シナリオ:Kaiが誤ったアラートを発するディテクターを修正する 🔗
Buttercup Gamesのサイト信頼性エンジニアであるKaiは、新しいディテクターを作成しており、サーバーのレイテンシが260ミリ秒より高くなったときにアラートを受け取りたいと考えています。Kaiは、自社のサービスにおいて260ミリ秒未満のレイテンシは健全であるとみなしており、レイテンシがこの閾値を超えたときにアラートを受け取りたいと考えています。
過剰なアラートを減らす 🔗
Kaiは、以下の手順で、レイテンシをレポートするディテクターを作成します:
Detectors & SLOs ページで、New Detector を選択します。
Infrastructure or Custom Metrics Alert Rule を選択します。
アラートを発したいシグナル、つまり
latencyを入力します。Static Threshold のアラート条件を選択します。
Alert settings タブで、「260ミリ秒」の閾値を入力します。
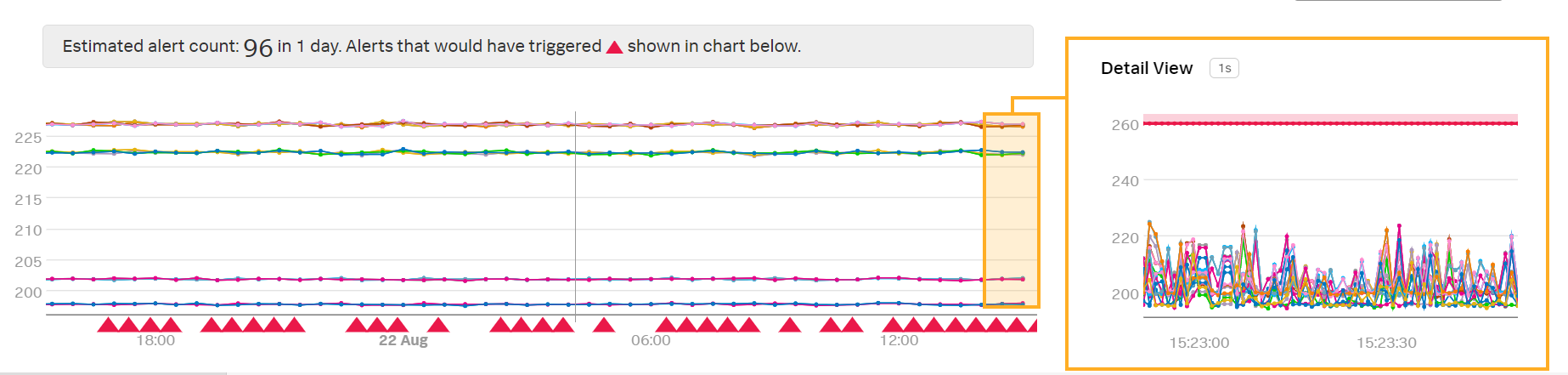
プレビューディテクターで、Kaiはこのアラート条件が非常に多くのアラートをトリガーすることに気が付きます:
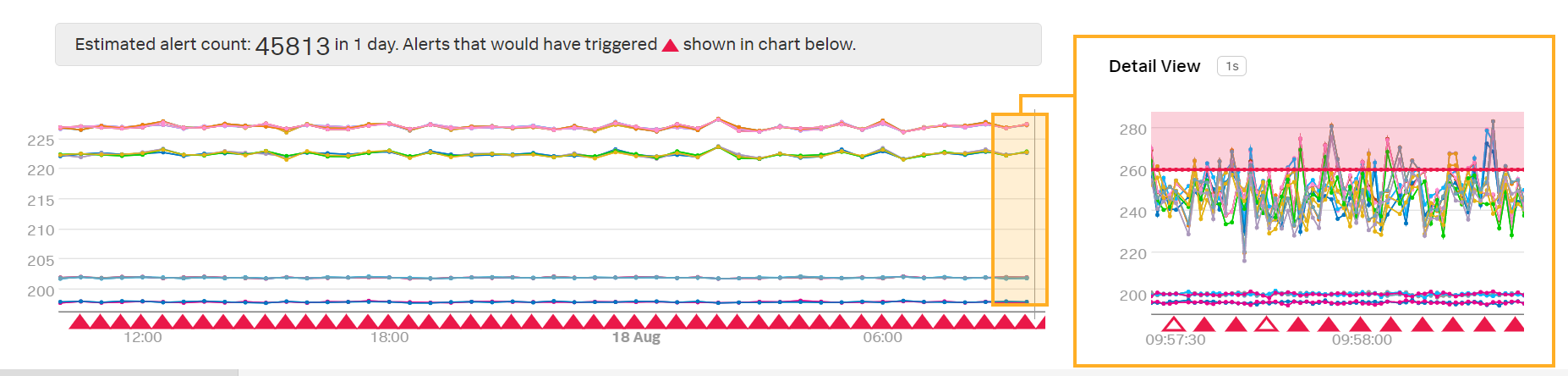
「詳細ビュー」でデータのネイティブ解像度を見て、Kaiは、レイテンシの偶発的な急上昇によってアラートが発されることを確認します。Kaiは、たとえば、レイテンシが260ミリ秒を超えた状態が少なくとも1分間にわたるなど、レイテンシが長期間にわたって高い場合にのみアラートが発されることを希望しています。
Kaiは、以下の手順でディテクターを修正します:
Alert settings メニューで、Trigger sensitivity を選択します。
Duration を選択します。
Duration のボックスで、1m と入力します。
このディテクターは、遅延したデータポイントのレイテンシが1分間にわたって260ミリ秒より高い場合にのみアラートをトリガーします。このアラート条件によって、Kaiが受信するアラートの数が減ります:
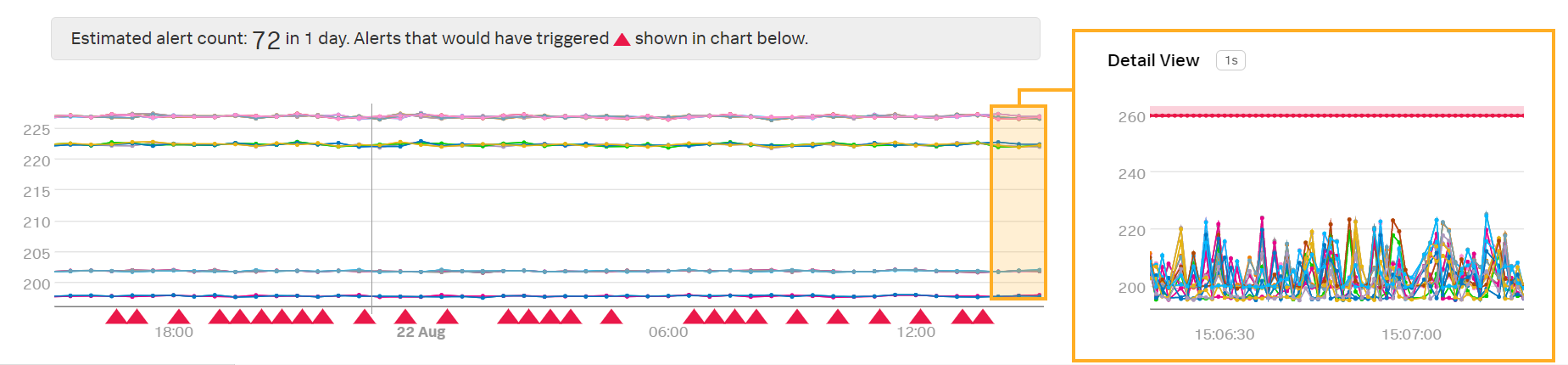
欠落したアラートのトラブルシューティング 🔗
ディテクターを作成した後、Kaiは、ディテクターがアラートを発するはずのタイミングでアラートを発していないことに気づきます。
Kaiは、いくつかのデータポイントがプレビューに表示されていないことに気づきました。アラートがトリガーするためには、すべてのデータポイントが時間通りに到着し、1分間の期間にわたって閾値を超える必要があります。
データポイントの欠落の問題を修正するためには3つのオプションがあります:
外挿ポリシーを変更する
メトリクスに集計を適用する
継続期間のパーセンテージを使用する
外挿ポリシーを変更する 🔗
Kaiは、データポイントの欠落を考慮に入れるために、データの外挿ポリシーを変更することができます。以下の手順を実行します:
ディテクターメニューで、Alert signal を選択します。
レイテンシシグナルの設定アイコンを選択します。
Advanced Options で、Extrapolation Policy を選択します。
Last Value を選択します。
Kaiのメトリクスは、期待されたデータポイントが時間通りに到着しないときはいつでも、最後に受信したデータポイントをレポートするようになりました。
