Splunk Observability Cloudの分析リファレンス 🔗
Splunk Observability Cloudは、すべてのチャートとディテクターに分析言語SignalFlowを使用しています。SignalFlowの分析メソッドを使用して、オブザーバビリティデータに対して計算を実行し、その出力をチャートで可視化することができます。チャートで分析を使用するには、Plot Editor タブで Add Analytics を選択します。
チャートビルダービューで使用できるのは、SignalFlowメソッドのみです。SignalFlow関数を使用するには、View SignalFlow を選択してSignalFlowプログラムを表示します。SignalFlowプログラムの書き方の詳細については、『Splunk Observability Cloud Developer Guide』の SignalFlowを使用したデータ分析 トピックを参照してください。
サンプル計算を含む、SignalFlowの各分析手法の詳細については、以下のリストを参照してください。
絶対値 🔗
SignalFlowメソッド: abs()
データポイントの絶対値を返します。数値の絶対値とは、その数値から符号を除いたものです。
Ceiling 🔗
SignalFlowメソッド: ceil()
データポイントを、引数以下で数学的整数に等しい最大の(正の無限大に最も近い)浮動小数点数値に切り上げます。
Count 🔗
SignalFlowメソッド: count()
外挿されたデータポイントを含め、値を持つ時系列の数をカウントします。Count は通常、データポイントが何らかの理由で欠損しているかどうかを判断するために使用されます。
以下の例では、Count は、当該の時間間隔内にデータポイントを報告した入力時系列の量を返します。
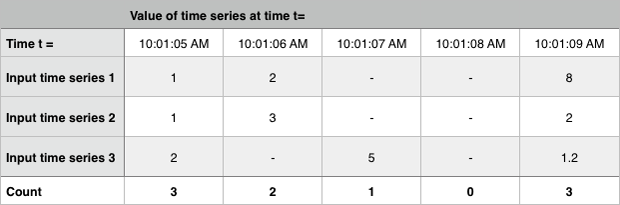
Delta 🔗
SignalFlowメソッド: delta()
各時間間隔における現在値と前回値の差を計算します。Delta は、プロット内の各時系列に対して独立して機能します。
以下の例では、Delta は、各時間間隔における2つの時系列間の差を返します。
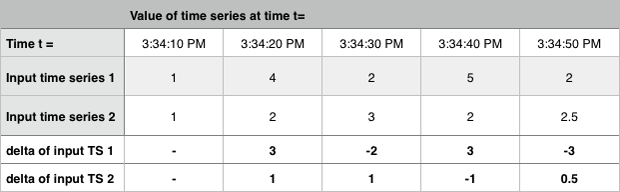
EWMAおよびDouble EWMA 🔗
SignalFlowメソッド: ewma() および double_ewma()
指数加重移動平均(EWMA)を計算します。ここでは、最近のデータポイントほど高い加重が与えられます。データポイントの加重は、時間とともに指数関数的に減少します。
EWMA は、最近受信したポイントに重点を置いてデータのウィンドウを要約します。アラートの閾値は、標準偏差またはパーセンテージを使用して、EWMAを囲んで帯を形成することによって設定できます。また、EWMAに対するアラートは、通常の移動平均に対するアラートと同様に、期間条件の代わ りに使用することもできます。
Double EWMA は、EWMA の選択可能な変種であり、メトリクスのトレンドの加重移動平均を組み込むもので、予測に使用できます。 Double EWMA は、生データがトレンドを示すときに発生する平滑化の問題に対処します。
EWMAおよびDouble EWMAのパラメータ 🔗
EWMA および Double EWMA で以下のパラメーターを使用します。
データ平滑化 (数値)
入力時系列のデータポイントに適用される平滑化パラメータ(αと呼ばれることが多い)。0~1の間である必要があります。値が小さいほど時間窓が長くなり、より平滑化されます(加重の減衰がより遅くなる)。データ平滑化 は、常に利用可能な最も細かい解像度を使用します。
トレンド平滑化 (数値、Double EWMA にのみ適用)
入力時系列のトレンドに適用される平滑化パラメータ(βと呼ばれることが多い)。0~1の間である必要があります。値が小さいほど時間窓が長くなり、より平滑化されます(加重の減衰がより遅くなる)。トレンド平滑化 は、常に利用可能な最も細かい解像度を使用します。
予測 (期間、Double EWMA にのみ適用)
どの程度先の将来まで予測するか(例えば 1hや4mなど)。トレンド項の適切な倍数をレベル項に加算することによって計算されます。デフォルト値(0)は系列を平滑化します。
