チャートの分析によってインサイトを取得する 🔗
Splunk Infrastructure Monitoringの分析を使用すると、生のメトリクスデータを表示するチャートを、パターンや傾向をより深く把握するための強力なツールに変えることができるため、インフラストラクチャ、アプリケーション、またはサービスの健全性をより効果的に監視できます。このセクションでは、以下を実行する方法を説明します:
グループ化を使って 集計レベルでサービス別の使用率を比較する
同じチャート上で表示することにより 複数のメトリクスを関連付ける
時間、日、週、その他の履歴的パターンと 現在値を比較する
時系列式を使って パーセンテージまたは比率を見る
単純な外れ値や順位を見つけるために、Top NまたはBottom Nのリストを表示する
ヒストグラムを使用して、分布の変化を見る
一時的な山や谷に注目するのではなく、一般的なパターンを見るためにデータを 平滑化する
このセクションでは、あなたが以下のトピックに精通していることを前提としています。
サービスやその他のメタデータ別で集計を比較する 🔗
ホスト、仮想マシン、コンテナなど、それなりの規模のインフラストラクチャメトリクスを見る場合、ほとんどのケースにおいて、個々のインスタンスを見るよりも、集計レベルで見て集計を比較した方が有益です。多くの分析関数では、メタデータ別で出力をグループ化することができます。メタデータ別のグループ化は、この目的に完璧に役立ちます。
集計レベル(サービス全体など)で比較したいメトリクスを選択し、プロットAの「シグナル」フィールドにその名前を入力します。この例では、
demo.trans.latencyをプロットしています。
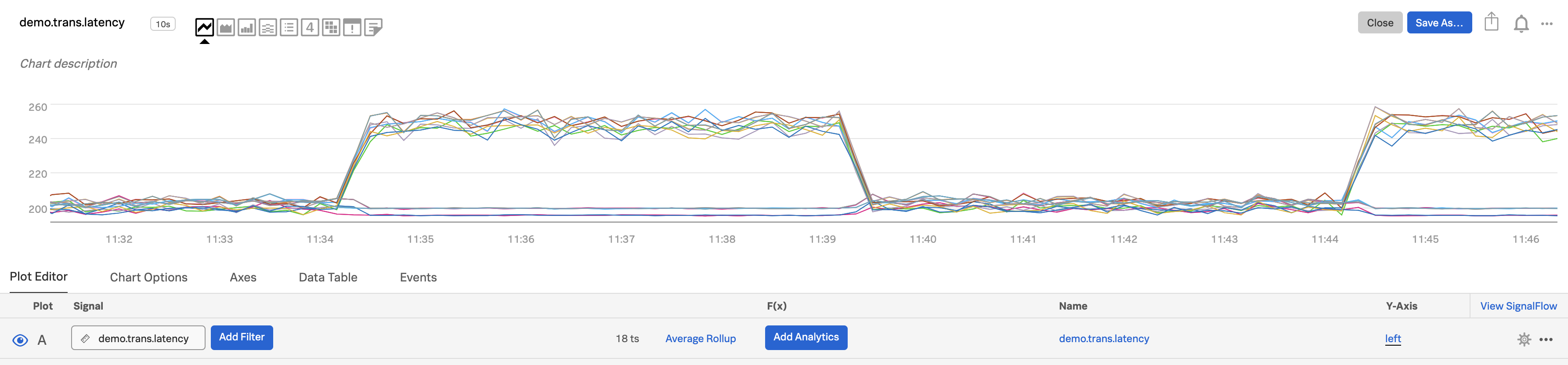
「分析」フィールドで、
mean:aggregationのように、適用したい関数を選択します。これでチャートには、各時間間隔のすべての時系列にわたる集計の平均値を表示する単一のプロット線が表示されます。
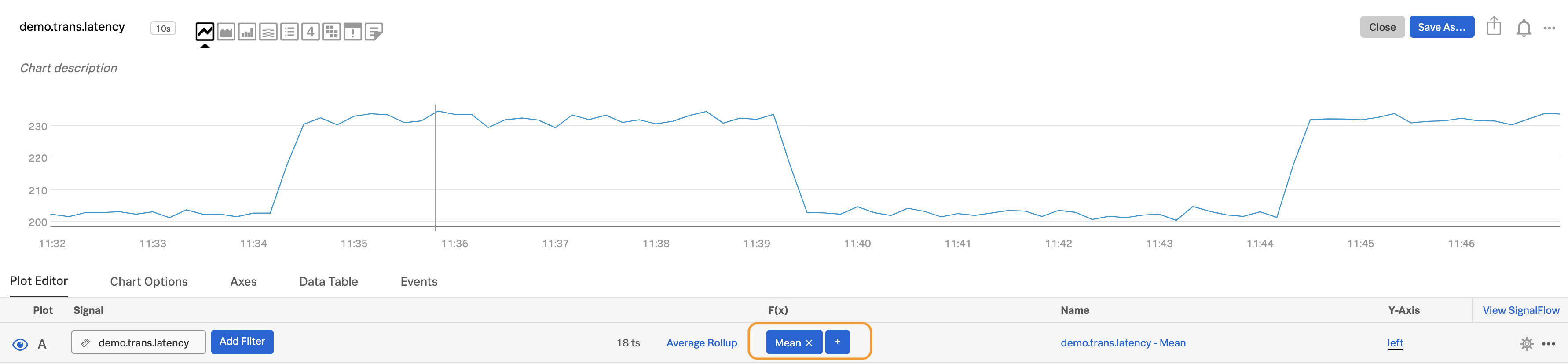