Kaiは新しい外挿ポリシーのプレビューディテクターを確認します:
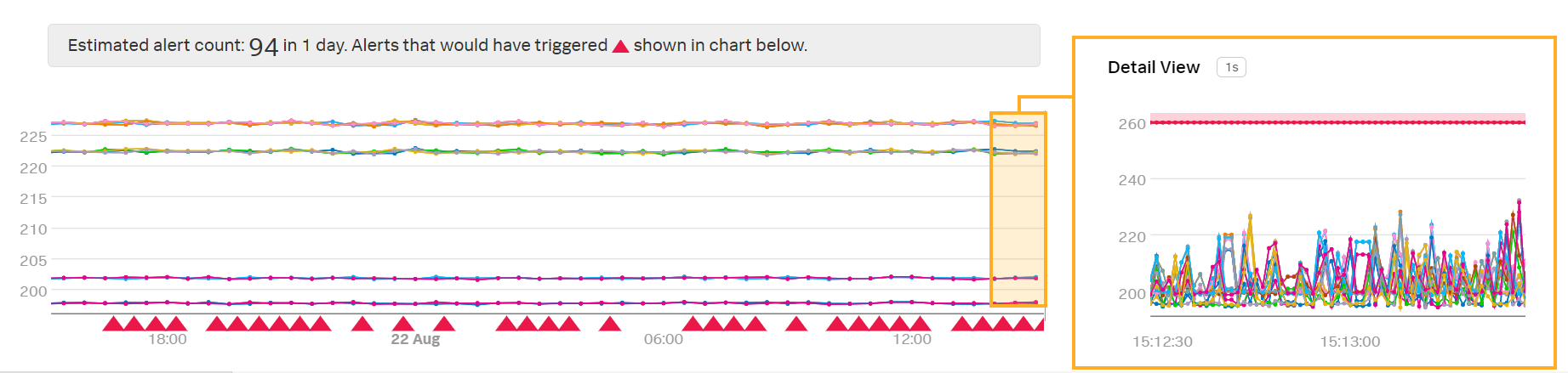
注釈
Last Value は、偶発的に欠落するデータポイントを処理するのに便利ですが、データポイントに欠落が多い場合は、多くのデータポイントが外挿されると、不要なアラートを発してしまう可能性があります。
メトリクスに集計を適用する 🔗
Kaiは、メトリクス分析を調整することにより、メトリクスのレポート方法を変更することができます。以下の手順を実行します:
ディテクターメニューで、Alert signal を選択します。
レイテンシシグナルに Add Analytics を選択します。
Mean を選択し、次に Mean:Aggregation を選択します。
Kaiのディテクターは、個々のサーバーマシンのデータポイントの欠落を考慮して、すべてのレイテンシ値の平均値をレポートします。
Kaiは、Mean:Aggregation の分析が適用されたプレビューディテクターを確認します:
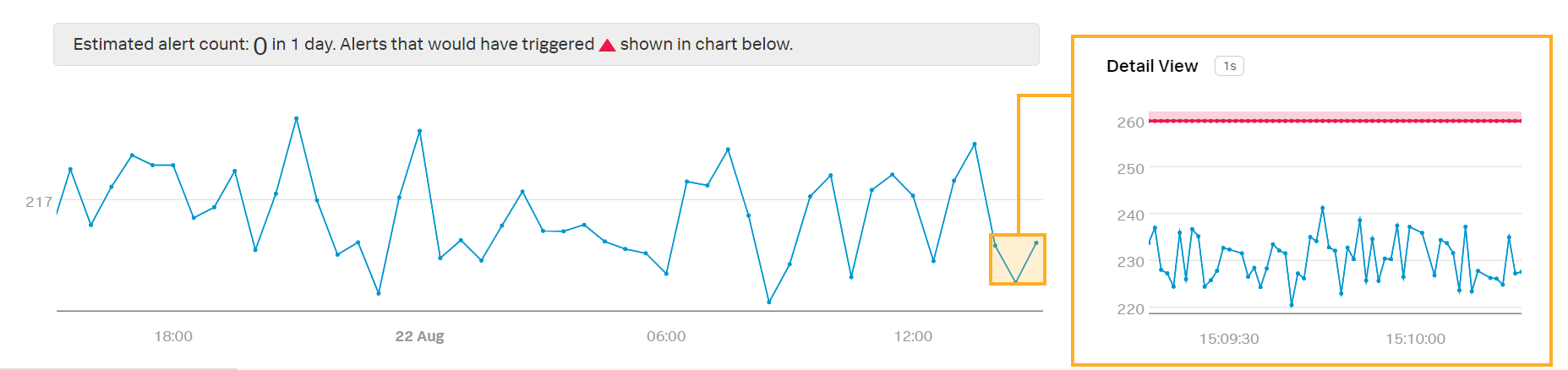
注釈
このディテクターはすべてのレイテンシ値の平均を取るため、個々のサーバーマシンが高遅延を示した場合にKaiはアラートを受け取らない可能性があります。Kaiは、プレビューの変化を考慮してアラート条件の閾値を調整する必要があるかもしれません。
継続期間のパーセンテージを使用する 🔗
Kaiは、「継続期間のパーセンテージ」のアラート設定を使用することで、欠落したデータポイントを考慮に入れることができます。以下の手順を実行します:
ディテクターメニューで、Alert settings を選択します。