例えば、予測パラメータが10mに設定されている場合、出力時系列は、現在から10分の入力時系列の値を推定します。これは、リソースが枯渇しそうなタイミングを予測したりアラートを早めに取得したりする方法として使用できます。また予測は、値に問題があるがトレンドには問題がない(健全な状態に戻るように減少している)というシナリオにおいて、一部の誤報を排除します。
Damping (数値、Double EWMA にのみ適用)
0~1までの数値。値が1であれば、トレンドが無限に続く(減衰なし)と予測します。値が小さいほど、予測が将来に向かって進むにつれてトレンドはゼロに向かって減衰します。Damping は、予測 が0でない場合に意味を持ちます。
Exclude 🔗
SignalFlowメソッド: above() 、below() 、between() 、not_between()
指定された閾値以上または以下の値を除外することによって、分析するデータを制限します。閾値自体を含めるかどうかを選択できます。時系列値がメソッドで設定した基準を満たす場合、除外されたポイントをドロップする または 除外された値を対応する制限値に設定する を選択できます。
Exclude は、別の分析メソッドに条件を適用したい場合に便利です。たとえば、CPU使用率が80%を超えるサーバーの数をカウントしたい場合、CPUUtilization をメトリクスとして使用し、Exclude x < 80 を適用して、Count を適用します。
Floor 🔗
SignalFlowメソッド: floor()
データポイントを、引数以上で数学的整数に等しい最小の(負の無限大に最も近い)浮動小数点数値に切り捨てます。
Integrate 🔗
SignalFlowメソッド: integrate()
各入力時系列の値をチャートの解像度(秒)で乗算します。Integrate は、ゲージメトリクスに最も有用です。
次の例では、Integrate は、ある時間窓にわたって速度の変化を計算します。
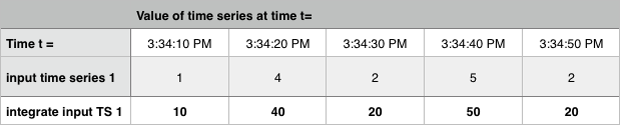
カウンターおよび累積カウンターの場合、同等の機能を持つ内蔵の ロールアップ が既に存在するため、Integrate はあまり有用ではありません。カウンターの場合、Integrate メソッドを レート/秒 (1秒あたりのレート)のロールアップに適用することと Sum ロールアップを使用することは、同じことです。累積カウンターの場合の Delta ロールアップについても同様です。
LNまたはLog natural 🔗
SignalFlowメソッド: log()
LN は各データポイント値の自然対数(loge )を計算します。各入力時系列に対して、 LN は対応する出力時系列を生成します。
Log10 🔗
SignalFlowメソッド: log10()
各データポイントの常用対数(log10 )を計算します。各入力時系列に対して、Log10 は対応する出力時系列を生成します
Mean 🔗
SignalFlowメソッド: mean()
利用可能なデータポイントの値の合計を利用可能なデータポイントの数で割ることによって、利用可能なデータポイントの相加平均(算術平均)を計算します。
Meanのタイプ 🔗
Mean の値を集計するか変換するかを選択できます。
Mean:Aggregation
すべての値の平均。Mean:Aggregation は、入力時系列の各グループの平均時系列を出力します。欠落したデータポイントは
null値として処理されます。次の例は、3つの時系列のグループを平均したものです。
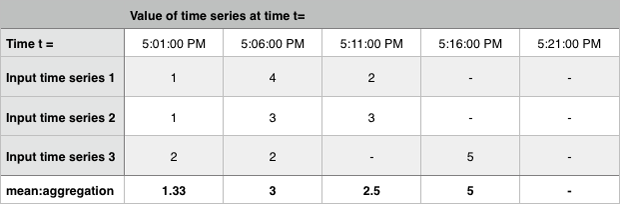
Mean:Transformation
設定可能な時間窓にわたる移動平均を計算します。各入力時系列に対し、Mean:Transformation は、各期間について、その期間までの設定可能な時間窓にわたる入力時系列の値の平均を表す対応する時系列を出力します。デフォルトの時間窓は1時間です。
次の例は、ある10秒間の時間窓で計算された移動平均を示しています。
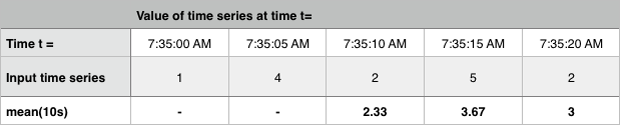
Mean メソッドは、移動ウィンドウの代わりにカレンダーウィンドウ(日、週、月など)やダッシュボードウィンドウでの変換もサポートしています。詳細については、カレンダー・ウィンドウの変換 と ダッシュボード・ウィンドウの変換 を参照してください。
Mean + Standard Deviation 🔗
SignalFlowメソッド: mean_plus_stddev()
