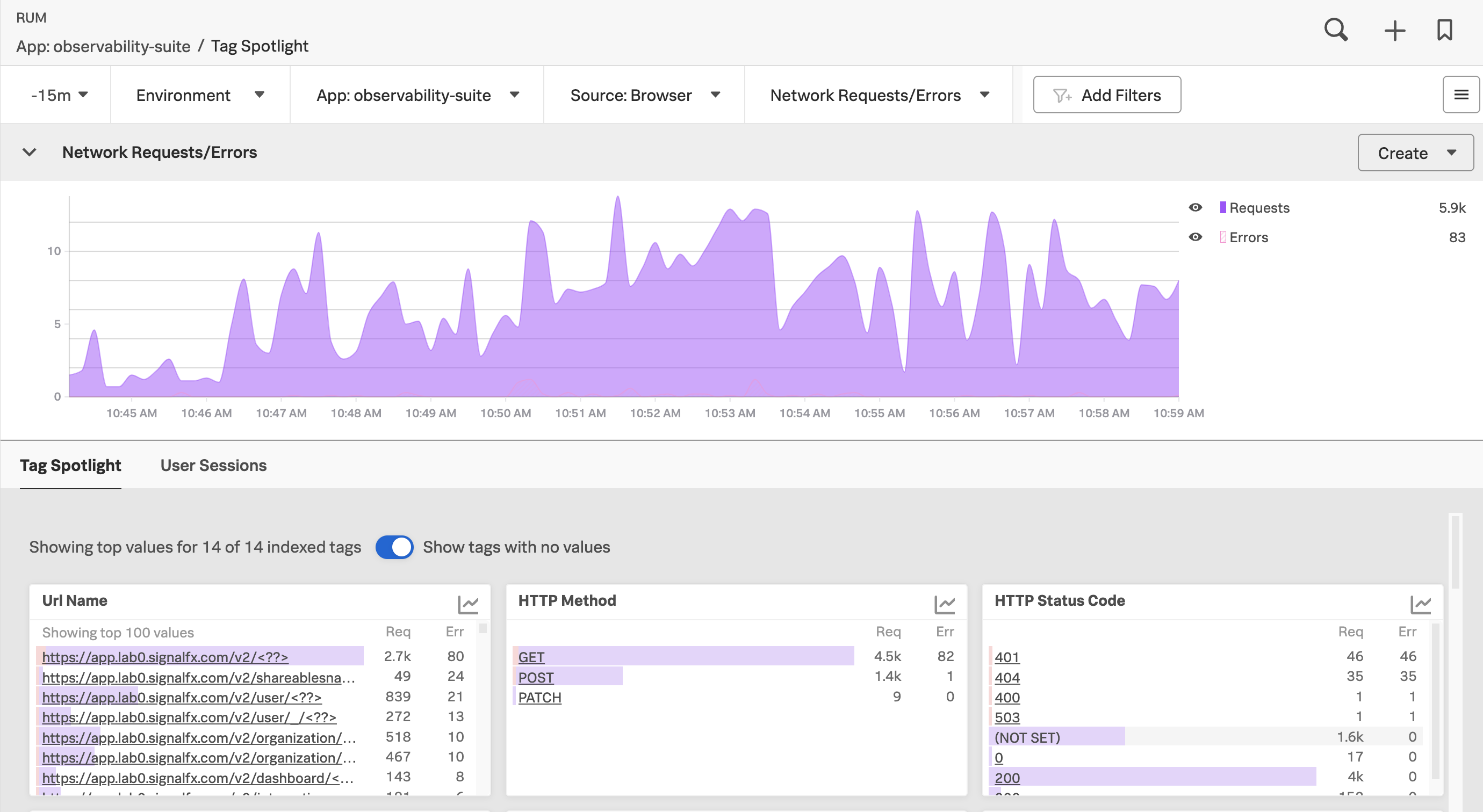
RUMを使用してできることの詳細については、Splunk RUM の概要 を参照してください。また Splunk RUM を使用してアプリケーションとサービスを監視するシナリオ には、RUMの使用方法の例を複数記載しています。
Splunk Synthetic Monitoring 🔗
Splunk Synthetic Monitoringで、ユーザーより先にSLOをテストしましょう。ウェブアプリケーションのパフォーマンスを積極的に監視すれば、ユーザーに影響が及ぶ前に問題を修正できます。技術チームとビジネスチームは、Synthetic Monitoringを使用して詳細なテストを作成し、ウェブサイト、ウェブアプリ、およびリソースのスピードと信頼性を、開発サイクルのあらゆる段階で長期にわたって監視できます。Synthetics Monitoringできることについては、Splunk Synthetic Monitoringの概要 を参照してください。
Synthetic Monitoringを使用すべきタイミングをシナリオで学ぶには、シナリオ:ユーザー向けアプリケーションのパフォーマンスを監視する を参照してください。
合成テストに対してアラートを発することで、Synthetic Monitoringは開発チームや開発運用チームにとって実用的なものになります。ブラウザーテストとアップタイムテストを設定して、好みの頻度でサイトやアプリケーションを監視できます。各テストは、実行するたびに一連のメトリクスを取得します。テストが失敗したときに通知するアラートを設定する方法は、ディテクターとアラート を参照してください。