Splunk APMでエラースパンを分析する 🔗
Splunk APMのエラー検出機能を使用して、システムやアプリケーションの具体的なエラー原因を特定できます。
Splunk APMが推定サービスを検出するしくみ 🔗
Splunk APMの各 span は単一の操作をキャプチャします。Splunk APMは、スパンがキャプチャした操作でエラーが発生した場合、そのスパンをエラースパンとみなします。その条件の定義は以下の通りです:
スパンの
otel.status_codeフィールドがERRORである場合。otel.status_codeは、Splunk Distribution of the OpenTelemetryのインストルメンテーションで、ネイティブのOTel フィールドspan.statusを使って設定されます。span.statusと、それにしたがってotel.status_codeは、HTTPステータスコードまたはgRPCステータスコードに基づいて設定されます。OpenTelemetryのインストルメンテーションでどのステータスコード値が OpenTelemetryによるHTTPステータスコードの処理方法 を
otel.status_codeと設定するかについては、ERRORを参照してください。OpenTelemetryのインストルメンテーションでどの
rpc.grpc.status_codeタグ値がotel.status_codeをERRORと設定するかについては、OpenTelemetryによるgRPCステータスコードの処理方法 を参照してください。
スパンの
errorタグが真値(Falseまたは0以外の値)に設定されている場合。
otel.status_code の詳細は、GitHubの「OpenTelemetryの非OTLP形式への変換」の仕様の「スパンステータス」セクション( https://opentelemetry.io/docs/specs/otel/common/mapping-to-non-otlp/#span-status )を参照してください。span.status の詳細は、GitHubの「OpenTelemetryのトレースAPI仕様」の「ステータスの設定」セクション( https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/trace/api.md#set-status )を参照してください。
OpenTelemetryによるHTTPステータスコードの処理方法 🔗
以下の表は、OpenTelemetryのセマンティック規約に従って、OpenTelemetryのインストルメンテーションにおいてHTTPステータスコードが span.status フィールドと、それに続いて otel.status_code を設定するためにどのように使われるかの概要を示しています。詳しくは、GitHubの「OpenTelemetryのHTTPスパンのセマンティック規約」( https://github.com/open-telemetry/semantic-conventions/blob/main/model/http/spans.yaml )を参照してください。
エラータイプ |
サーバー側のスパン |
クライアント側のスパン |
|---|---|---|
|
スパンに別のエラーがない限り、 |
スパンに別のエラーがない限り、 |
|
サーバー側のエラーとはみなされない。 |
クライアントのエラーとしてカウント。 |
|
|
|
OpenTelemetryによるgRPCステータスコードの処理方法 🔗
gRPCスパンがサービスのエラー率にカウントされるかどうかを判断するために、Splunk APMはOpenTelemetryのインストルメンテーションによって設定された otel.status_code フィールドを調べます。以下のロジックが、OpenTelemetryのセマンティック規約に従ってインストルメンテーションにより適用されます:
コード |
ステータス |
サーバー側のスパン |
クライアント側のスパン |
|---|---|---|---|
0 |
OK |
未設定 |
未設定 |
1 |
CANCELLED |
未設定 |
エラー |
2 |
UNKNOWN |
エラー |
エラー |
3 |
INVALID_ARGUMENT |
未設定 |
エラー |
4 |
DEADLINE_EXCEEDED |
エラー |
エラー |
5 |
NOT_FOUND |
未設定 |
エラー |
6 |
ALREADY_EXISTS |
未設定 |
エラー |
7 |
