シナリオ:Kaiがサーバーのレイテンシを監視するディテクターを作成する 🔗
Buttercup Gamesのサイト信頼性エンジニアであるKaiは、Buttercup Gamesの顧客から、ゲームサーバーの高遅延に関するチケットを数多く受け取っています。Kaiは、ホストマシンのサーバーのレイテンシを監視して、顧客に影響が及ぶ前に高遅延の問題を迅速に特定し解決するための信頼性の高い方法を必要としています。
Splunk Observability Cloudを使用することで、サーバーのレイテンシが一定期間にわたって閾値を超えた場合にアラートを出すディテクターを作成することができます。
アラートに使用するデータを定義する 🔗
Kaiは、Splunk Observability Cloud の Detectors & SLOs ページを開き、New Detector を選択してゼロからディテクターを作成します。
ディテクターに名前をつけた後、Infrastructure or Custom Metrics Alert Rule を選択しました。
必要なメトリクスである latency を選択し、このメトリクスをレポートするプレビューディテクターを確認します:
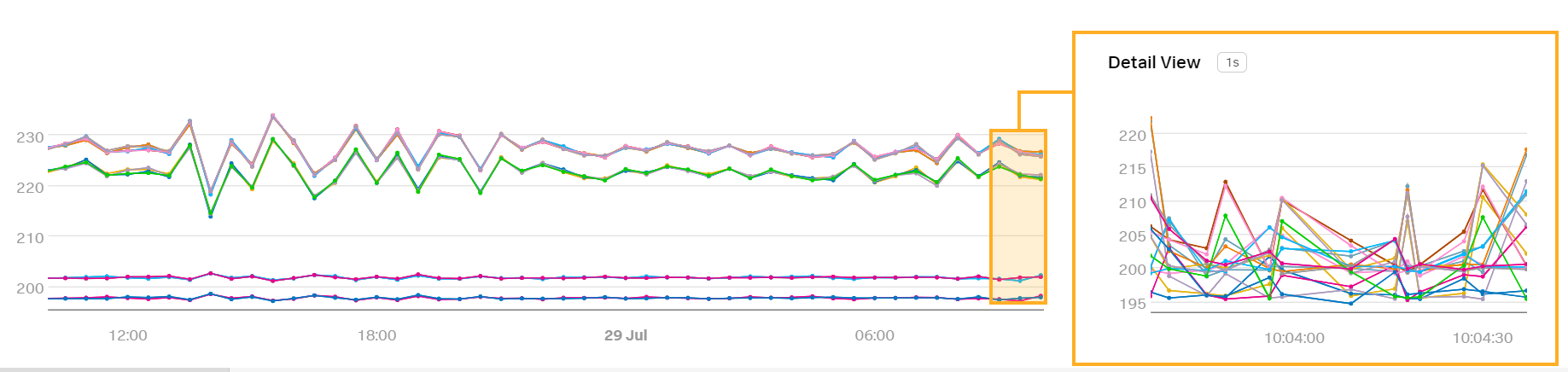
Kaiはシグナルがどのようにレポートされるかを変更するために分析を適用することができます。Kaiは1分間の時間窓のサーバーレイテンシの平均をレポートしたいと考えているため、Mean:Transformation 分析を適用し、期間を1分と入力します。
プレビューディテクターはKaiが適用した分析を反映して変化します:
アラート条件を選択する 🔗
Kaiは、アラート条件をいくつかのオプションから選択することができます。アラート条件は、アラートをトリガーする動作のタイプを決定します。
Kaiは、サーバーレイテンシが一定期間にわたって特定の点を超過したときを把握したいと考えているため、Static threshold のアラート条件を選択します。他のケースなら、別のアラート条件を選択するとよいでしょう。例えば、サーバーのレイテンシが急激に増加したときにアラートを受けたい場合は、Sudden change の条件を選択するとよいでしょう。
アラート設定をカスタマイズする 🔗
Alert Setting メニューで、Kaiは以下のフィールドに希望する値を入力します:
フィールド |
値 |
説明 |
|---|---|---|
Threshold |
280 |
|
Duration |
1 minute |
|
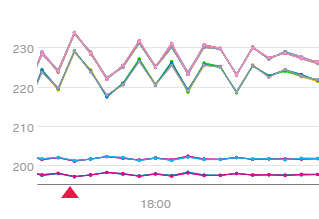
ディテクタープレビューでは、ディテクターがアラートをトリガーすると、タイムスタンプに赤い矢印が表示されます:
アラートメッセージと受信者を設定する 🔗
アラート条件を作成した後、Kaiは Alert Message を選択します。Kaiはbuttercupgames.com/alertsのランブックに入り、サーバーのメモリ負荷とディスク使用量をチェックするための内部ヒントを追加します:

ランブックとヒントにより、アラートを素早く表示し、アラートがトリガーされたときに何をすべきかを思い出すことができます。
次に、Alert Recipients を選択し、アラート受信者リストに自分のメールアドレスを追加します。メールアドレスを追加した後、このアラートルールを有効化します。
まとめ 🔗
Kaiは、1分間の平均サーバーレイテンシが1分間にわたって閾値の280ミリ秒を超えるとアラートを送信するディテクターを作成しました。このディテクターにより、以前は気づかなかったサーバーレイテンシの問題を迅速に検出し、解決することができます。
さらに詳しく 🔗
ディテクターの作成方法の詳細については、アラートをトリガーするディテクターを作成する を参照してください。
アラート条件と適切な条件の選択方法の詳細については、内蔵アラート条件 を参照してください。