Windowsパフォーマンス・カウンターレシーバー 🔗
Windows Performance Countersレシーバーを使用すると、Splunk Distribution of OpenTelemetry Collectorで、設定されたシステム、アプリケーション、またはカスタムのパフォーマンスカウンターデータをWindowsレジストリから収集できます。サポートされているパイプラインタイプは metrics です。詳細は パイプラインでデータを処理する を参照してください。
注釈
Windowsパフォーマンス・カウンター・レシーバーはWindowsホストでのみ動作します。
Windowsパフォーマンスカウンターレシーバーは、SmartAgentモニター Windowsパフォーマンスカウンター(非推奨) を置き換えます。これは、Telegraf Windows Performance Counters Input Plugin をベースとし、PDHインターフェイス を使用します。
はじめに 🔗
以下の手順に従って、コンポーネントの設定とアクティベーションを行ってください:
インストーラ・スクリプトを使用して Collector for Windows をインストールします。 での説明に従って、Splunk Distribution of the OpenTelemetry CollectorをWindowsホストプラットフォームにデプロイします。
次のセクションで説明するように、Windowsパフォーマンス・カウンター・レシーバーを設定します。
Collector を再起動します。
サンプル構成 🔗
Windows Performance Counters レシーバーをアクティブにするには、Collector 構成ファイルの receivers セクションに windowsperfcounters エントリーを追加します。例:
receivers:
windowsperfcounters:
metrics:
bytes.committed:
description: the number of bytes committed to memory
unit: By
gauge:
collection_interval: 30s
perfcounters:
- object: Memory
counters:
- name: Committed Bytes
metric: bytes.committed
設定を完了するには、設定ファイルの service セクションの metrics パイプラインに、レシーバーを含めます:
service:
pipelines:
metrics:
receivers:
- windowsperfcounters
Windows パフォーマンス・カウンターからメトリクスを収集するには、例のように metrics フィールドを使用してメトリクスを定義する必要があります。その後、counters.metric フィールドから定義したメトリクスを参照できます。
利用可能なパフォーマンス・カウンターを見る 🔗
利用可能なパフォーマンス・カウンターのリストを見るには、Windows PowerShellまたはWindowsパフォーマンスモニターを使用します。
PowerShellで以下のコマンドを実行し、すべてのパフォーマンス・カウンターセットをリストします:
Get-Counter -ListSet *
各パフォーマンス・カウンターセットのインスタンスを一覧表示するには、以下のコマンドを実行し、<perf_object_name> を検索したいインスタンス名に置き換えます:
Get-Counter -List "<perf_object_name>"
以下のコマンドを実行して、Windowsパフォーマンスモニターを開く:
perfmon /sys
Windowsパフォーマンスモニターで、緑のプラス矢印を選択すると、利用可能なパフォーマンス・カウンターのリストが表示されます。
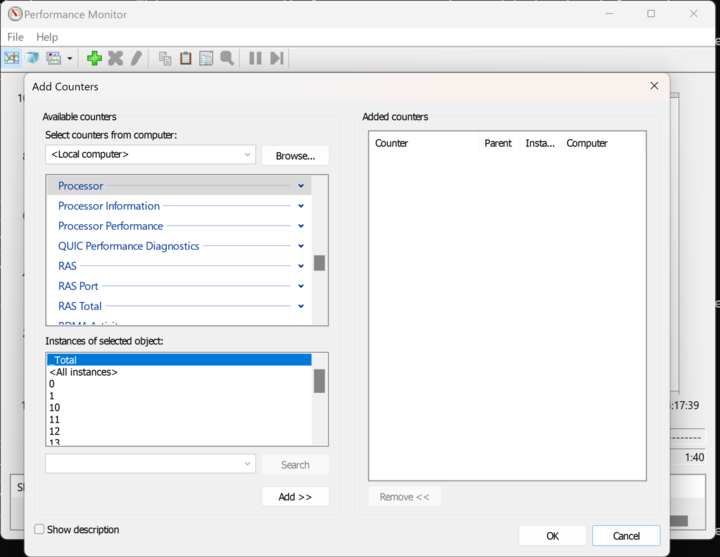
次のことに注意してください:
起動時に特定のパフォーマンスカウンターにアクセスできない場合、レシーバーは警告を発し、実行を続行します。
OSの設定が異なるため、システムによってはパフォーマンスカウンターが存在しない場合があります。
高度な設定 🔗
収集間隔とカウンターを設定する 🔗
収集間隔とスクレイピングするパフォーマンス・カウンターを設定できます。例:
windowsperfcounters:
collection_interval: <duration>
initial_delay: <duration>
metrics:
<metric name 1>:
description: <description>
unit: <unit type>
gauge: null
<metric name 2>:
description: <description>
unit: <unit type>
sum: null
aggregation: <cumulative or delta>
monotonic: <true or false>
perfcounters:
- object: <object name>
instances:
- <instance name>
counters:
- name: <counter name>
metric: <metric name>
attributes:
<key>: <value>
異なる収集間隔でスクレイプする 🔗
以下の例は、ターゲットによって異なる収集間隔を使用してパフォーマンス・カウンターをスクレイピングする方法を示しています:
receivers:
windowsperfcounters/memory:
metrics:
bytes.committed:
description: Number of bytes committed to memory
unit: By
gauge:
collection_interval: 30s
perfcounters:
- object: Memory
counters:
- name: Committed Bytes
metric: bytes.committed
windowsperfcounters/processor:
collection_interval: 1m
metrics:
processor.time:
description: CPU active and idle time
unit: "%"
gauge:
perfcounters:
- object: "Processor"
instances: "*"
counters:
- name: "% Processor Time"
metric: processor.time
attributes:
state: active
- object: "Processor"
instances: ["0", "1"]
counters:
- name: "% Idle Time"
metric: processor.time
attributes:
state: idle
# ...
service:
pipelines:
metrics:
receivers: [windowsperfcounters/memory, windowsperfcounters/processor]
インスタンスを設定する 🔗
インスタンスは、パフォーマンス・データを生成するあらゆるエンティティです。インスタンスは1つ以上のカウンター値を持つことができます。
レシーバーは instances フィールドを通じて以下の値をサポートします:
値 |
解釈 |
|---|---|
未指定 |
これは、カウンターにインスタンスがない場合にのみ有効な値です。 |
|
|
|
他のすべてのインスタンスの値を集約した 「合計 「インスタンス。詳しくは、インスタンスの動作と集計カウンターの合計 を参照してください。 |
|
シングルインスタンス |
|
インスタンスのセット |
|
総インスタンスを含むインスタンスのセット |
インスタンスの動作と集計カウンターの合計 🔗
_Total インスタンスのドロップを避けるには、以下の例のように、レシーバーが独自のメトリックで個別に収集するように設定します:
windowsperfcounters:
metrics:
processor.time.total:
description: Total CPU active and idle time
unit: "%"
gauge:
collection_interval: 30s
perfcounters:
- object: "Processor"
instances:
- "_Total"
counters:
- name: "% Processor Time"
metric: processor.time.total
警告
instance の値 "*" を使用する場合、カウンターが _Total 以外の値を使用する場合は、レシーバーがメトリクスをスクレイピングした後に集約する際に、ダブルカウントを避けるようにしてください。
すべてのスクレイプでクエリを再作成する 🔗
Windowsのバージョンによっては、カウンターが破損し、最初のスクレイプの後に無効なデータを返し続けることがあります。このような場合は、カウンターの設定 recreate_query を true に設定し(デフォルトは false )、スクレイプの度にPDHクエリを再作成するように受信機に指示します。これはパフォーマンスに影響する可能性がありますが、collection_interval が非常に高くない限り、重要ではありません。
クエリの再作成に失敗した場合、以前のクエリが再利用され、エラーが記録されます。
メトリクス形式を定義する 🔗
設定されたメトリクスは、レシーバーによってスクレイピングされた1つまたは複数のパフォーマンスカウンターによって使用される、単位とタイプを含むメトリクスの説明で構成されます。
特定の形式でメトリクスを報告するには、メトリクスを定義し、該当する属性とともに、対応するカウンターでそれを参照します。デフォルトでは、メトリクス名はカウンターの名前に対応します。
メトリクスは、sum または gauge のタイプが可能です。Sum メトリクスは、aggregation と monotonic フィールドをサポートします。
フィールド |
説明 |
値 |
デフォルト |
|---|---|---|---|
|
メトリクスのキーまたは名前。空でない文字列。 |
文字列 |
カウンターの名前 |
|
メトリクスまたは測定の説明 |
文字列 |
|
|
測定単位 |
文字列 |
|
|
合計メトリクスの表現 |
合計設定 |
|
|
ゲージメトリクスの表現 |
ゲージ設定 |
合計メトリクス 🔗
以下の設定は、合計メトリクスに適用されます:
フィールド |
説明 |
値 |
|---|---|---|
|
メトリクスの集計の一時性のタイプ |
|
|
メトリクス値が減少するかどうか |
|
ゲージメトリクス 🔗
gauge 設定は設定を受け付けません。上位互換性のためにオブジェクトとして指定されています。
次の例は、Memory/Committed Bytes カウンターを bytes.committed メトリクスとして出力します:
receivers:
windowsperfcounters:
metrics:
bytes.committed:
description: the number of bytes committed to memory
unit: By
gauge:
collection_interval: 30s
perfcounters:
- object: Memory
counters:
- name: Committed Bytes
metric: bytes.committed
service:
pipelines:
metrics:
receivers: [windowsperfcounters]
既知の制限 🔗
ネットワーク・インターフェイスはコンテナ内部では利用できないため、そのシナリオではオブジェクト
Network Interfaceのメトリクスは生成されません。サブプロセスがある場合は、Network Interfaceメトリクスをキャプチャします。カウンターのカテゴリ
Processは、同じプロセスの複数のインスタンスがあると信頼できません。Windows 11以降では、インスタンス名にプロセスIDが含まれるため、代わりに
Process V2を使用します。Windows 11より前のバージョンでは、インスタンス名にPIDを含めるように
Processカウンターカテゴリを設定できます。詳しくは、Microsoftのドキュメント Handling Duplicate Instance Names をご覧ください。
設定 🔗
以下の表は、Windows パフォーマンス・カウンター・レシーバーの構成オプションを示します:
トラブルシューティング 🔗
Splunk Observability Cloudをご利用のお客様で、Splunk Observability Cloudでデータを確認できない場合は、以下の方法でサポートを受けることができます。
Splunk Observability Cloudをご利用のお客様
Splunk サポートポータル でケースを送信する
Splunkサポート に連絡する
見込み客および無料トライアルユーザー様
Splunk Answers のコミュニティサポートで質問し、回答を得る
Splunk #observability ユーザーグループの Slack チャンネルに参加して、世界中の顧客、パートナー、Splunk 社員とのコミュニケーションを図る。参加するには、Get Started with Splunk Community マニュアルの チャットグループ を参照してください。