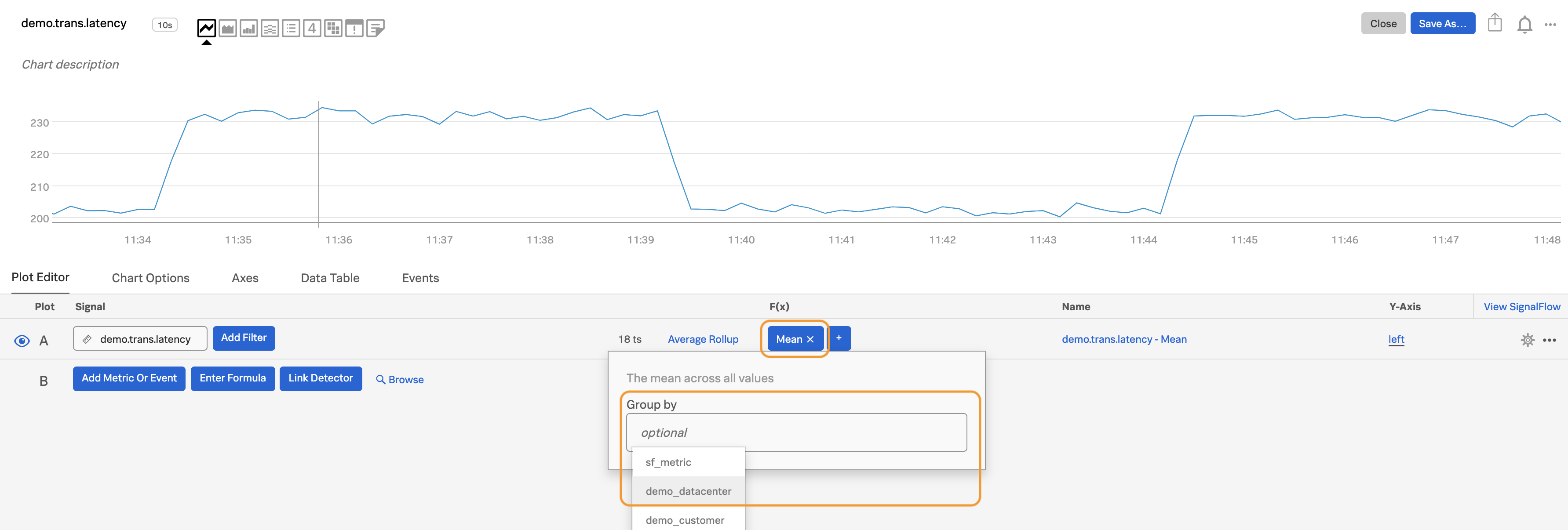
プロットに対して選択した関数をクリックします。「グループ化(group-by)」ドロップダウンをクリックします。「サービス」(「サービス」という名前のディメンションで送信している場合)や、「aws_availability_zone」 (AWSを使用している場合)、またはその他のメタデータなど、グループ化したいメタデータを選択します。この例では、
demo_datacenterを選択します。
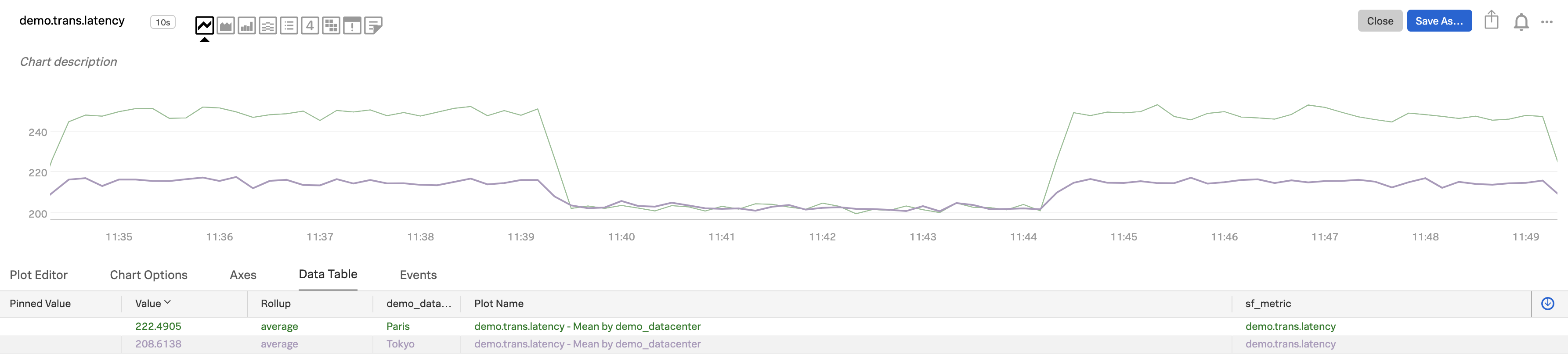
これで、各サブグループの全リソース(ホスト/vm/コンテナ)にわたって集計されたメトリクスを見ることができます。データテーブルが示すように、各プロット線は2つの
demo_datacentersのうちの1つを表しています。
より長い時間範囲で山と谷を保持する 🔗
デフォルトでは、Splunk Infrastructure Monitoringは、ユーザーが選択した時間範囲および rollup に適した chart resolution を選択します。たとえば、Infrastructure Monitoringに10秒ごとにメトリクスを送信していて、そのメトリクスタイプがゲージであるとします。そのメトリクスの1ヶ月分をチャートで見る場合、データポイントが多すぎて表示できません(1分あたり6データポイント×1時間あたり60分×1日あたり24時間×1ヶ月あたり30日=259,200データポイント)。
このような場合、Infrastructure Monitoringはゲージメトリクスの「Average」というデフォルトの視覚エフェクトのロールアップを適用します。このロールアップには、データを平均化する効果があり、高い解像度で表示される山や谷を目立たなくさせます。
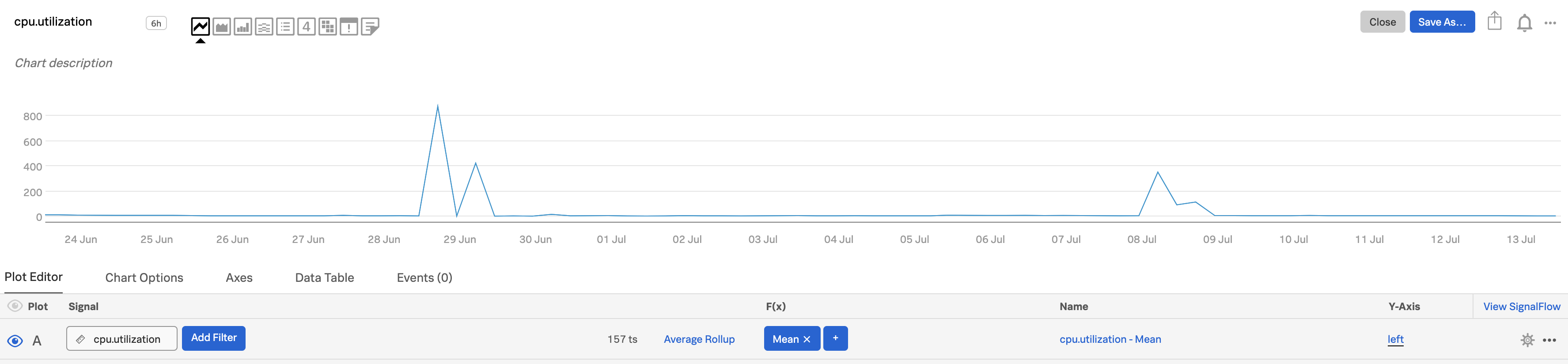