PERMISSION_DENIED |
未設定 |
エラー |
8 |
RESOURCE_EXHAUSTED |
未設定 |
エラー |
9 |
FAILED_PRECONDITION |
未設定 |
エラー |
10 |
ABORTED |
未設定 |
エラー |
11 |
OUT_OF_RANGE |
未設定 |
エラー |
12 |
UNIMPLEMENTED |
エラー |
エラー |
13 |
INTERNAL |
エラー |
エラー |
14 |
UNAVAILABLE |
エラー |
エラー |
15 |
DATA_LOSS |
エラー |
エラー |
16 |
UNAUTHENTICATED |
未設定 |
エラー |
gRPCのステータスコードの取り扱いについては、GitHubのOpenTelemetryの仕様( https://github.com/open-telemetry/semantic-conventions/blob/main/model/rpc/spans.yaml )を参照してください。
MetricSetでのエラースパンのカウント方法 🔗
エンドポイントレベルのMonitoring MetricSetsを生成するために、Splunk APMはエンドポイントスパン( span.kind = SERVER または span.kind = CONSUMER のスパン)をエラーメトリクスデータに変換します。スパンがSplunk APMのエラールールによってエラーとみなされた場合、そのスパンは、そのスパンに関連するエンドポイントのMonitoring MetricSetのエラーとしてカウントされます。
サービスレベルのMonitoring MetricSetsは、サービスの各エンドポイントのエラースパンの数に基づいています。
サーバー側とクライアント側のエラーカウント 🔗
Splunk APMは、クライアント側のスパンと呼ばれるクライアントへのリクエストをキャプチャするスパンや、サーバー側のスパンと呼ばれるサービスが受信したリクエストなど、インストルメントされたすべてのサービスからのすべてのスパンをキャプチャします。特定のケースでは、サービスがエラーを返すと、開始スパンと受信スパンの両方にエラーが登録されることがあります。エラーレポートの重複を避けるため、Splunk APMはサーバー側のエラースパンのみをMetricSetsとエラー合計にカウントします。
たとえば、service_a が service_b にコールし、両方のサービスが完全にインストルメントされている場合、Splunk APMは以下の2つのスパンを受信します:
span_1。service_bへのコールを行うservice_aをキャプチャするspan.kind = CLIENTのスパン。span_2。リクエストを受信するservice_bをキャプチャするspan.kind = SERVERのスパン。
service_b が 500 エラーを返した場合、両方のスパンがそのエラーを受信します。エラーの二重カウントを避けるため、Splunk APMはサーバー側のスパン( span_2 )のみをMetricSetsおよびエラー合計にエラーとしてカウントします。
エラーと根本原因エラーの違い 🔗
エラーの根本原因を特定するために、Splunk APMはエラーと根本原因エラーを区別します。たとえば、Tag Spotlightのリクエストとエラーのグラフでは、濃い色を付けてエラー合計から根本原因エラーを区別します:
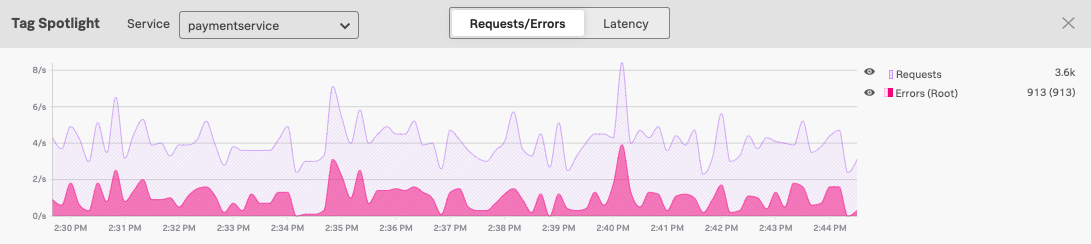
トレース内の特定のスパンでエラーが発生した場合、そのエラーはトレース内の他のスパンに伝搬する可能性があります。Splunk APMが推定サービスを検出するしくみ に記載されている基準に基づいてエラーを含むと判断されたスパンは、すべてエラースパンとなります。Splunk APMは、エラースパンの連鎖の起点となるエラーを 根本原因エラー として指定します。
例えば、次のスクリーンショットでcheckoutのトレースについて考えてみましょう:
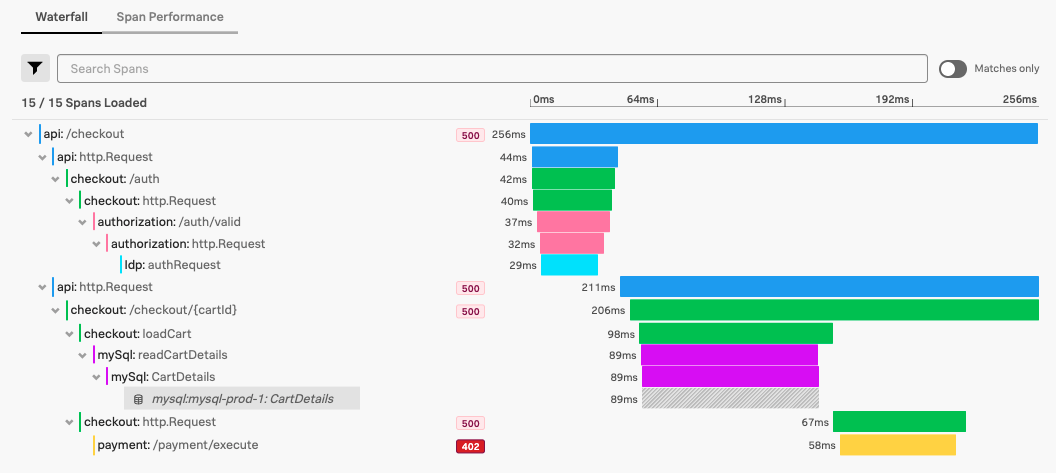
checkout サービスは、authorization サービス、 checkout サービス、および payment サービスにHTTPリクエストを行っています。 payment サービスへのHTTPリクエストの結果、402 「Payment Required」というエラーが発生しています。 payment サービスへのリクエストが失敗したため、 checkout サービスへの開始リクエストと http.Request もエラーになります。