μ+n*σの式を適用します。ここにおいて、μは平均、σは標準偏差、nは平均に対して加える(負の数の場合は引く)標準偏差の数の指定です。標準偏差のデフォルト数は1です。集計モードと変換モードは、独立した平均メソッドと標準偏差メソッドについて同じように機能します。
Minimum / Maximum 🔗
ある時点における複数の時系列から収集されたデータポイント(集計)、またはある時間窓にわたる個々の時系列から収集されたデータポイント(変換)で見られる最小値( Minimum )または最大値( Maximum )のいずれかを返します。
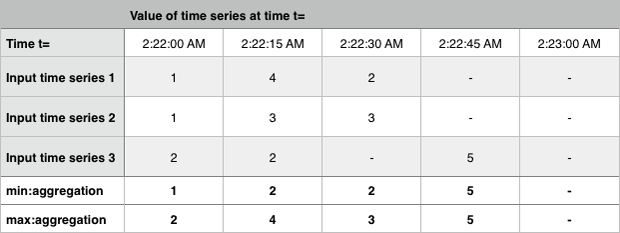
Minimum:Aggregation および Maximum:Aggregation
入力時系列の各グループに対し、各期間について、その期間の入力内に存在する最小値または最大値を表す時系列を1つ出力します。
次の例は、3つの時系列の最小値と最大値の集計を示したものです。
Minimum:Transformation および Maximum:Transformation
各入力時系列に対し、各期間について、その期間までの設定可能な時間窓にわたる入力時系列の値の最小値または最大値を表す対応する時系列を出力します。デフォルトの時間窓は1時間です。
次の例は、ある10秒間の時間窓における最小値と最大値を示しています。

Minimum および Maximum メソッドは、移動ウィンドウの代わりにカレンダーウィンドウ(日、週、月など)やダッシュボードウィンドウでの変換もサポートしています。詳細については、カレンダー・ウィンドウの変換 と ダッシュボード・ウィンドウの変換 を参照してください。
Percentile 🔗
SignalFlowメソッド: percentile()
ある時点の複数の時系列から収集されたデータポイント(集計)、または移動時間窓にわたる個々の時系列から収集されたデータポイント(変換)の値の指定パーセンタイルを見つけます。
Percentile:Aggregation
入力時系列の各グループに対し、各期間について、その期間の入力内に存在する値の指定パーセンタイル(1~100の間で、1と100も含む)を表すデータストリームを1つ出力します。デフォルトのパーセンタイル値は95です。
たとえば、1,000個のMTSのデータストリームにパーセンタイル値95を適用すると、各期間で50番目に大きいMTSの値が得られます。この例では、値の約95%は返されたパーセンタイルより低く、約5%は返されたパーセンタイルより高くなります。
Percentile:Transformation
各入力時系列に対し、各期間について、その期間に至るまでの設定可能な時間窓にわたる入力時系列の指定パーセンタイル(1~100の間で、1と100を含む)を表す対応データストリームを1つ出力します。デフォルトのパーセンタイル値は95、デフォルトの時間窓は1時間です。
例えば、解像度10秒のMTSの過去1時間の95パーセンタイル(ロールアップなしと仮定)を要求すると、過去1時間で18番目に大きい値が返されます。この例では、過去1時間の360のデータポイントのうち、約95%の値は返されたパーセンタイルより低く、約5%の値は返されたパーセンタイルより高くなります。
Percentile メソッドは、移動ウィンドウの代わりにダッシュボードウィンドウでの変換もサポートしています。詳細については、ダッシュボード・ウィンドウの変換 を参照してください。
Power 🔗
SignalFlowメソッド: pow()
各データポイントの値を指定した数で累乗、または指定した数値をデータポイント値で累乗します。
変化率 🔗
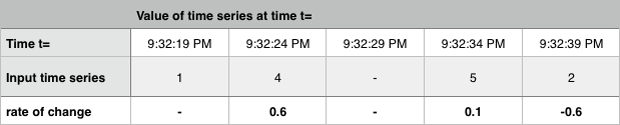
SignalFlowメソッド: rateofchange()
各時間間隔について現在値と前回値の差を計算し、その結果を当該の時間間隔の長さ(秒)で割ります。
Delta と似ていますが、計算解像度の変化を正規化するためにその差を経過時間(秒)で割る点が異なります。
次の例は、ある時系列の経時的な変化率を示しています。
Scale 🔗
SignalFlowメソッド: scale()
各データポイントに指定した数値を掛けます。
Scale は、値をパーセンテージに変換したり(100を使用、時間の単位を変換したり(60を使用)するときによく使用されます。デフォルトのスケールファクターは1です。
平方根 🔗
SignalFlowメソッド: sqrt()
データポイントの値の平方根を計算します。
標準偏差 🔗