山または谷を保持するには、このロールアップを、 max または min のいずれか(自分のメトリクスとの関連性がより高い方)に変更します。Y軸の値の範囲は、元の視覚エフェクトでの値範囲から変わる場合があります。このイラストでは、プロットAを複製し、プロットBのロールアップを max に変更しています(そして、プロットBの色を変更して、違いを見やすくしています)。プロット線を複製するには、プロット線の右端にあるプロットの「アクション」メニュー(⋯ )を開いて、複製 を選択します。プロットの色の変更については、プロット設定パネルでオプションを設定する を参照してください。
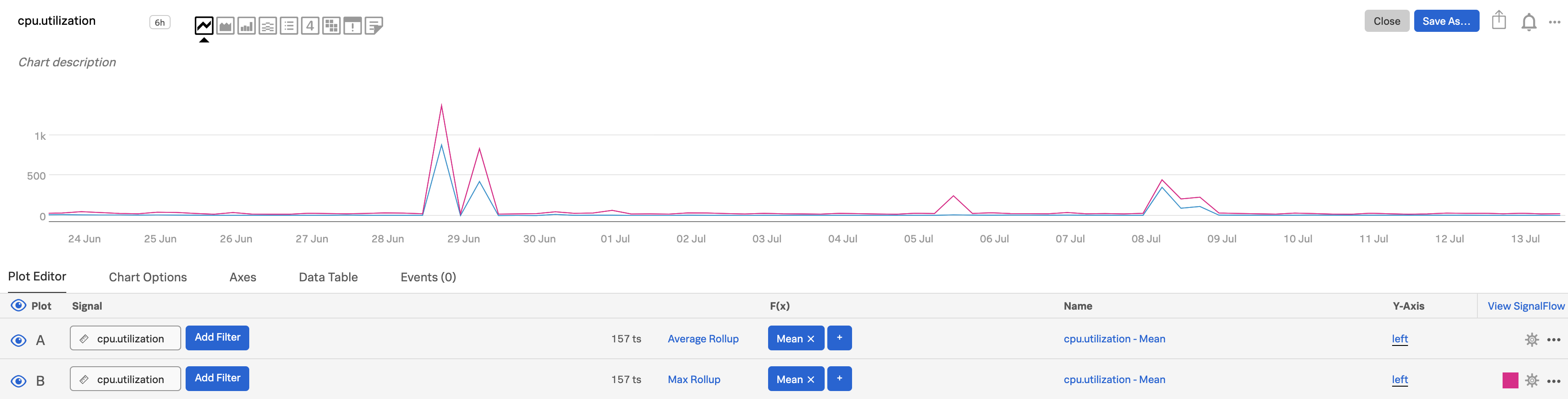
山と谷をさらに目立たせるためには、increase the chart display resolution。ここでは、デフォルトから「Very High(超高解像度)」に変更しています。違いがより分かりやすくなります。
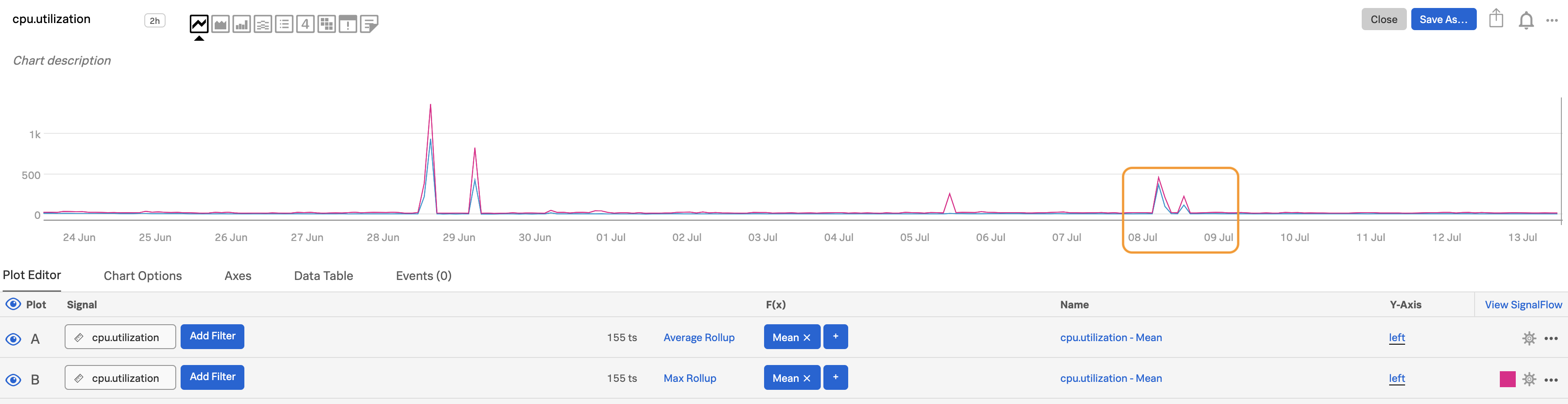
より短い時間フレームを選択することも、視認性を高めます。ここでは、時間範囲を過去20日間から過去1週間に変更しています。
ロールアップ、チャート解像度、および分析の相互作用の詳細については、チャートのデータ解像度とロールアップ を参照してください。
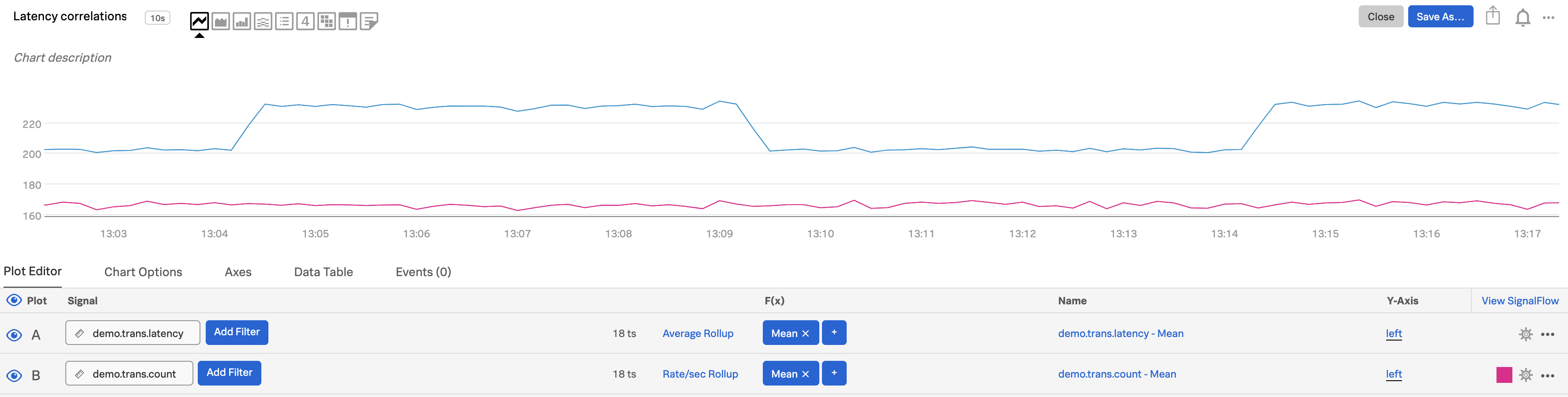
複数のメトリクスを関連付ける 🔗
複数のメトリクスの動作をより簡単に相関付けるには、それらを同じチャート上に可視化すると便利な場合が多いです。例えば、1秒間に発生したトランザクションの数とトランザクションのレイテンシを同時に見たい場合があるでしょう。Splunk Infrastructure Monitoringでは、1つのチャートに必要な数のメトリクスを表示でき、また、メトリクスの値の範囲が大きく異なる場合に備えて2つのY軸を利用できるようになっています。
比較したいメトリクスを選択し、プロットAの「シグナル」フィールドにその名前を入力します。この例では、
demo.trans.latencyを使用しています。2番目のメトリクスを選択し、プロットBで使用します。ここでは