この場合、ソースエラー、つまり根本原因エラーは、payment サービス内の 402 エラーです。checkout および api のサービスに現れる 500 のエラーは、その結果として生じたエラーです。
根本原因エラーカウントは、これらの根本原因エラーのカウントを示し、標準のエラーカウントは、すべての根本原因エラーおよび後続エラーの合計カウントを示します。
Splunk APMでエラーロジックをカスタマイズする 🔗
一部のケースでは、エラーロジックのデフォルトをオーバーライドするようにインストルメンテーションを変更したり、自分にとって重要なエラーを追跡するための別の方法を考案したりする方が良い場合もあります。
4xxステータスコードをエラーとしてカウントする 🔗
デフォルトでは、Splunk APMは、4xx ステータスコードを持つサーバー側のスパンをエラーとしてカウントしません。4xx ステータスコードは、リクエストを処理するサービスの問題に関連するというよりも、リクエスト自体の問題に関連する場合が多いからです。
例えば、ユーザーが endpoint/that/does/not/exist にリクエストを行った場合、サービスが返す 404 ステータスコードは、そのサービスに問題があることを意味するものではありません。そうではなく、存在しないエンドポイントを呼びだそうとしたリクエストに問題があったことを意味します。同様に、ユーザーがアクセス権のないリソースにアクセスしようとすると、サービスは 401 というステータスコードを返す可能性があります。これは通常、サーバー側のエラーの結果ではありません。
しかし、アプリケーションのロジックによっては、4xx ステータスコードは、特にクライアント側のリクエストにとっては意味のあるエラーになる場合があります。4xx エラーを監視するには、次を実行してみてください:
利用可能な場合は、HTTPステータスコードのスパンタグごとにパフォーマンスを分析する。
インストルメンテーションをカスタマイズして、意味のある
4xxステータスコードを持つスパンのspan.statusをErrorに設定する。
例えば、Kaiがあるサービスから返される 401 エラーの割合についてアラートを出したい場合は、次の手順を実行します:
OpenTelemetryのセマンティック規約のバージョン1.16.0以下をサポートするライブラリで
http.status_codeをインデックス化する。または、OpenTelemetryのセマンティック規約のバージョン1.17.0以降をサポートするライブラリでhttp.response.status_codeをインデックス化する。スパンタグをインデックス化してTroubleshooting MetricSetsを作成する を参照してください。各ステータスコードの時系列を取得するため、サービスのエンドポイントのステータスコードタグでカスタムのMonitoring MetricSetを作成する。カスタムディメンションを使用してMonitoring MetricSetを生成する を参照してください。
全リクエスト数と比較した
401のエラー率に関するアラートを設定する。Splunk APMでディテクターとアラートを設定する を参照してください。
エラーロジックをカスタマイズして5xxステータスコードを破棄する 🔗
デフォルトでは、Splunk APMは 5xx のステータスコードを持つサーバー側のスパンをエラーとしてカウントします。 5xx のエラーは一般的にサービスの利用不可の状況に関連するためです。
例えば、サーバー側のスパンにおける 503 「service too busy」のエラーは、デフォルトでエラーとしてカウントされます。監視しているサービスが公開ウェブサイトのフロントエンドである場合、 503 のエラーに遭遇したユーザーはウェブサイトを利用することができず、ユーザーインタラクションの損失や収益の損失につながります。この場合、 503 は真のエラーです。
しかし、アプリケーションのロジックによっては、5xx コードを意味のあるエラーと考えない可能性もあります。例えば、サービスがバッチプロセッサーである場合、 503 のエラーは正常なフロー制御メカニズムで、後でのクライアントによるプロセスの再試行をトリガーするものである可能性があります。 503 ステータスコードをエラーとしてカウントするデフォルト設定をオーバーライドするには、 503 エラーが問題にならないスパンでは span.status を OK に設定するようにインストルメンテーションを修正することができます。