Trigger sensitivty を選択します。
percent of duration を選択します。
アラートをトリガーさせたい継続時間のパーセンテージを入力します。Kaiは、80 と入力しました。
このディテクターは、1分間に受信したデータポイントの80%が260ミリ秒を超えている場合にアラートをトリガーします。Kaiのレイテンシデータは10秒ごとに到着するため、1分間に6つのデータポイントがあるはずです。このアラートをトリガーするには、6つのデータポイントのうち5つが到着し、260ミリ秒を超えている必要があります。
Kaiは、新しいアラート設定が適用されたプレビューディテクターを確認します:
注釈
欠落したデータポイントが多数ある場合、依然としてこのディテクターはKaiが期待したタイミングでアラートをトリガーしない可能性があります。この場合、Kaiはデータポイントが欠落している原因を突き止めるか、外挿などの他の方法を使用して欠落データポイントを考慮に入れる必要があります。
欠落したデータポイントのトラブルシューティングの詳細については、タイムスタンプの問題のトラブルシューティング を参照してください。
まとめ 🔗
このシナリオでは、Kaiはアラート設定を変更することで不要なアラートを排除しました。
また、期待通りにアラートが発せられないディテクターを修正するための3つのオプションを探求しました:
外挿ポリシーを変更する
メトリクスに集計を適用する
継続期間のパーセンテージを使用する
さらに詳しく 🔗
ディテクターのトラブルシューティングの詳細については、Splunk Observability Cloudのディテクターのトラブルシューティング を参照してください。