demo.trans.countを選択しました。
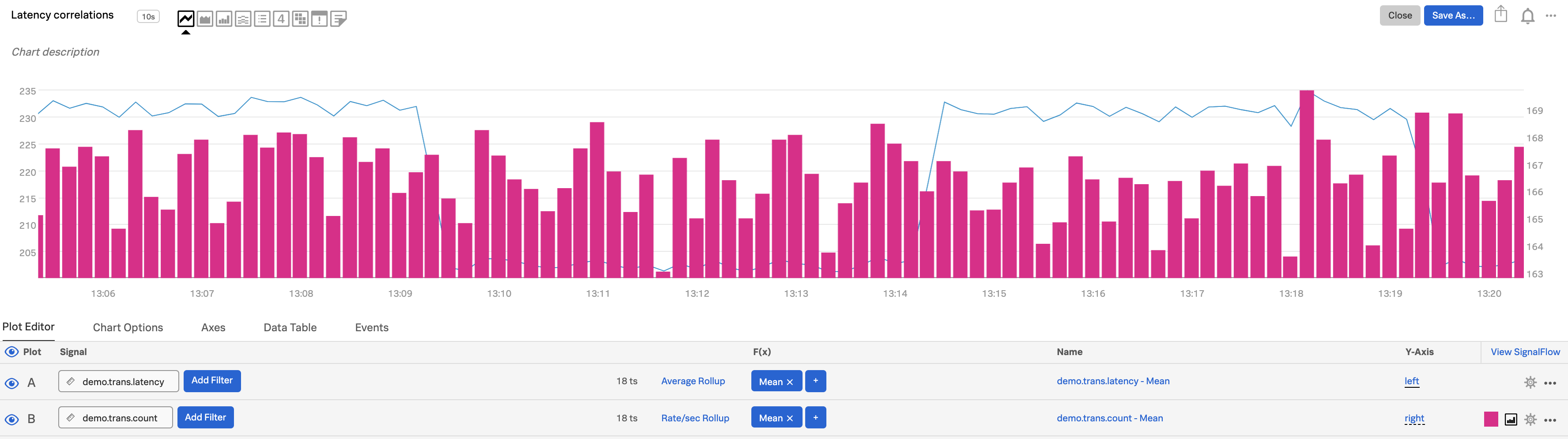
プロットBで、Y-Axis をクリックし、右 を選択します。詳細は、左右のY軸 を参照してください。

各プロット線の視覚エフェクトタイプオプションを使用して、AとBに異なるタイプを選択します(例:Aは線グラフ、Bはカラムチャートなど)。詳細は、視覚エフェクトのタイプ を参照してください。この例では、プロット設定オプションを使ってプロット線Bの色も変更し、可視性を高めています。詳しくは、プロットの色 を参照してください。
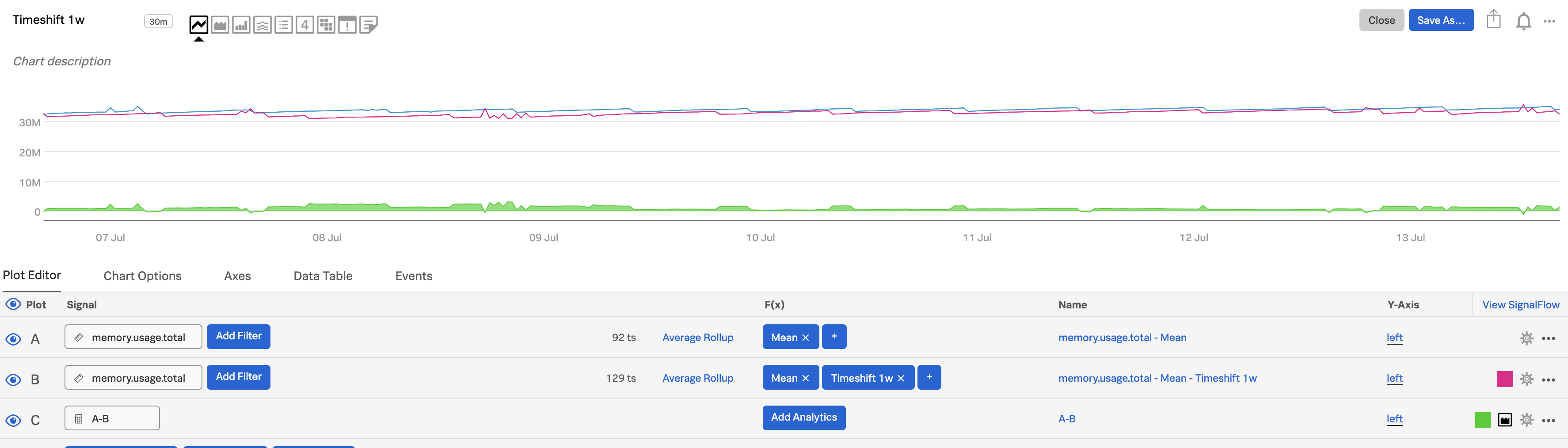
週単位、日単位、時間単位での比較を表示する 🔗
アプリやインフラストラクチャが正常な範囲内で動作しているかどうかを把握するために時刻や週が重要になる場合、またはビジネスで周期的または定期的な需要が発生する場合(平日と週末が大きく異なる場合など)には、1週間、1日、1時間などの変化を強調するチャートを作成できます。(Splunk Infrastructure Monitoringでは、これらの時間間隔だけでなく、任意の時間フレームを使用して比較を行うことができることを覚えておいてください。)
最初のプロット(プロットA)を使って気になるメトリクスを表示し、次にAを複製してプロットBを作成します。(プロット線を複製するには、プロット線の右端にあるプロットのアクションメニュー(⋯ )を開き、複製 を選択します。)この例では、
memory.usage.totalをシグナルとして使用しています。プロットBに Timeshift 関数を追加し、変化が問題となる時間範囲を入力します。例えば、5分間なら
5m、2日間なら2d、1週間なら1wを使用します。
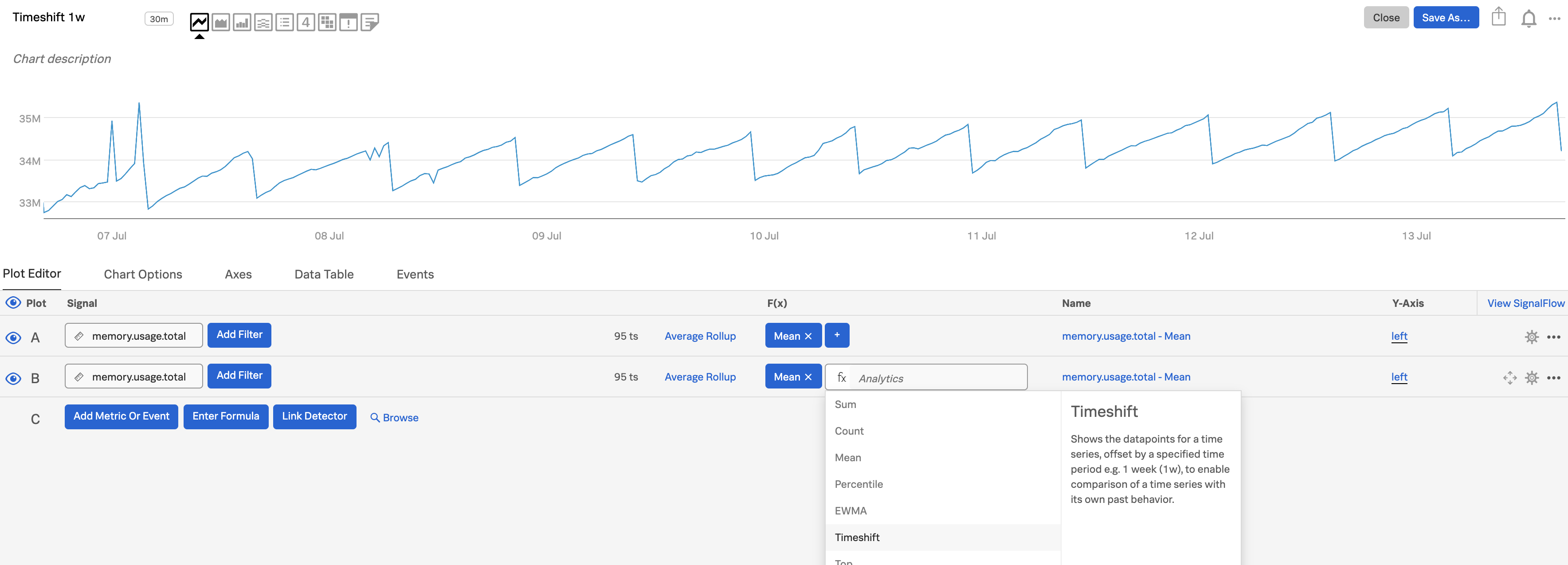
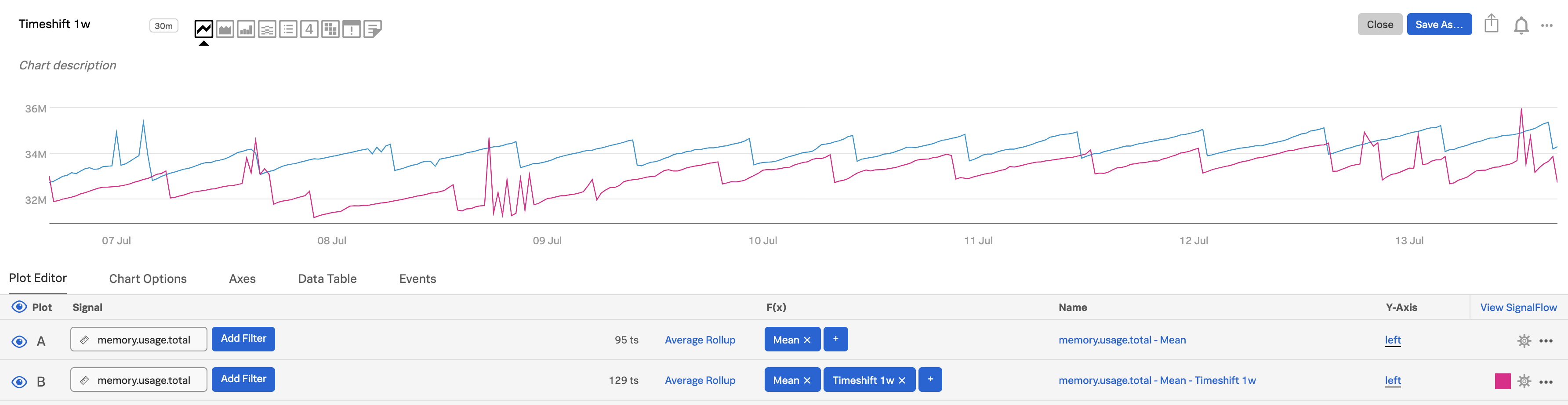
プロットCで、式の入力 をクリックして、