SignalFlowメソッド: stddev()
標準偏差(σ)は分散の平方根です。集計と変換の両モードの分散の計算方法については、分散 を参照してください。
Sum 🔗
SignalFlowメソッド: sum()
ある時点の複数の時系列から収集されたデータポイント(集計)、またはある時間窓にわたる個々の時系列から収集されたデータポイント(変換)のすべての値を合計します。
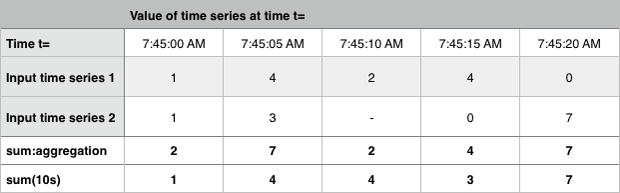
Sum:Aggregation
各期間について、その同じ期間の入力時系列のすべての値の合計を表す単一の時系列を出力します。
そうでない場合は、グループ化プロパティの値の一意の組み合わせごとに1つの時系列を出力します。これらの時系列はそれぞれ、メタデータがそれらのグループと一致する入力時系列の値の合計を表します。これらのグルー化プロパティに一致するディメンションまたはプロパティを持たない入力時系列は、 計算にも出力にも含まれません。
Sum:Transformation
移動時間窓にわたる入力時系列の値の合計を計算します。他の変換と同様に、各入力時系列に対して出力時系列が生成されます。デフォルトの時間窓は1時間です。
以下の例では、集計と10秒間の時間窓における変換の両方を示しています。
Sum メソッドは、移動ウィンドウの代わりにカレンダーウィンドウ(日、週、月など)やダッシュボードウィンドウでの変換もサポートしています。詳細については、カレンダー・ウィンドウの変換 と ダッシュボード・ウィンドウの変換 を参照してください。
Timeshift 🔗
SignalFlowメソッド: timeshift()
過去のある時点のデータを、指定した期間(例えば1週間)でオフセットして取得し、時系列とその時系列の過去のトレンドとの比較を可能にします。
プロット内に Timeshift 要素が存在すると、その位置に関係なく、それが存在するプロット全体に影響します。これは、Timeshift要素がSignalFlowに対して、指定された時間オフセットでプロットのすべての時系列のデータをフェッチするように指示するためです。
例えば、タイムシフトが1日の場合、1日前からの時系列データを取得し、オフセットしたデータをリアルタイムでストリーミングします。これにより、ある時系列で報告される現在の値と、過去に報告された値を、一定した相対オフセットで比較することができます。
オフセット値は、週(w)、日(d)、時間(h)、分(m)、秒(s)で指定できます。オフセット値は常に過去に向かうものと想定され、ゼロまたは正の値でなければなりません。2週間と2時間のオフセットを指定する場合は、オフセット値を2w2hと入力します。
注釈
オフセット値は、現在のチャートで使用されているデータの最小解像度以上でなければなりません。例えば、タイムシフトを30秒に設定しても、チャートの解像度が5分であれば、このメソッドは無効になります。
TopおよびBottom 🔗
SignalFlowメソッド: top() 、bottom()
プロット内の時系列のサブセットを選択するために使用できます。
カウントで演算
カウントで演算する場合、出力結果は、各期間の最高値または最低値の上位N個または下位N個の時系列になります。ここでNは指定したカウント値です。デフォルトのカウント値は5です。
パーセントで演算
パーセントで演算する場合、出力結果は、各期間の値がPパーセンタイルより高い、または低い時系列になります。ここでPは指定したパーセンテージ値です(1%~100%で、1と100も含む)。これは、時系列の値別の 上位x% または 下位x% と同等です。デフォルトのパーセント値は5です。
Top または Bottom を使用した折れ線グラフには、指定した時間窓の任意の時点において上位/下位Nにあったすべての時系列が表示されます。ある時系列が上位/下位Nにない場合、その時系列の値はタイムスタンプで null に置き換えられます。
分散 🔗
SignalFlowメソッド: variance()
分散は、値の集合がどの程度広がっているかを測定します。分散 は、各値の平均値との差の2乗和を、利用可能なデータポイントの数で割ることによって計算されます。
Variance:Aggregation
指定した時点における入力時系列のグループ全体の値の分散を計算します。
Variance:Transformation
移動時間窓にわたる入力時系列の値の分散を計算します。他の変換と同様に、各入力時系列に対して出力時系列が生成されます。デフォルトの時間窓は1時間です。