A-Bと入力し、現在と1週間前の差を見ます。プロット設定パネルを使用して、プロットCに面グラフの視覚エフェクトを指定します。詳細は プロット設定パネルでオプションを設定する を参照してください。
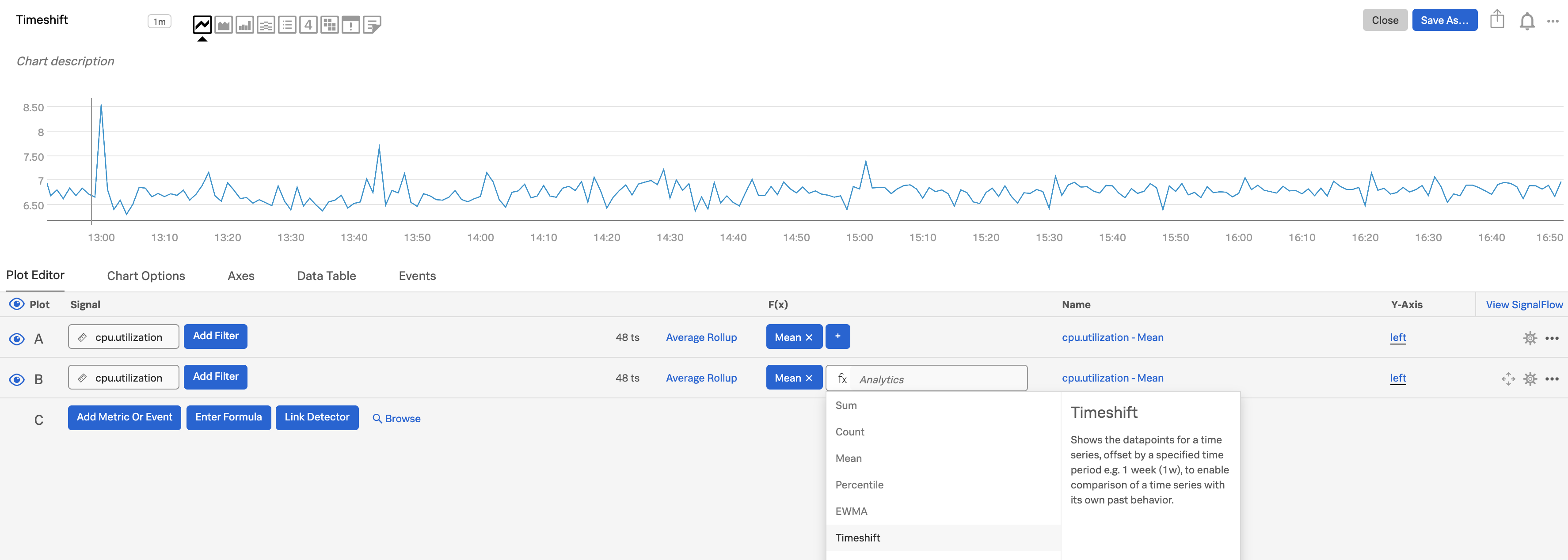
Timeshift関数を使って傾向を把握する 🔗
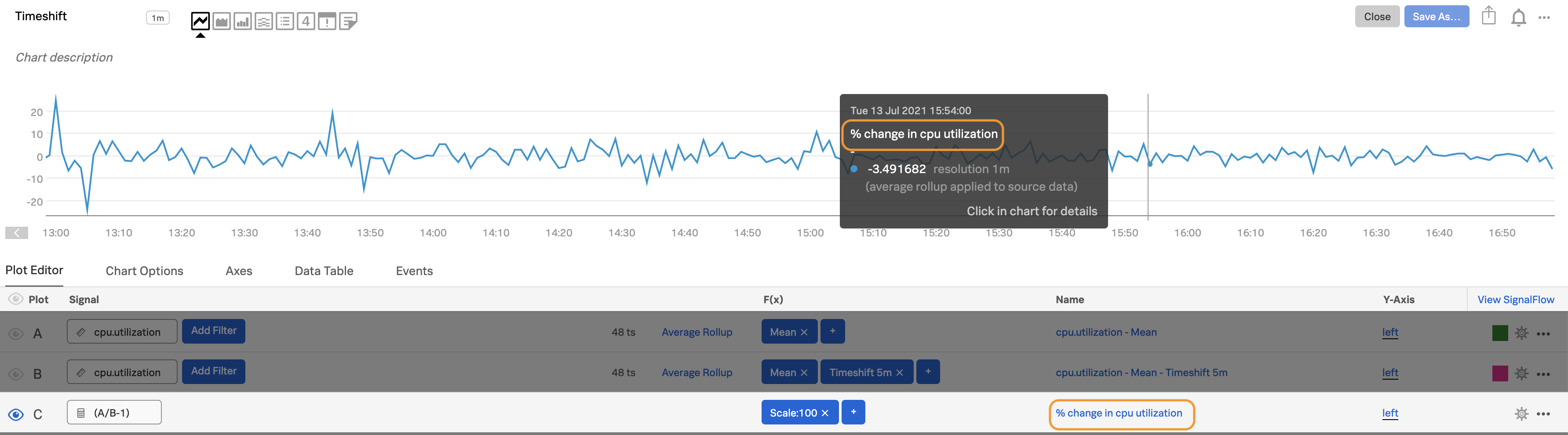
インフラストラクチャやアプリケーションの監視においては、メトリクスの絶対値そのものよりも、メトリクスの傾向(メトリクスが変化している割合)の方が大きな関心対象である場合がよくあります。例えば、CPUの使用率が70%であることを知ることは意味がないかもしれませんが、使用率が過去10分間に一貫して2倍になっていることを知ることは重要かもしれません。これはシステムが故障に向かっていることを示す可能性があるからです。
最初のプロット(プロットA)を使って気になるメトリクスを表示し(ここでは
cpu.utilizationの平均を使用)、次にAを複製してプロットBを作成します。(プロット線を複製するには、プロット線の右端にあるプロットのアクションメニュー(⋯ )を開き、複製 を選択します。)プロットBに Timeshift 関数を追加し、変化が問題となる時間範囲を入力します。例えば、5分間なら
5mです。
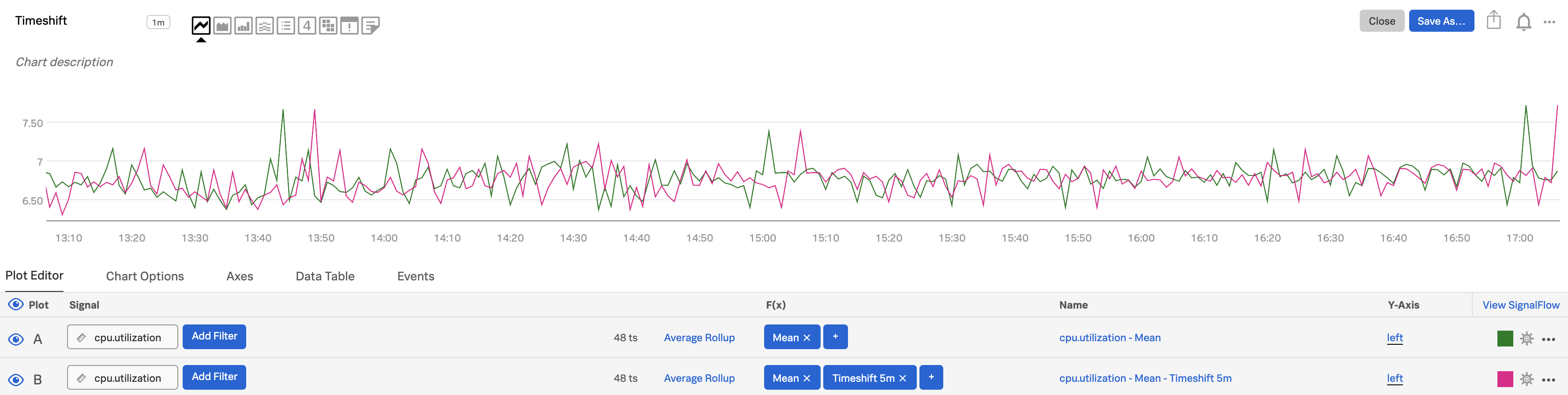
プロットCで、
(A/B-1)という式を入力し、scale:100の関数を追加して、変化率をパーセンテージで表します。プロットCの横にある目のアイコンをAltクリックまたはoptionクリックすると、そのプロットのみが表示され、5分前からのディスク使用率の変化率が表示されます。
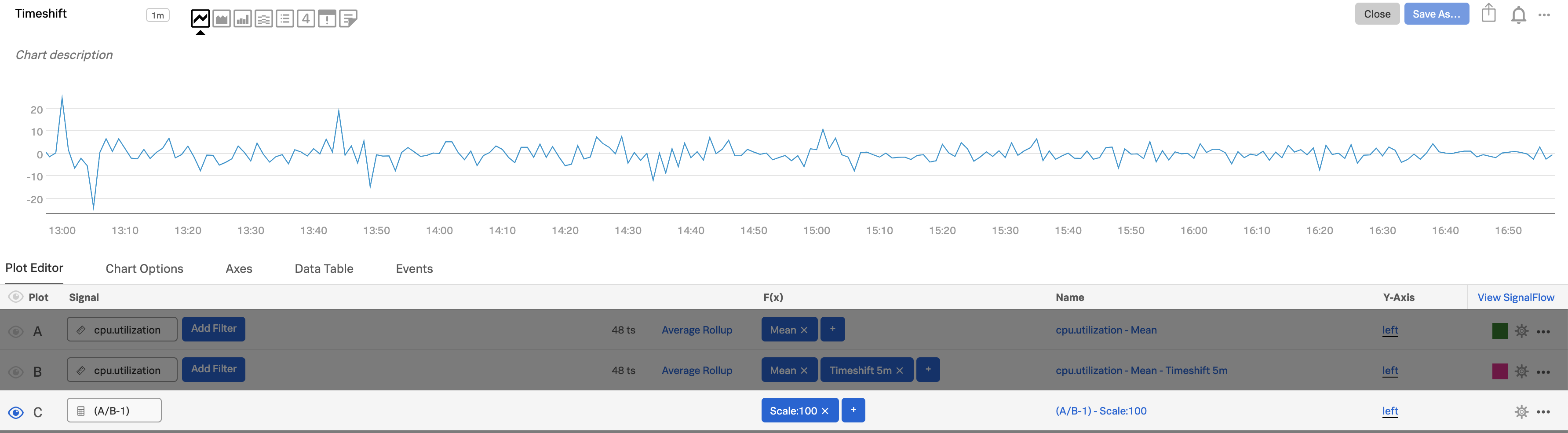
プロットCのプロット名を編集し、チャートの上にカーソルを置いたり、データテーブルを表示したときに、有用な情報が表示されるようにします。
パーセンテージまたは比率を使用する 🔗
生のメトリクスではなく、パーセンテージや比率を見たい場合も多くあるでしょう。例えば、失敗を示すリターンコードと成功を示すリターンコードの比率や、総キャッシュアクセス数(ヒット数+ミス数)に占めるキャッシュヒット数の比率などです。
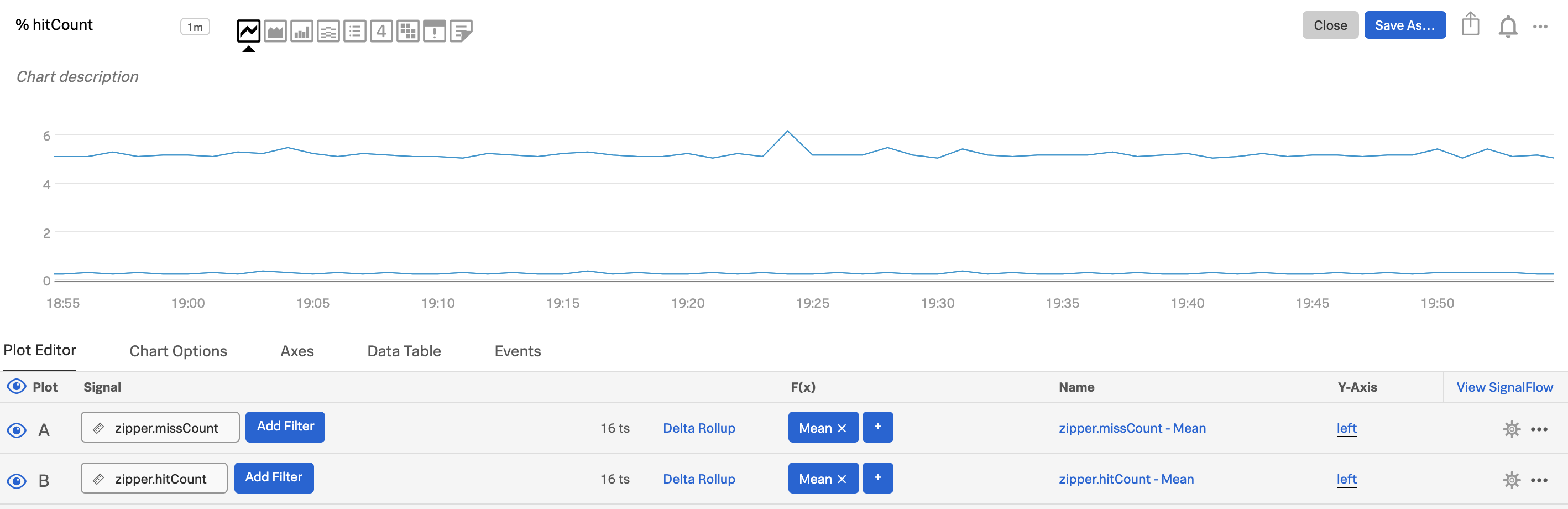
最初のプロット(プロットA)を使って、気になるメトリクスの1つを表示します。例えば、
zipper.missCountです。2つ目のプロット(プロットB)を使って、必要な他のメトリクスを表示します。例えば、
zipper.hitCountです。
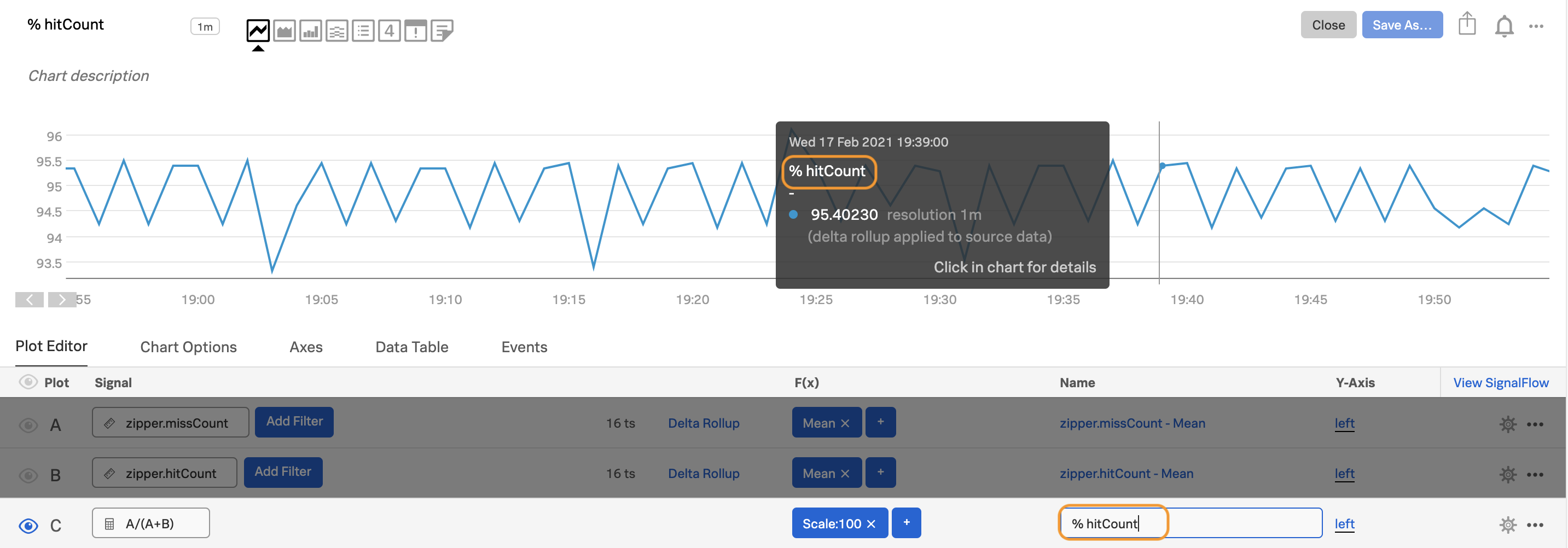
プロットCで、
A/(A+B)という式を入力し、scale:100の関数を追加して、比率をパーセンテージで表します。

他のプロットを非表示にするには、プロットCの隣にある目のアイコンをAltクリックまたはoptionクリックします。時間の経過に伴うミスヒットの割合を示すチャートが残ります。

プロットCのプロット名を編集し、チャートにカーソルを置いたとき(前後は下の図に表示)、またはデータテーブルを表示したときに、有用な情報が表示されるようにします。
パーセンタイルを使用して母集団の概要を見る 🔗
母集団の概要をすばやく知りたいときは、分布パーセンタイルチャートが適したオプションです。このようなチャートを作るには、積み上げを行わない面グラフを使用します。チャートオプション ` タブで :guilabel:`Show on-chart legend を選択し( チャート上に凡例を表示 を参照)、以下のようなプロットを表示します。
p10。最初のプロット(プロットA)で、必要なメトリクスとフィルターを入力し、Percentile 関数を使用して、値として
10を入力します。中央値。プロットAを複製し、値として
50を使用します。p90。プロットBを複製し、値として
90を使用します。
下のイラストは、このチャートがどのような外観になるかを示しています:
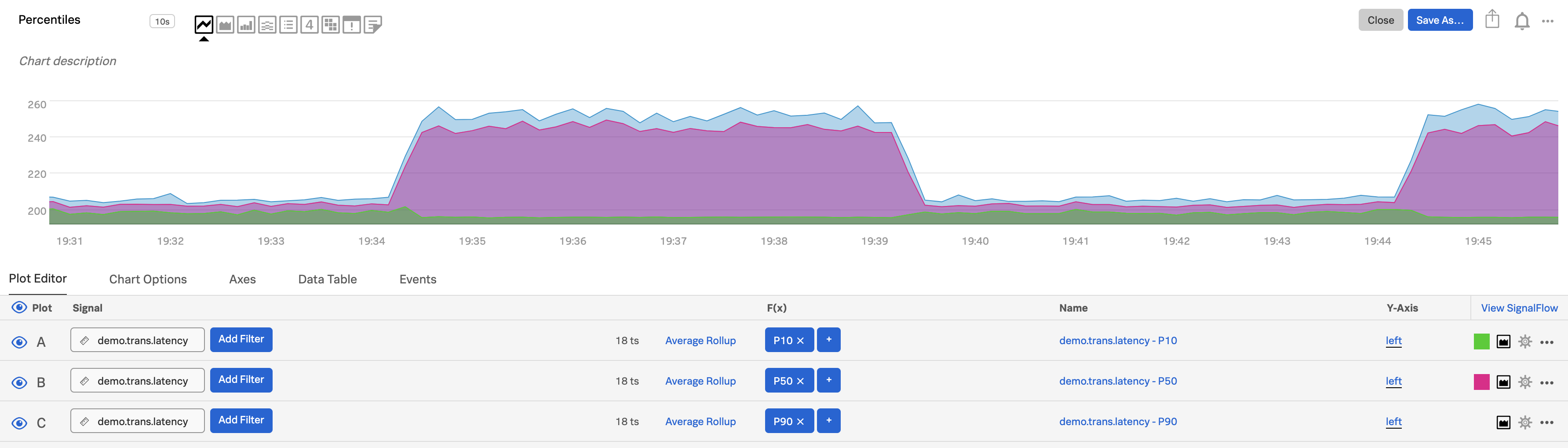
特定の値を見るには、チャート上のさまざまなポイントにカーソルを合わせるか、データテーブルを表示します。
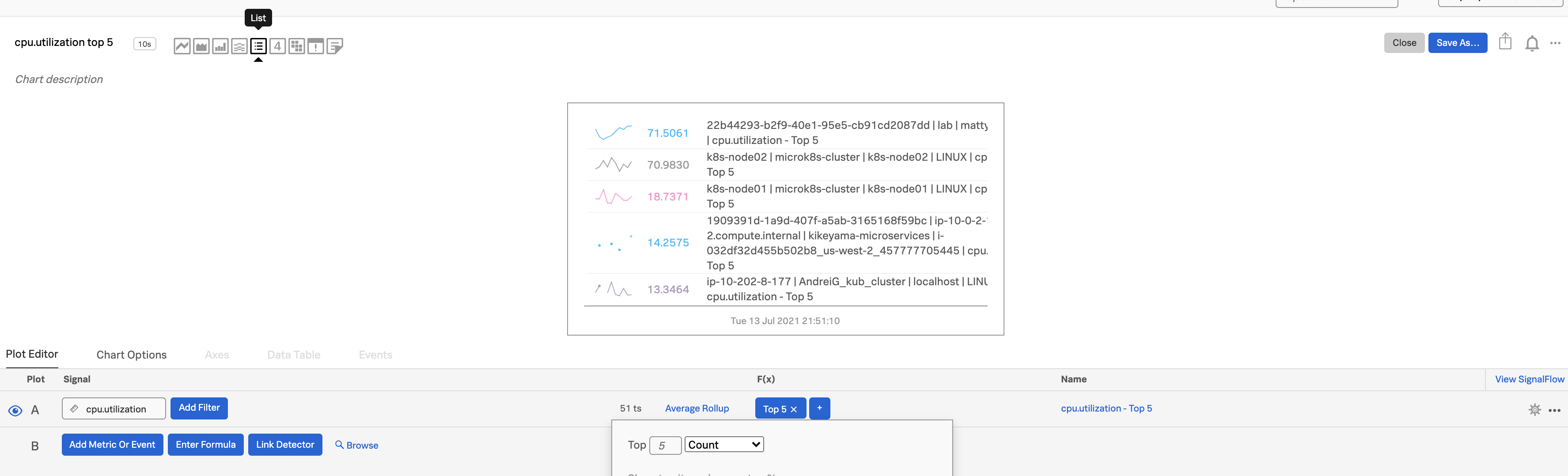
Top NまたはBottom Nのリストを表示する 🔗
Top or bottom N charts は、単純な外れ値や順位、ワーストパフォーマーを表示するのに適しています。
プロットAのメトリクスを入力します。ここでは
cpu.utilizationを選択しています。チャートタイプとして List を選択します。
「Top」または「Bottom」の分析関数を適用し、リストに表示したい値の数または表示したいパーセンテージの範囲を選択します。この例では、
Top 5を選択し、Count を指定しています。
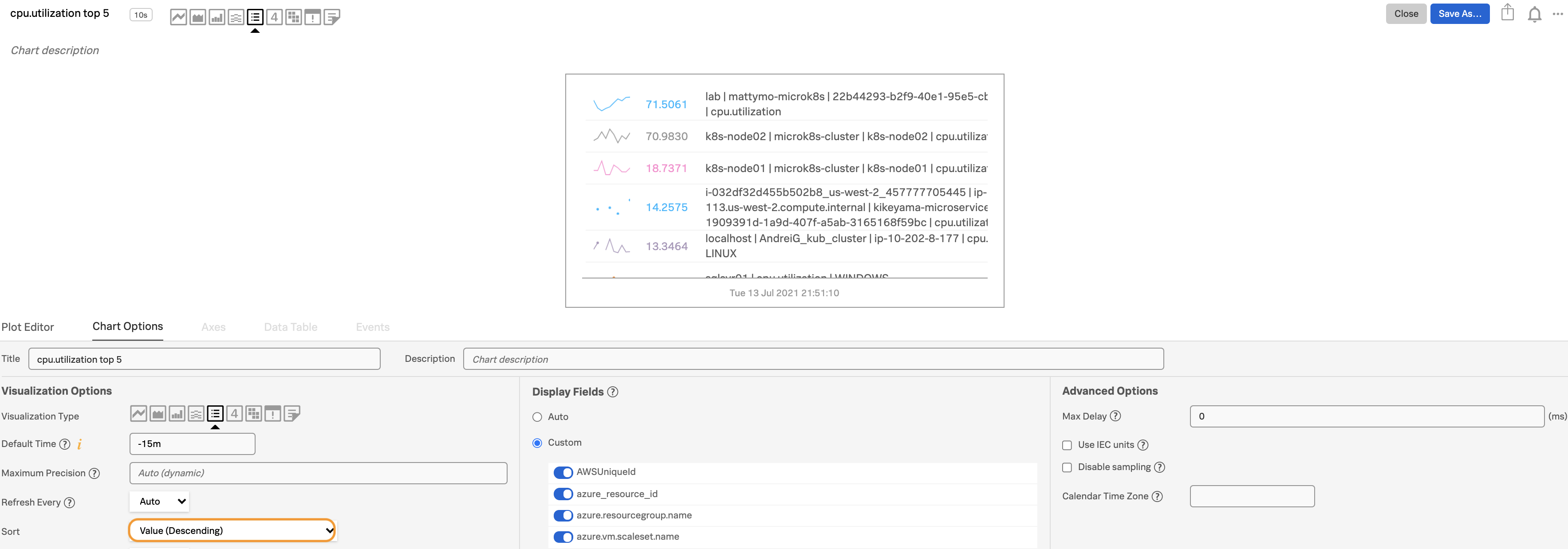
チャート上の冗長なメタデータを減らすには、チャートオプション タブの :strong:` 表示フィールド` オプションで
customを選択し、プロット名を非表示にします。Top Nチャートを値の
Descendingで、または、Bottom Nチャートを値のAscendingで :strong:` ソート` します。
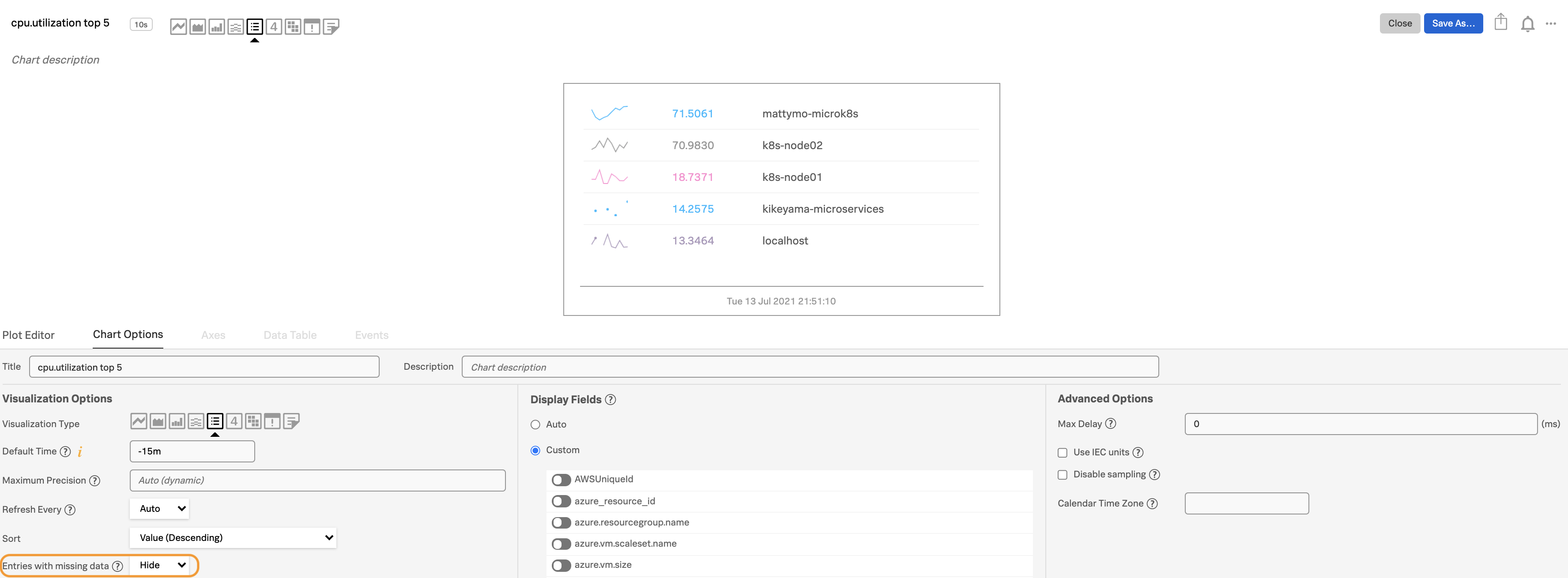
チャートをさらに読み取りやすくするには、表示フィールド オプションを使用して、より多くのフィールドを非表示にします。また、視覚エフェクトオプション の下で、データが欠落しているエントリ を非表示にすることもできます。
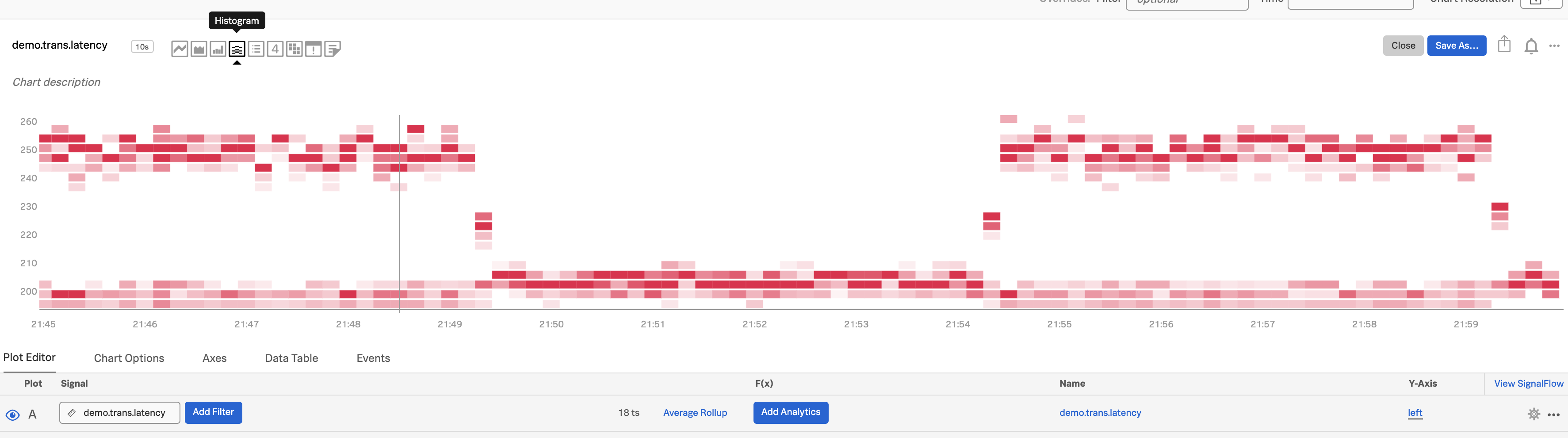
分布の変化を見る 🔗
ヒストグラムは、ある時点における母集団の分布を見るのに適した方法です。Splunk Infrastructure Monitoringはヒストグラムを提供しているため、その分布の経時変化を見ることができます。これは、クラスターが処理するリクエストのレイテンシなど、予期せぬ変化を表面化させるために役立ちます。
比較的多くのソースから送信されているメトリクスを選択します。ここでは、
demo.trans.latencyを選択しています。
ヒストグラムのチャートタイプを選択します。
山と谷を平滑化する 🔗
データの山や谷を滑らかにして、ある期間から次の期間への一般的なパターンを表示する必要がありますか?ある値が概ね安定しているのか、上昇しているのか、下降しているのかが一目でわからない場合、ある期間から次の期間への移動平均形式で正規化されたデータを見たいと思うでしょう。これを行うには、「Aggregation(集計)」の代わりに「Transformation(変換)」オプションを使用します。「Transformation」オプションは、Mean、 Minimum / Maximum、Percentile、Sum、分散 の分析関数で使用できます。Mean、Minimum、Maximum、Sumでは、移動ウィンドウ(過去何分、過去何時間など)またはカレンダー時間ウィンドウ(過去1日、過去1週間、過去1ヶ月など)のいずれかを指定できます。
移動平均を適用するのに適切な間隔を決定します。
Mean分析関数を使用し、Mean:Transformationオプションを選択して、適切な時間窓オプションを選択します。間隔を入力します(例:5m)。
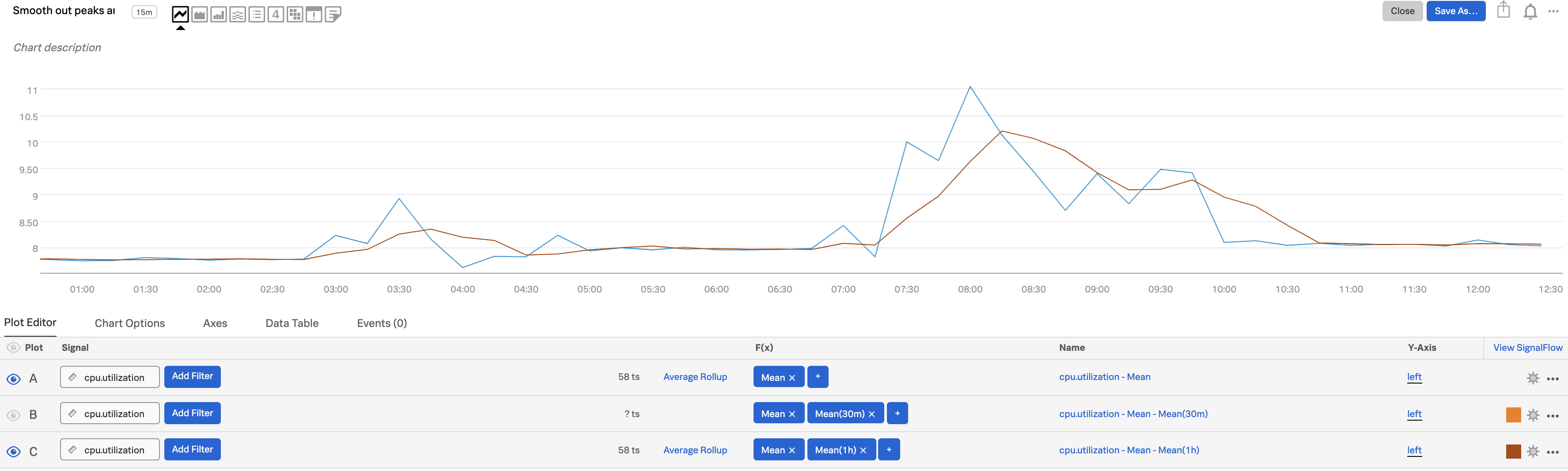
下の図では、「cpu.utilization」の値と移動平均が以下のように表示されています:
プロットA:実際の値
プロットB:30分間の移動平均
プロットC:1時間の移動平均

プロット線を非表示にしてチャートを見やすくすることもできます:
次のステップ 🔗
利用可能なすべての分析関数の詳細については、Splunk Observability Cloudの分析リファレンス を参照してください。
システムを積極的に監視するのに役立つチャートを作成したら、次のステップとして、値が特定の基準に達したときにアラートを表示したり受信したりしたいと思うのは自然なことです。この方法については、Splunk Observability Cloudのアラートとディテクターの概要 を参照してください。